1. Tổng quan
- Các mô hình non-autogressive TTS song song trước đó, ví dụ như FastSpeech, có thể sinh mel-spectrogram nhanh hơn rõ rết so với autogressive models như Tacotron, cũng như giảm các lỗi về ngữ âm (lặp, mất từ). Tuy vậy, các nhược điểm trên được xử lý phần lớn nhờ attention map giữa text và speech.
- Các mô hình TTS song song trước thường sử dụng aligners từ bên ngoài như pre-trained autogressive TTS models (ví dụ là FastSpeech) khiến cho performance bị phụ thuộc vào chúng
=> Qua bài báo Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search, các tác giả giới thiệu mô hình GlowTTS, một flow-based generative model có thể tự học các alignment mà không cần aligners từ bên ngoài bằng thuật toán Monotonic Alignment Search
2. Normalizing Flows
GlowTTS dựa trên Normalizing Flows, một lớp các mô hình sinh biểu diễn sự biến đổi của mật độ xác suất bằng cách sử dụng phép đổi biến thông qua một chuỗi các phép biến đổi khả nghịch (sequence of invertible mappings) được tham số hóa và học từ dữ liệu để biến đổi phân bố từ phức tạp thành đơn giản giúp tính toán xác suất dễ dàng hơn
- Normalizing: qua các phép đổi biến, ta có hàm mật độ xác suất (probability density function - PDF) được chuẩn hóa
- Flows: hàm mật độ ban đầu flows (đổi biến liên tục) qua chuỗi các phép biến đổi khả nghịch
Flow-based models được huấn luyện sử dụng hàm mất mát negative-log likelihood

với là PDF, là định thức và đạo hàm là ma trận Jacobian, là kết quả biến đổi khả nghịch từ x sang z thông qua . Nhìn hình dưới cho dễ hiểu:
![]()
Hàm biến đổi cần thỏa mãn:
- Dễ tính hàm nghịch đảo ()
- Dễ tính ma trận đạo hàm Jacobian
3. Monotonic Alignment Search (MAS)
Tác giả cần tìm 1 ma trận alignment mà không sử dụng aligners từ bên ngoài, vậy làm thế nào? Họ đã giả sử A là song ánh để đảm bảo GlowTTS không lặp hoặc mất text input, và giới thiệu hàm Monotonic alignment search (MAS). MAS có nhiệm vụ tìm kiếm monotonic alignment khả dĩ nhất giữa biến tiềm ẩn (latent variable) và thống kê phân phối xác suất trước, gọi là
Gọi là giá trị log-likelihood cực đại với là thống kê phân phối xác suất trước, là biến tiềm ẩn. có thể được tính đệ quy theo và :
Ta tính tất cả giá trị đến ( là độ dài chuỗi mel-spectrogram, là độ dài chuỗi text input). Ta có thể tìm các phần tử trong bằng cách xác định giá trị lớn hơn trong mỗi phương trình trên. Do vậy, việc tìm có thể được thực hiện bằng quy hoạch động, và thực hiện quay lui ở cuối alignment. Bạn có thể nhìn hình cho dễ hiểu hơn:

4. Kiến trúc mô hình
4.1. Encoder và Duration Predictor
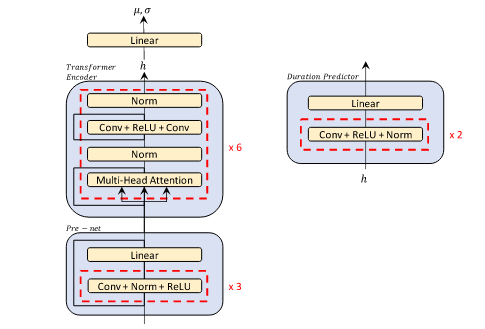
Kiến trúc phần Encoder dựa trên kiến trúc Encoder của Transformer TTS với vài thay đổi nhỏ:
- Thay thế positional encoding bởi relative position representations trong các self-attention modules
- Thêm residual connection vào encoder pre-net
- Thêm lớp linear projection vào cuối encoder nhằm ước lượng phân phối xác suất trước
Duration Predictor: kiến trúc và các tham số thiết lập đều giống với FastSpeech
4.2 Decoder
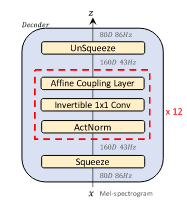
Phần cốt lõi của GlowTTS là flow-based Decoder. Decoder nhận đầu vào là mel-spectrogram, squeeze nó trước khi được xử lý qua nhiều block (mô hình trong paper gồm 12 blocks), cuối cùng được unsqueeze về hình dạng ban đầu.
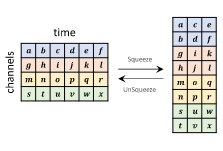
Quá trình squeeze và unsqueeze: Khi squeeze, channel size tăng gấp đôi và số lượng time step giảm 1 nửa (nếu số time step lẻ, ta bỏ qua phần tử cuối của mel-spectrogram sequence). Unsqueeze là quá trình đưa mel-spectrogram về hình dạng ban đầu
Về các block, chúng gồm:
- Activation Normalization (ActNorm) Layer: thường được sử dụng trong flow-based generative models. Nó thực hiện biến đổi affine, sử dụng các tham số scale và bias có thể huấn luyện được (tương tự batch normalization)
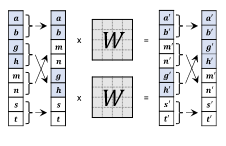
- 1x1 Convolution khả nghịch: hình dưới là ví dụ được cung cấp trong Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search. 2 phần được sử dụng cho coupling layer được tô màu trắng và xanh. Với input channel là 8 như hình, ta dùng chung 1 ma trận 4x4 như là kernel cho 1x1 convolution khả nghịch. Sau khi mix channel, ta chia input thành các nhóm rồi thực hiện phép 1x1 convolution
- Affine Coupling Layer: kiến trúc tương tự trong WaveGlow bỏ đi local conditioning
Ta có thể xem thêm về 3 thành phần trên qua bảng dưới (từ Glow: Generative Flow with Invertible 1×1 Convolutions)

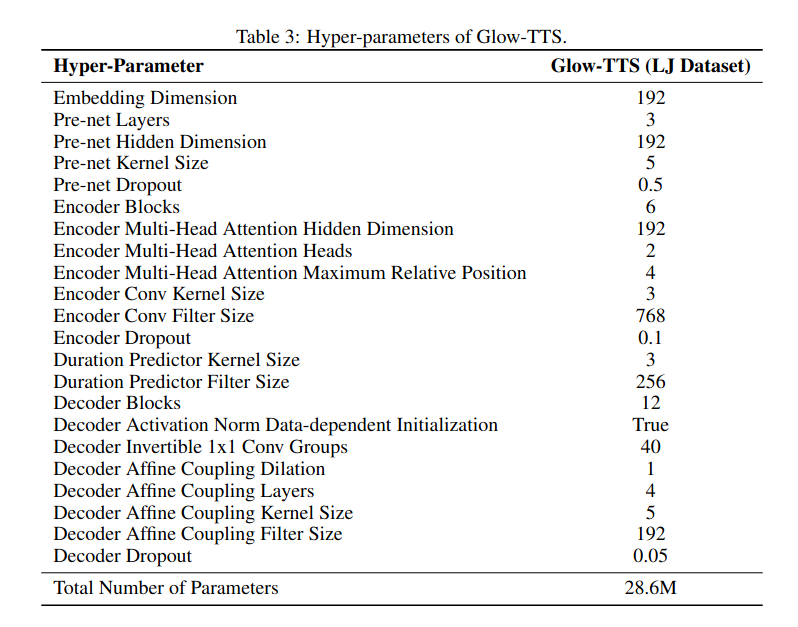
4.3. Hyperparemeters
Trái với suy nghĩ của nhiều người rằng flow-based generative models cần số lượng tham số lớn, số lượng tham số của GlowTTS (28.6 triệu) thấp hơn FastSpeech (30.1 triệu)
5. GlowTTS Pipeline
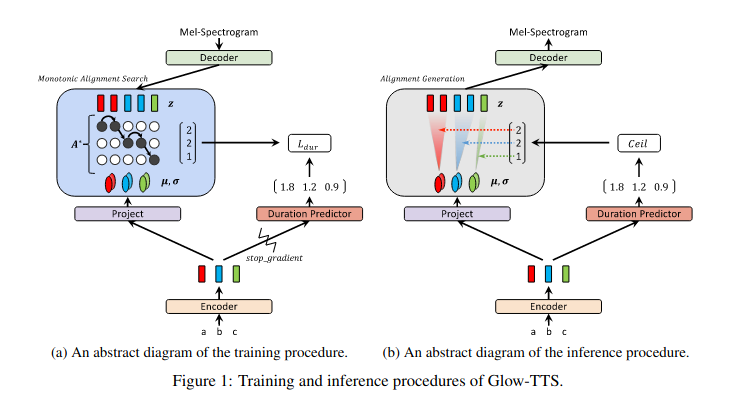
5.1. Training (hình a)
GlowTTS mô hình hóa phân phối có điều kiện của mel-spectrgram bằng cách biến đổi phân phối trước có điều kiện (conditional prior distribution) thông qua flow-based decoder , với và lần lượt là mel-spectrogram và chuỗi văn bản đầu vào. Bằng phương pháp đổi biến, ta có thể tính log-likelihood của dữ liệu:
Ta tham số hóa dữ liệu và phân phối trước bởi tham số và alignment . Text encoder ánh xạ từ text condition sang các giá trị thống kê và . Phân phối trước có thể biểu diễn theo công thức: dưới đây:
Ta cần tìm và sao cho giá trị log-likelihood của dữ liệu đạt cực đại: . Ta chia việc này thành 2 phần, thực hiện lần lượt ở mỗi traing step:
- Tìm alignment khả dĩ nhất ứng với hiện tại: sử dụng MAS đã trình bày ở trên
- Cập nhật bằng gradient descent sao cho log-likelihood là lớn nhất
Để ước lượng trong quá trình suy luận, ta huấn luyện duration predictor để có thể cho kết quả giống duration label được tính bởi :
Duration predictor có kiến trúc gần tương tự trong FastSpeech và cũng được đặt sau encoder. Điểm khác biệt là đầu vào của duration predictor có thêm phép toán stop gradient , nhằm loại bỏ đạo hàm ở đầu vào trong quá trình backward để chúng không ảnh hưởng tới maximum likelihood.
Hàm mất mát của duration predictor:
với MSE là mean square error giữa các giá trị logarithm
5.2. Inference (hình b)
Trong quá trình suy luận, phân phối trước và alignment được dự đoán bởi text encoder và duration predictor. Sau đó, biến tiềm ẩn được lấy mẫu từ phân phối trước, và mel-spectrogram được sinh song song bằng việc sử dụng flow-based decoder để biến đổi các biến tiềm ẩn.
6. Kết quả
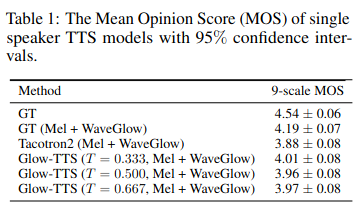
6.1. Chất lượng âm thanh
Trong 3 giá trị temperature của phân phối trước được thử nghiệm trong suy luận, GlowTTS đạt performance tốt nhất khi . Với cả 3 giá trị , MOS của GlowTTS đều nhỉnh hơn Tacotron2
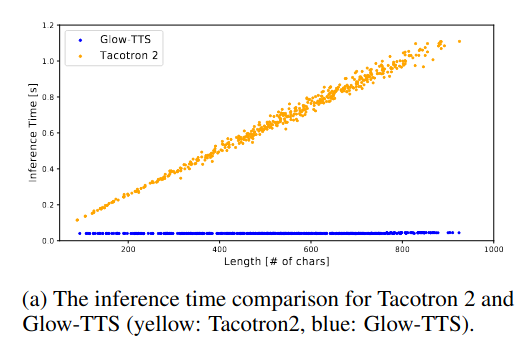
6.2. Tốc độ suy luận
Trên tập test, tốc độ suy luận của GlowTTS ổn định ở 40ms bất kể độ dài, còn tốc độ của Tacotron2 giảm dần tuyến tính khi độ dài chuỗi text input tăng dần. GlowTTS suy luận nhanh hơn trung bình 15.6 lần so với Tacotron2
6.3. Robustness
- Tỉ lệ ký tự lỗi (character error rate - CER) của Tacotron2 bắt đầu tăng khi độ dài chuỗi ký tự đầu vào vượt quá 260, còn GlowTTS vẫn ổn định với văn bản dài dù chúng không được sử dụng trong quá trình huấn luyện
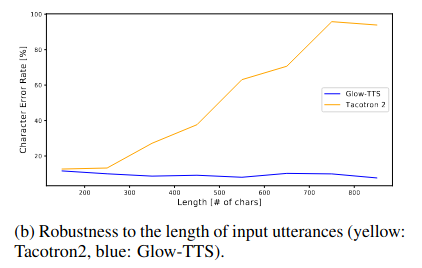
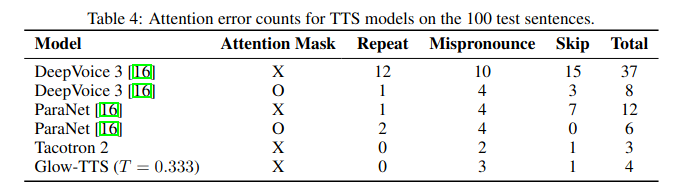
- Tỷ lệ các lỗi về ngữ điệu (lặp, mất từ, phát âm sai) cũng rất thấp khi so sánh với nhiều TTS model khác. Dù tệ hơn Tacotron2, robustness của GlowTTS vẫn được giữ vững với chuỗi text input độ dài lớn, điều mà Tacotron2 không làm được
Reference
Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Glow: Generative Flow with Invertible 1×1 Convolutions

