Chào mọi người, dạo gần đây mình bắt đầu tìm hiểu và ứng dụng một phương pháp tiếp cận khá thú vị trong học máy. Nên mình cũng muốn chia sẽ một số kiến thức mà mình nghĩ là sẽ hữu ích với những bạn đang học tập và làm việc trong lĩnh vực AI/ML/DL nói chung cũng như đó là động lực để mình có thể tạo ra thêm nhiều những bài viết chất lượng hơn. Quay lại chủ đề chính, có bao giờ các bạn từng triển khai các bài toán mà tập dữ liệu không nhãn rất nhiều nhưng dữ liệu có nhãn thì khá là hạn chế và việc đánh nhãn cho dữ liệu mất rất nhiều công sức, chi phí, thời gian.... Trong thực tế chúng ta thường sẽ phải tiếp cận với những bài toán như vậy, việc đánh nhãn cho dữ liệu thường mất rất nhiều nguồn lực và thông tin từ dữ liệu chưa được gắn nhãn thì không được tận dụng triệt để. Bài viết hôm nay chúng ta sẽ cùng tìm hiểu về self-supervised learning (học tự giám sát) một phương thức tiếp cận về việc tận dụng thông tin của dữ liệu một cách hiệu quả nhất đồng thời có thể cải thiện hiệu quả của bài toán một cách đáng kể.
Self-Supervised learning là gì
Supervised Learning, Unsupervised Learning
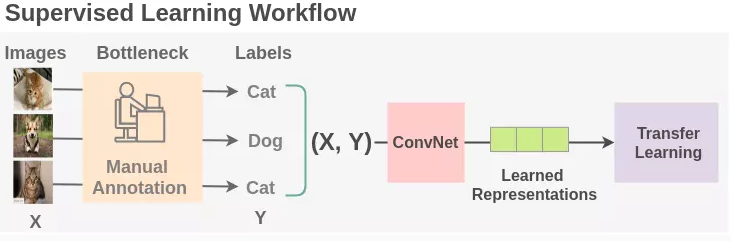
Supervised Learning (Học có giám sát) là các thuật toán sử dụng dữ liệu đã được gán nhãn để mô hình hóa mối quan hệ giữa dữ liệu đầu vào và nhãn của chúng. Học có giám sát yêu cầu rất cao về dữ liệu gán nhãn thường các tập dữ liệu sẽ phải được gán nhãn bởi con người, một số tập dữ liệu yêu cầu độ chính xác cao và mức độ quan trọng thì thường mất rất nhiều nguồn lực, hỡn nữa các bộ dữ liệu được gán nhãn chưa chắc đã thực sự bao quát và phù hợp.
Unsupervised Learning (Học không giám sát) là các thuật toán sử dụng dữ liệu không có nhãn. Các thuật toán này thường hướng đến việc mô hình hóa được cấu trúc hay thông tin ẩn trong dữ liệu, qua đó mô tả đặc tính cũng như tính chất của tập dữ liệu. Các phương pháp này thường được sử dụng trong quá trình́ phân tích, trực quan hóa dữ liệu
Rõ ràng việc tạo ra một tập dữ liệu tốt với đầy đủ nhãn là rất tốn kém nhưng dữ liệu không có nhãn luôn được tạo ra . Để tận dụng lượng dữ liệu không được gắn nhãn lớn hơn rất nhiều này, một phương pháp tiếp cận để có thể học được những đặc trưng chính từ bên trong của dữ liệu. Việc mô hình có thể học được những đặc trưng chính từ bên trong dữ liệu có thể được sử dụng để cải thiện mô hình của một số tác vụ trên tập dữ liệu đó và các phương pháp tiếp cận như vậy thường được biết đên với bài toán Sefl-Supervised learning.
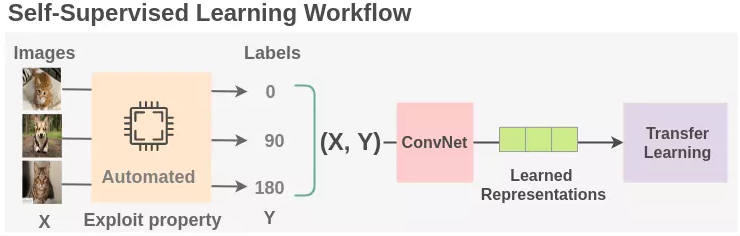
Vậy self-supervised learning(học tự giám sát) là gì ?
Học tự giám sát là một quá trình học máy trong đó mô hình tự đào tạo để học được đặc trưng bên trong của dữ liệu. Trong quá trình này, các bài toán học máy không được giám sát được chuyển thành bài toán học máy giám sát bằng cách tự động tạo nhãn. Để tận dụng số lượng lớn dữ liệu không được gắn nhãn, điều quan trọng là phải đặt ra các mục tiêu học tập phù hợp để có mô hình có thể học được những đặc trưng từ chính dữ liệu đó.
Tư tưởng của bài toán self-supervised learning
Các mô hình self-supervised sau khi được đào tạo sẽ được sử dụng để finetune (sử dụng tham số của mô hình đã được huấn luyện cho tác vụ của bài toán self-supervised cho mô hình của tác vụ chính) cho các downstream tasks (các tác vụ mà mô hình muốn học) khiến cho các mô hình robust hơn, qua đó tăng performace của mô hình. Ví dụ chúng ta sẽ sử dụng tham số một backbone được học từ dữ liệu không được gắn nhãn (ảnh xe, nhà, mèo ...) thông quan quá trình huấn luyện một mô hình self-supervised để huấn luyện mô hình phân loại chính.
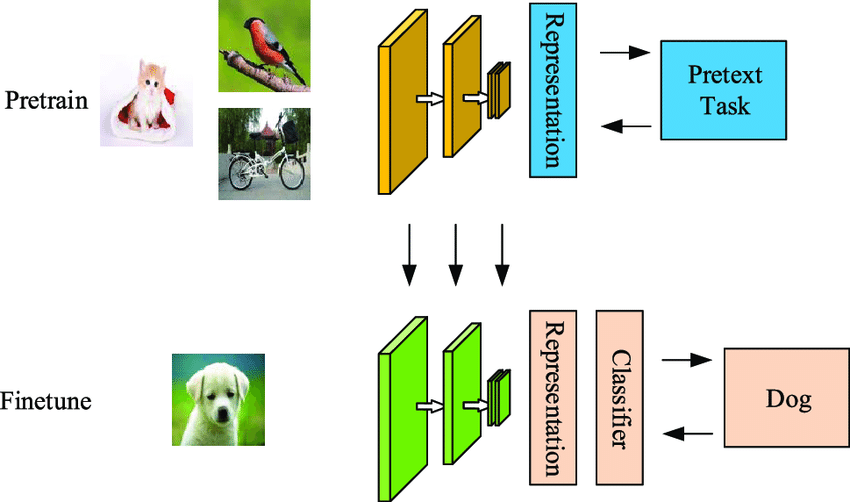
Một số hướng tiếp cận phổ biến trong self-supervised learning
Contrastive Learning
Mục tiêu của constrastive learning là học được một không gian nhúng (embedded space) trong đó các cặp mẫu tương tự nhau sẽ ở gần nhau còn các cặp mẫu khác nhau ở xa nhau. Các tác vụ của học tự giám sát được gọi các tác vụ giả định (pretext task) nhằm mục đích tự động tạo các nhãn giả. Có rất nhiều cách khác nhau để tự động tạo ra các tác vụ giả định ví dụ như trong hình ảnh sẽ có một số phương pháp như:
- Thay đổi màu sắc
- Xoay và cắt ảnh
- Các phép biển đổi hình học khác
Có rất nhiều phương pháp và kỹ thuật mới để tiến hành việc huấn luyện kết hợp giữa self-supervised và contrastive learning. Ba thành phần quan trọng nhất của các kỹ thuật này là làm thế nào để chúng ta định nghĩa và xây dựng được pretext tasks, backbone, and contrastive loss. MÌnh đã tìm hiểu nhiều nghiên cứu để tìm xung quanh chủ đề này và thấy rằng việc tối ưu sự kết hợp này cũng đang là một trong những xu hướng nghiên cứu phổ biến hiện nay. Một số nghiên cứu phổ biến trong chủ đề này như.
SimCLR (A Simple Framework for Contrastive Learning of Visual Representations)
 Dựa trên SimCLR framework có thể thấy pretext tasks được định nghĩa dựa trên các phương pháp data augmentation (tăng cường dữ liệu), mô hình sẽ tạo ra những feature tương ứng cho từng mẫu. Một hàm mất mát được thiết kế dựa trên constrastive learning để tối ưu khoảng cách giữa các feature (các mẫu giống nhau sẽ gần nhau hơn và các mẫu khác nhau sẽ xa nhau ra). Tham số được mô hình học được sẽ được finetune lại cho downstream tasks.
Dựa trên SimCLR framework có thể thấy pretext tasks được định nghĩa dựa trên các phương pháp data augmentation (tăng cường dữ liệu), mô hình sẽ tạo ra những feature tương ứng cho từng mẫu. Một hàm mất mát được thiết kế dựa trên constrastive learning để tối ưu khoảng cách giữa các feature (các mẫu giống nhau sẽ gần nhau hơn và các mẫu khác nhau sẽ xa nhau ra). Tham số được mô hình học được sẽ được finetune lại cho downstream tasks.
- paper: SimCLR
SwAV ( Sw apping A ssignments between many V iews)
Một bài báo năm 2020 đã đề xuất mô hình SwAV ( Sw apping A ssignments between many V iews), đây là một phương pháp để so sánh các phép gán cụm để đối chiếu các chế độ xem hình ảnh khác nhau và không dựa trên việc so sánh feature giữa các hình ảnh. Mục tiêu của phương pháp này là tìm hiểu các đặc điểm hình ảnh theo cách trực tuyến mà không cần giám sát. Do đó, các tác giả đề xuất một phương pháp học tự giám sát dựa trên phân cụm trực tuyến hay chúng ta có thể gọi là Contrasting Cluster Assignments.
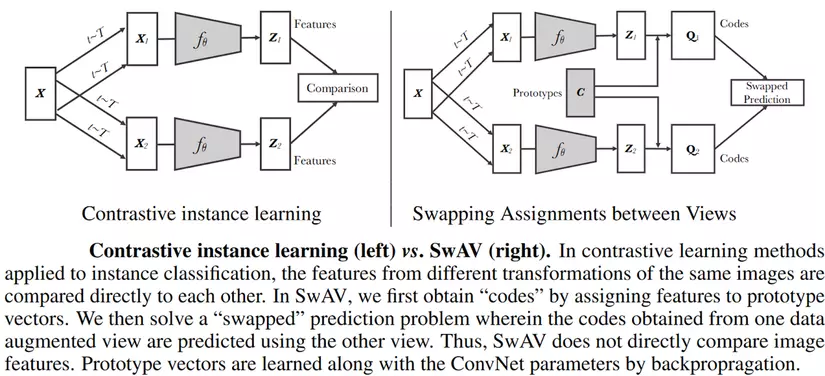
- paper: SwAV
Non-Contrastive Learning
Khác với contrastive learning thì Non-Contrastive Self Supervised Learning (NC-SSL) huấn luyện một mô hình học máy trong đó chỉ các cặp positive sample được sử dụng để đào tạo một mô hình. Ý tưởng này có vẻ không có gì hợp lý, vì mô hình chỉ tập chung giảm thiểu khoảng cách giữa các cặp dữ liệu positive. Tuy nhiên, NC-SSL đã cho thấy nó có thể học cách biểu diễn không hề tệ khi chỉ sử dụng các mẫu positive kết hợp với một số phướng pháp extra predictor và stop-gradient operation. Hơn nữa, biểu diễn đã học cho thấy hiệu suất có thể so sánh được (hoặc thậm chí tốt hơn) cho downstrem tasks. Các bạn có thể tham khảo thêm nghiên cứu này ở đây nhé: Non-Contrastive Learning
Contrastive Predictive Coding (CPC)
Ý tưởng trung tâm của Contrastive Predictive Coding trước tiên là chia toàn bộ hình ảnh thành một lưới ảnh và cho biết thông tin các hàng phía trên của hình ảnh, nhiệm vụ là dự đoán các hàng phía dưới của cùng một hình ảnh. Để thực hiện được tác vụ này, mô hình phải tìm hiểu cấu trúc của đối tượng trong hình ảnh ( ví dụ như nhìn thấy khuôn mặt của một con chó, mô hình phải dự đoán rằng nó sẽ có 4 chân ). Việc mô hình được huấn luyện như thế này sẽ có tác dụng rất lớn tới downstream task.
 Các bạn có thể tham khảo cách ý tưởng cụ thể và cách triển khai của bài báo này kỹ hơn ở đây nhé: Contrastive Predictive Coding (CPC)
Các bạn có thể tham khảo cách ý tưởng cụ thể và cách triển khai của bài báo này kỹ hơn ở đây nhé: Contrastive Predictive Coding (CPC)
Ứng dụng của self-supervised learning
Với khả năng học tập trên các tập dữ liệu không được gắn nhãn, self-supervised learning được ứng dụng rộng rãi cho nhiều bài toán với lượng lớn dữ liệu không có nhãn như bài toán về voice recognition, signature detection ...
Kết luận
Những năm gần đây hướng tiếp cận về việc khai thác thông tin dữ liệu không được gán nhãn đang là xu hướng hướng nghiên cứu rất được quan tâm với nhiều những phương pháp như self-supervised learning, semi-supervised learning, active learning ... đã và đang đem lại hiệu quả trong lĩnh vực AI. Self-supervised learning đang là một phương pháp phổ biến dể triển khai và ứng dụng trong nhiều bài toán và mạng lại hiệu quả đáng kinh ngạc, nhất là trong các bài toán đặc thù về dữ liệu (bài toán dữ liệu y sinh, dữ liệu về con người...). Trong bài viết tiếp theo mình sẽ trình bày tiếp về các bài toán trong semi-supervised learning cũng là một phương pháp khai thác thông tin dữ liệu không được gắn nhãn, mong mọi người đón đọc.