3. FastSpeech 2
3.1 Giới thiệu
1 số mô hình non-autoregressive TTS như FastSpeech có khả năng sinh giọng nói nhanh hơn các mô hình autoregressive với độ chính xác tương đương. Việc huấn luyện mô hình FastSpeech phụ thuộc vào autoregressive teacher model để dự đoán thời lượng âm vị và knowledge distillation (chắt lọc tri thức), có thể giải quyết tốt các vấn đề one-to-many (1 văn bản có thể sinh ra nhiều giọng nói khác nhau).Tuy nhiên, FastSpeech có các nhược điểm sau:
- Pipeline teacher-student distillation khá phức tạp và tốn thời gian.
- Thời lượng được trích xuất từ teacher model không đủ độ chính xác, và target mel-spectrogram được chắt lọc từ teacher model thiếu thông tin do dữ liệu đơn giản, cả 2 điều này làm giảm chất lượng giọng nói.
Trong bài này, chúng ta cùng tìm hiểu về 1 kiến trúc mới có tên là FastSpeech 2 với bài báo FASTSPEECH 2: FAST AND HIGH-QUALITY END-TO-END TEXT TO SPEECH được Microsoft ra mắt vào năm 2021. FastSpeech 2 đã giải quyết 1 số vấn đề của người tiền nhiệm như sau:
- training model trực tiếp với ground-truth target thay vì dữ liệu sinh ra từ teacher model.
- thêm vào nhiều sự đa dạng thông tin của giọng nói như pitch (cao độ), energy (năng lượng) và thời lượng (duration) chính xác hơn, được xem như là điều kiện đầu vào. Nói cách khác, chúng ta trích xuất duration, pitch, energy từ waveform và coi nó như là điều kiện đầu vào để training và dự đoán các giá trị mới trong quá trình inference.
Tác giả cũng giới thiệu thêm về FastSpeech 2s, mô hình sinh ra speech waveform trực tiếp từ văn bản 1 cách song song. Kết quả thực nghiệm cho thấy rằng:
- FastSpeech 2 huấn luyện nhanh gấp 3 lần so với FastSpeech, và FastSpeech 2s thậm chí còn nhanh hơn nhờ vào sinh waveform trực tiếp.
- Cả FastSpeech 2 và FastSpeech 2s đều đạt kết quả tốt hơn FastSpeech về chất lượng giọng nói, và mô hình FastSpeech 2 thậm chí có thể vượt qua các autoregressive model.
3.2 Kiến trúc mô hình
a) Tổng quan mô hình
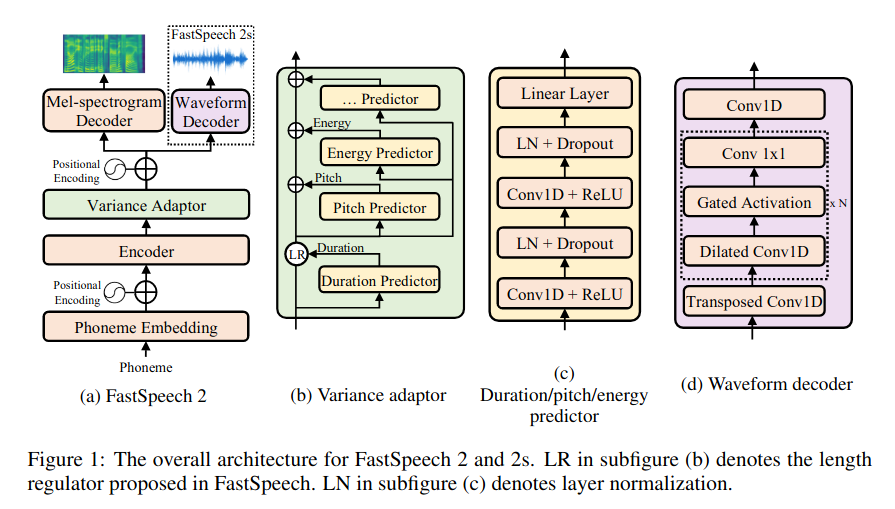
Đầu vào là chuỗi âm vị được cho đi qua 1 lớp embedding, kết hợp với lớp positional encoding để xác định vị trí của phoneme trong câu. Mạng Encoder chuyển đổi phoneme embedding sequence thành chuỗi âm vị ẩn. Sau đó Variance Adaptor thêm vào các thông tin của âm thanh như duration, pitch, energy vào chuỗi ẩn. Cuối cùng mạng Decoder chuyển song song từ các chuỗi ẩn thành các chuỗi mel-spectrogram. Trong bài báo sử dụng khối Feed-Forward Transformer (FFT) bao gồm các lớp self-attention được stack lại với nhau và lớp 1D convolution đã được đề cập trong phần trước . Đây là kiến trúc nền tảng cho cả Encoder và mel-spectrogram Decoder. Ngoài ra, FastSpeech 2 còn bổ sung thêm:
- Loại bỏ pipeline teacher-student distillation, huấn luyện trực tiếp bằng ground-truth mel-spectrogram, giúp tránh mất mát thông tin và tăng chất lượng giọng nói.
- Sử dụng khối Variance Adaptor bao gồm duration, pitch và energy predictor. Cụ thể hơn, duration predictor sử dụng thời lượng âm vị (phoneme duration) thu được từ forced alignment, cái này chính xác hơn phoneme duration được trích xuất từ attention map của autoregressive teacher model. Các pitch và energy predictor được thêm vào cung cấp thêm nhiều thông tin hữu ích cho bài toán one-to-many TTS.
b) Variance Adaptor
Variance adaptor thêm vào các trường thông tin (duration, pitch, energy) vào chuỗi âm vị ẩn thu được sau khi đi qua lớp Encoder, cung cấp nhiều thông tin để giúp model có thể dự đoán giọng nói đầu ra 1 cách đa dạng hơn.
Một số trường thông tin dữ liệu được variance adaptor thêm vào:
- phoneme duration: biểu diễn thời lượng độ dài phát âm của âm vị.
- pitch: đặc trưng chính cho việc truyền tải cảm xúc, ảnh hưởng trực tiếp đến ngữ điệu giọng nói.
- energy: biểu diễn biên độ của mel-spectrogram, ảnh hưởng đến độ to/nhỏ của giọng nói.
Tương ứng, các thành phần trong khối variance adaptor:
- duration predictor: dự đoán thời lượng của chuỗi âm vị, tương tự như trong FastSpeech (các bạn có thể tham khảo bài trước của mình để hiểu rõ hơn).
- pitch predictor: dự đoán độ cao của chuỗi âm vị.
- energy predictor: dự đoán độ to/nhỏ của chuỗi âm vị.
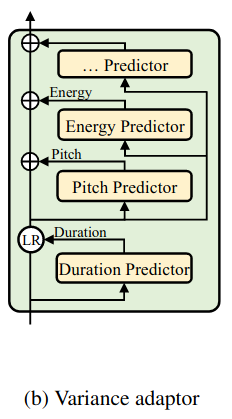
Trong quá trình training, model thực hiện 2 nhiệm vụ song song:
- Lấy các giá trị ground-truth duration, pitch và energy (trích xuất từ bản ghi đầu vào) đưa vào chuỗi ẩn để huấn luyện cho các mạng khác.
- Sử dụng các giá trị ground-truth duration, pitch và energy ở trên để huấn luyện các duration, pitch, energy predictor, dùng để suy luận giọng nói (inference target speech).
Các mạng duration, pitch và energy predictor có phần kiến trúc mô hình tương tự nhau (nhưng khác nhau về các tham số), bao gồm 2 lớp 1D convolution kết hợp cùng hàm ReLU, theo sau bởi layer normalization và dropout. Cuối cùng thêm vào 1 lớp tuyến tính để chuyển chuỗi ẩn thành chuỗi đầu ra.
Duration Predictor
Bộ dự đoán thời lượng âm vị có đầu vào là chuỗi âm vị ẩn, output là thời lượng của mỗi âm vị, biểu diễn có bao nhiêu mel frame tương ứng với âm vị này, và sau đó chuyển sang miền logarith để tiện cho việc tính toán. Bài báo sử dụng hàm MSE để tối ưu với duration được trích xuất từ bản ghi là training target. Khác với FastSpeech khi sử dụng mô hình pre-trained autoregressive TTS, tác giả sử dụng Montreal forced alignment (MFA) để trích xuất ra phoneme duration, qua đó cho kết quả chính xác hơn.
Pitch Predictor
Các mô hình TTS dựa trên neural network được sử dụng trước đó dự đoán pitch contour (đường viền cao độ) 1 cách trực tiếp. Tuy nhiên, do độ phương sai cao, phân phối của giá trị pitch dự đoán lệch rất nhiều so với phân phối pitch ground-truth. Để cải thiện phương sai của pitch contour, tác giả sử dụng continuous wavelet transform (CWT) để phân tách chuỗi cao độ liên tục thành chuỗi cao độ spectrogram, sau đó lấy pitch spectrogram làm đầu vào cho quá trình huấn luyện pitch predictor, với hàm tối ưu là MSE loss. Trong quá trình inference, pitch predictor dự đoán pitch spectrogram, sau đó có thể được chuyển ngược lại thành pitch contour sử dụng inverse continuous wavelet transform (iCWT). Cụ thể như sau:
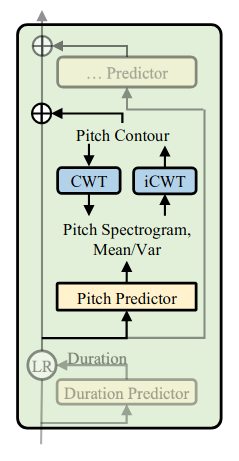
Đầu tiên ta trích xuất pitch contour sử dụng PyWordVocoder. Vì CWT rất nhạy cảm với tín hiệu không liên tục, nên chúng ta tiền xử lý pitch contour như sau:
- sử dụng nội suy tuyến tính (linear interpolation) để lấp đầy vào các unvoiced frame trong pitch contour.
- chuyển đổi giá trị pitch contour vừa thu được ở trên về logarith scale.
- chuẩn hóa về phân phối chuẩn Gauss , sau đó lưu lại các giá trị trên để có thể khôi phục lại thành pitch contour ban đầu.
Convert pitch contour đã được chuẩn hóa thành pitch spectrogram bằng CWT:
với là Mexican hat mother wavelet, là giá trị pitch ở vị trí x, và t lần lượt là scale và vị trí của wavelet. Pitch contour ban đầu có thể được khôi phục lại từ biểu diễn wavelet bằng công thức iCWT:
Giả sử rằng ta tách pitch contour thành 10 scale, có thể được biểu diễn bởi 10 thành phần riêng rẽ cho bởi:
với i = 1,...,10 và . Với 10 thành phần wavelet , ta có thể kết hợp lại tạo thành bằng công thức sau:
Đoạn này mình cũng không hiểu lắm, các bạn có thể tham khảo thêm ở đây:
- https://www.isca-speech.org/archive_v0/ssw8/papers/ssw8_285.pdf
- https://www.researchgate.net/publication/307889499_Deep_Bidirectional_LSTM_Modeling_of_Timbre_and_Prosody_for_Emotional_Voice_Conversion
Để đưa pitch contour làm 1 phần đầu vào trong quá trình huấn luyện và suy luận, ta lượng tử hóa (quantize) ở mỗi vị trí thành 256 giá trị theo logarithm rồi chuyển đổi thành pitch embedding vector p và thêm vào chuỗi ẩn.
Energy Predictor
Energy được tính bằng L2-norm của biên độ mỗi short-time Fourier transform (STFT) frame. Sau đó chúng ta quantize mỗi frame thành 256 giá trị, mã hóa nó thành energy embedding e và thêm nó vào để mở rộng chuỗi ẩn, tương tự như pitch. Energy predictor được sử dụng để dự đoán các giá trị ban đầu của năng lượng thay vì các giá trị đã được lượng tử hóa, và sử dụng hàm loss MSE để tối ưu.
c) FastSpeech 2s
FastSpeech 2s sinh trực tiếp waveform từ văn bản, bỏ qua bước sinh mel-spectrogram (acoustic model) và sinh waveform (vocoder). Nó sinh waveform dựa vào các tầng trung gian ẩn, giúp nó compac (mình không biết dịch từ này như thế nào) hơn và đạt được accuracy tương đối tốt.
Có 1 vài thách thức khi sinh waveform trực tiếp từ văn bản:
- Bởi vì waveform chứa nhiều thông tin biến động (ví dụ như pha) hơn là mel-spectrogram, khi đó khoảng chênh lệch thông tin giữa input và output là lớn hơn rất nhiều so với văn bản và spectrogram.
- Do giới hạn bộ nhớ GPU và 1 số mẫu waveform rất dài, nên rất khó để train ở audio clip ứng với toàn bộ văn bản. Do đó, ta chỉ có thể train ở audio clip ngắn ứng với 1 đoạn văn bản, điều này làm cho model khó giữ được mối quan hệ giữa các âm vị với nhau ở trong các đoạn văn bản khác nhau, làm ảnh hưởng đến quá trình trích xuất đặc trưng văn bản.
Nhóm tác giả đã đề xuất 1 số cải tiến như sau:
- Sử dụng adversarial training (đề cập trong Parallel Wavegan) trong waveform decoder để buộc nó tự khôi phục lại thông tin về pha.
- Tận dụng mel-spectrogram decoder của FastSpeech2, được huấn luyện trên chuỗi văn bản đầy đủ nhằm trích xuất đặc trưng văn bản
3.3 Kết quả
Audio Quality: MOS của FastSpeech2 cao hơn và MOS của FastSpeech2s tương đương với Tacotron2 và Transformer TTS. Đặc biệt, FastSpeech2 vượt trội hơn hẳn FastSpeech.
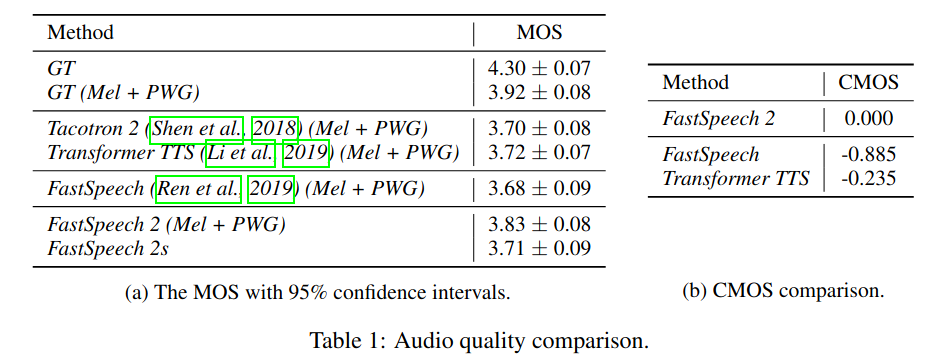
Training and Inference Speedup: do loại bỏ teacher-student distillation pipeline nên FastSpeech2 có thời gian huấn luyện nhanh hơn 3.12 lần so với FastSpeech. Ta không so sánh thời gian huấn luyện của FastSpeech2s, vì bảng trên chỉ bao gồm thời gian huấn luyện acoustic model, không tính thời gian huấn luyện vocoder. Tốc độ suy luận của FastSpeech tuy nhanh hơn FastSpeech2 một chút nhưng vẫn chậm hơn FastSpeech2s - đương nhiên cả 3 đều nhanh hơn rất nhiều so với Transformer TTS.