Ở phần 1 chuỗi series về Fast Speech, bài viết Bộ đôi anh em nhà Fast Speech: Ông vua mới kế vị Tacotron ? mình đã giới thiệu sơ lược một số kiến trúc Text to Speech để chúng ta có thể nhìn rõ được những ưu và nhược điểm của mô hình này. Trong bài viết hôm nay, chúng ta cùng nhau phân tích đặc điểm rõ hơn những module, kiến trúc tạo nên ưu thế khác biệt cho mô hình.
Ở bài viết trước, chúng ta có đề cập đến ba nhược điểm của mô hình autogressive:
- Tốc độ sinh mel-spectrogram chậm
- Âm thanh sinh ra gặp hiện tượng mất hoặc lặp từ
- Âm thanh sinh ra không thể điều khiển trường âm hay ngắt nghỉ trong câu.
Để giải quyết các vấn đề tồn đọng trong các mô hình Autogressive, Fast Speech đã đề xuất 3 modules:
-
Feed-Forward Transformer: giúp sinh mel-spectrogram song song thay vì sinh mel-spectrogram một cách tuần tự như các mô hình Autogressive
-
Phoneme duration predictor: đảm bảo hard alignment giữa phoneme và mel spectrogram tương ứng, giúp giải quyết vấn đề wrong attention alignment giữa text và spectrogram đang gặp khi sử dụng soft alignment hiện nay trong các mô hình Autogressive giảm thiểu số lượng từ bị bỏ qua và lặp lại.
-
Length regulator: giúp điều chỉnh độ dài ngắn của trường âm thông qua đó xác định độ dài mel-spectrogram. Điều này có hai ý nghĩa:
- Xác định độ dài mel-spectrogram được sinh ra thông qua trường âm tăng độ chính xác alignment giữa phone và spectrogram
- Điều chỉnh được nhịp điệu của giọng nói.
 (a) The feed-forward transformer. (b) The feed-forward transformer block. (c) The length regulator (d) The duration predictor.
(a) The feed-forward transformer. (b) The feed-forward transformer block. (c) The length regulator (d) The duration predictor.
I. Các modules trong Fast Speech
1. Feed-Foward Transformer
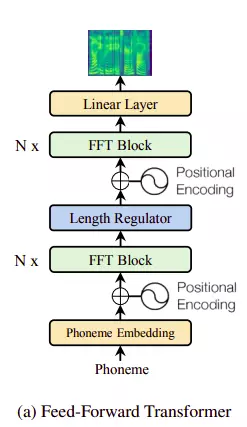
Có cái tên Feed-Forward Transformer (FFT) bởi vì đây kiến trúc dạng feed forward và có nhiều block tương tự như Transformer. Như hình vẽ bên trên các bạn có thể thấy, FFT gồm có hai phần tương tự như kiến trúc Transformer gọi là:
- Mel spectrogram side
- Phoneme side
Mỗi bên gồm có N modules FFT Block. Riêng phần phoneme side có thêm module length regulator để làm cấu nối thông tin giữa phonemes và spectrogram. Lý do bởi vì một phoneme có thể tương ứng với nhiều mel spectrogram do đó length regulator giúp chúng ta tạo thêm các phoneme "giả" để tương ứng với spectrogram cho mô hình học alignment tốt hơn. Chúng ta sẽ đề cập kĩ hơn cách hoạt động của length regulator ở bên dưới.
2. Length Regulator
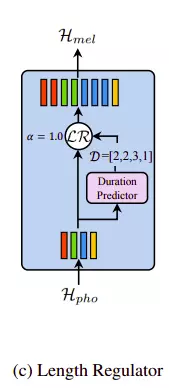
Như đã đề cập bên trên, Length regulator giải quyết vấn đề một phone nhưng tương ứng với nhiều spectrogram. Song song đó, tác giả nhận ra độ dài duration của phone tương ứng độ dài của mel spectrogram do đó tác giả đã quy bài toán này về dự đoán duration của phone bằng modules phoneme duration predictor mà chúng ta sẽ đề cập đến ở phần sau.
Ở đây chúng ta giả sử ta có kết quả dự đoán của module phoneme duration predictor là
D = [d1, d2, d3, d4, ..., dn]
# n là độ dài chuỗi phoneme H = [h1, h2, h3, h4, ..., hn]
chú ý một chút , trong đó m là chiều dài chuỗi mel-spectrogram. Ta sẽ có hàm length regulator hoạt động như sâu:
trong đó là tham số điều chỉnh kéo dài hay thu ngắn lại giúp điều chỉnh tốc độ âm thanh tùy ý
Ví dụ ta có:
Chuỗi phoneme:
Chuỗi duration dự đoán:
Tham số điều chỉnh
Ta sẽ có kết quả sau khi đi qua hàm Length regulator:
3. Duration predictor
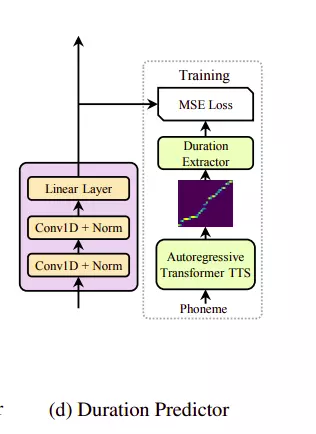
Như đã giải thích trong phần 2, để giải quyết vấn đề mismatch alignment giữa phoneme và mel spectrogram do độ dài bất tương xứng ta cần đến Length regulator. Và để hàm Length regulator hoạt động, chúng cần đến kết quả dự đoán của module Duration predictor.
Kiến trúc module Duration predictor tương đối đơn giản gồm 2 lớp convolution 1D kết hợp hàm Relu activation. Theo sao là layer normalization và lớp drop out. Cuối cùng là một lớp Linear để cho output là một số
class VariancePredictor(nn.Module):
"""Duration, Pitch and Energy Predictor"""
def __init__(self, model_config):
super(VariancePredictor, self).__init__()
self.input_size = model_config["transformer"]["encoder_hidden"]
self.filter_size = model_config["variance_predictor"]["filter_size"]
self.kernel = model_config["variance_predictor"]["kernel_size"]
self.conv_output_size = model_config["variance_predictor"]["filter_size"]
self.dropout = model_config["variance_predictor"]["dropout"]
self.conv_layer = nn.Sequential(
OrderedDict(
[
(
"conv1d_1",
Conv(
self.input_size,
self.filter_size,
kernel_size=self.kernel,
padding=(self.kernel - 1) // 2,
),
),
("relu_1", nn.ReLU()),
("layer_norm_1", nn.LayerNorm(self.filter_size)),
("dropout_1", nn.Dropout(self.dropout)),
(
"conv1d_2",
Conv(
self.filter_size,
self.filter_size,
kernel_size=self.kernel,
padding=1,
),
),
("relu_2", nn.ReLU()),
("layer_norm_2", nn.LayerNorm(self.filter_size)),
("dropout_2", nn.Dropout(self.dropout)),
]
)
)
self.linear_layer = nn.Linear(self.conv_output_size, 1)
def forward(self, encoder_output, mask):
out = self.conv_layer(encoder_output)
out = self.linear_layer(out)
out = out.squeeze(-1)
if mask is not None:
out = out.masked_fill(mask, 0.0)
return out
Chú ý một chút về cách huấn luyện duration predictor ở đây sẽ khác nhau giữa các mô hình Fast Speech và Fast Speech 2. Ở mô hình Fast Speech, cách thực hiện như sau:
- Huấn luyện mô hình Autogressive encoder-attention-decoder based Transformer TTS
- Với mỗi cặp dữ liệu, tác giả sẽ trích xuất được các decoder-to-encoder attention alignment từ mô hình đã được huấn luyện bên trên. Tác giả có một giả thuyết (cái này mình cũng không hiểu lắm) diagonal alignment sẽ tốt và xây dựng một chỉ số đánh giá là focus rate trong đó S và T lần lượt là chiều dài của ground truth spectrogram và phones. Tác giả sẽ chọn attention alignment nào có giá trị F lớn nhất
- Cuối cùng, chúng ta sẽ lấy được chuỗi phoneme duration trong đó
II. Kết quả
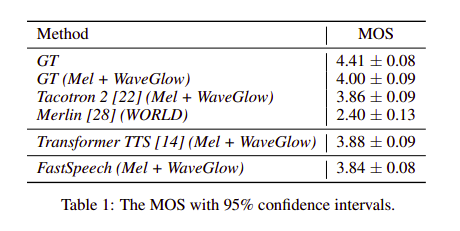
Audio Quality: Fast Speech đạt kết quả dựa trên thang điểm MOS xấp xỉ với các phương pháp như Tacotron 2 hay Transformer TTS model.
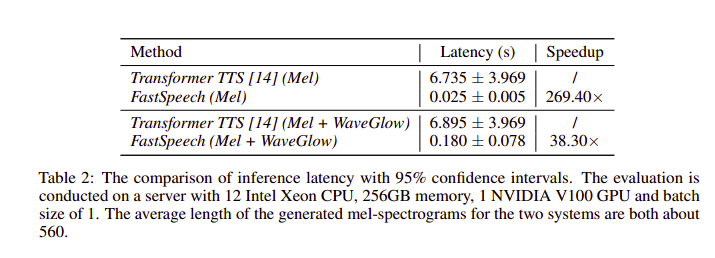
Infence Speedup: Tốc độ sinh mel-spectrogram của Fast Speech nhanh gấp 269.4 lần so với mô hình Transformer TTS
Robustness: Fast Speech hạn chế được các lỗi lặp hoặc mất từ hay gặp ở các mô hình autogressive.
 Length Control: Fast Speech có thể điều khiển tốc độ âm thanh bằng cách điều khiển trường âm dài ngắn qua cơ chế Length regulator và Duration predictor mà các kiến trúc kia hoàn toàn không có
Length Control: Fast Speech có thể điều khiển tốc độ âm thanh bằng cách điều khiển trường âm dài ngắn qua cơ chế Length regulator và Duration predictor mà các kiến trúc kia hoàn toàn không có
III. Lời kết
Cảm ơn các bạn đã theo dõi bài viết. Trong bài viết hôm nay mình đã giới thiệu các bạn mô hình Fast Speech cũng như phân tích kiến trúc mô hình để thấy được các ưu điểm so với các phương pháp trước. Trong bài viết tiếp theo, chúng ta sẽ khám phá người anh em Fast Speech 2. Các bạn hãy follow và upvote đã theo dõi bài viết mới nhất nhé.