I. Quantization là gì ?
 Ảnh minh họa (Nguồn Internet)
Ảnh minh họa (Nguồn Internet)
Quantization là phương pháp hữu hiệu giúp tăng tốc thời gian xử lý của các mô hình học sâu mà đảm bảo độ chính xác không giảm đi đáng kể bằng cách tính toán và lưu trữ tensor ở kiểu dữ liệu có số bit thấp hơn kiểu dữ liệu float.
Như mọi người cũng biết, mô hình học sâu chính là các phép tính toán ma trận. Ma trận được biểu diễn bằng vô vàn số đơn lẻ dưới dạng cột và hàng. Do đó độ chính xác và thời gian tính toán của mô hình học sâu liên quan mật thiết đến cách ta lưu trữ, biểu diễn các số đơn lẻ này. Trong quá trình lưu trữ các số đơn lẻ , có hai vấn đề mà ta thường gặp đó chính là:
- Độ chính xác (Số các số sau dấu phẩy mà chúng ta có thể lưu trữ)
- Số bit cần để biếu diễn số đó
Ví dụ một số được biếu diễn bằng int32 thì 1 bit đầu tiên dùng để biếu diễn dấu, 31 bit còn lại để biếu diễn số đó. Điều đó có nghĩa là 1 số ở dạng int32 có thể biếu diễn giá trị từ cho đến . Tương tự như vậy, một số int8 chỉ biếu diễn các giá trị từ cho đến .
Số bit càng lớn thì số giá trị biểu diễn được càng nhiều nhưng việc thực hiện tính toán cũng như lưu trữ phức tạp nên mất thời gian xử lý đặc biệt với các phép như nhân ma trận.
Vậy Quantization thực hiện chuyển đổi giá trị như thế nào ?
Quantization thực chất là quá trình ánh xạ các giá trị liên tục sang một tập các giá trị rời rạc hữu hạn nhỏ hơn bằng một số giải thuật xác định ô. Xác định ô là cách nói ta gom những giá trị gần bằng nhau ở kiểu dữ liệu ban đầu sang cùng một giá trị mới ở kiểu dữ liệu mới do bị giới hạn về số lượng giá trị có thể biểu diễn. Ví dụ hai số 2.12234, 2.934 ở dạng float32 có thể cùng được đưa về 23 ở int8 vì cả hai đều nằm trong một ô có khoảng [2, 3]. Trong bài viết này mình sẽ không giải thích sâu về mặt toán học. Các bạn quan tâm đến phần này có thể tham khảo bài viết Quantization for Neural Networks. Các số sau khi thực hiện quantization sẽ có sai số so với số ban đầu do làm tròn (underflow, overflow), ...
II. Quantization trong Pytorch

Pytorch cũng như nhiều framework khác như Tensorflow,.... đều hỗ trợ quantization. Tuy nhiên, cá nhân mình thấy việc tiếp cận và làm quen với Pytorch khá dễ dàng đồng thời cũng có khá nhiều mô hình hiện tại trên nền tảng mã nguồn mở như github do đó mình quyết định chọn sử dụng Pytorch trong bài viết này.
1. Ưu điểm
Pytorch hỗ trợ quantize mô hình từ float32 (mặc định của torch) về int8 nhờ đó mô hình chúng ta có thể:
- Kích thước mô hình có thể giảm tới 4 lần
- Băng thông bộ nhớ có thể giảm 4 lần
- Tốc độ xử lý có thể nhanh hơn 2 đến 4 lần với tính toán bằng float32.
2. Quantization Mode
Pytorch cung cấp cho chúng ta hai chế độ quantization khác nhau:
- Eager Mode Quantization: Ở chế độ này, chúng ta cần hợp nhất các lớp như convolution, batchnorm, relu và xác định vị trí bắt đầu và kết thúc quantization thủ công. Và chúng ta chỉ sử dụng được các module thuộc torch hỗ trợ.
- FX Grapg Mode Quantization: Là một framework hỗ trợ quantization tự động của pytorch. Đây là một phiên bản nâng cấp của Eager Mode Quantization, hỗ trợ thêm các hàm thay vì chỉ các module thuộc torch.nn như Eager Mode Quantization. Tuy nhiên chúng ta cần sửa đổi lại mô hình ban đầu để phù hợp X Graph Mode Quantization.
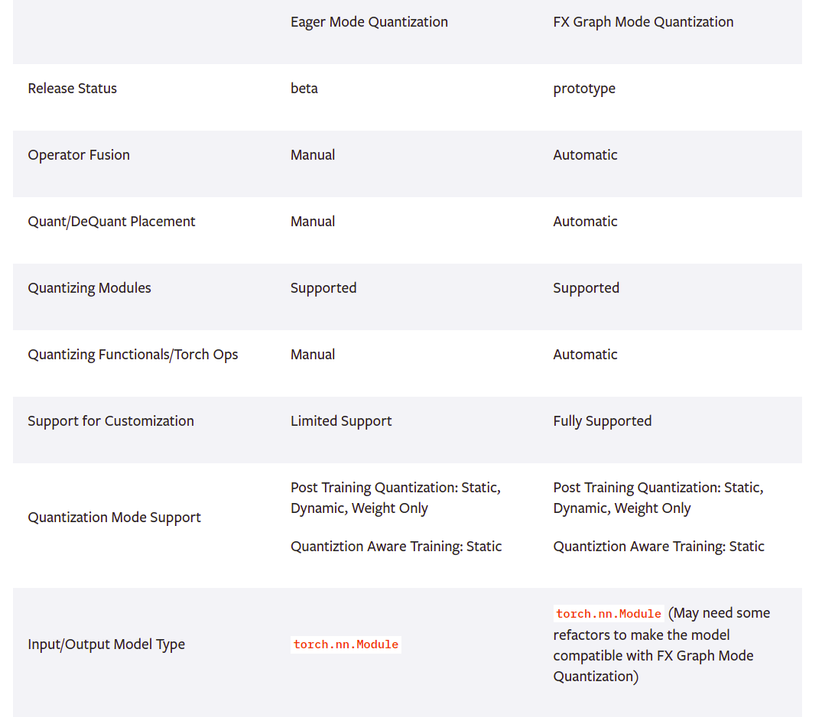 Bảng so sánh giữa Eager Mode Quantization và FX Graph Mode Quantization (Nguồn: https://pytorch.org/docs/stable/quantization.html)
Bảng so sánh giữa Eager Mode Quantization và FX Graph Mode Quantization (Nguồn: https://pytorch.org/docs/stable/quantization.html)
3. Giải thuật quantization
Cả hai chế độ Eager Mode Quantization và FX Graph Mode Quantization đều hỗ trợ ba giải thuật quantization dưới đây:
- Dynamic Quantization
- Static Quantization
- Quantization-aware training
3.1 Dynamic Quantization
Dynamic ở đây có nghĩa rằng việc tối ưu thuật toán quantization được diễn ra trong quá trình inference. Trong đó trọng số mô hình được quantize ngay lập tức còn các hàm activation sẽ được quantize vào lúc inference. Dynamic quantization thực hiện việc chuyển đổi bằng các các nhân giá trị đầu vào với một giá trị được gọi là scaling factor sau đó làm tròn kết quả này tới giá trị gần nhất và lưu trữ chúng.
Dynamic quantization là phương pháp kém hiệu quả nhất trong ba phuơng pháp do sự đơn giản của nó tuy nhiên phương pháp này thường được dùng trong những trường hợp thời gian thực thi bị ảnh hưởng nhiều bởi thời gian tải trọng số từ bộ nhớ hơn là do phép nhân ma trận. Bởi vậy, phương pháp này thường được sử dụng cho các mô hình như LTSM, Transformer, ....
Ví dụ:
import torch
quantized_model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8)
Trong đó:
- modelchính là model cần tối ưu
- {torch.nn.Linear} là tập hợp các lớp trong mô hình cần quantize
- dtype là kiểu dữ liệu quantize muốn chuyển về
3.2. Static Quantization
Static Quantization hay còn được gọi là Post Training Quantization. So với phương pháp đầu tiên, static quantization có 4 điểm khác biệt:
Điểm thứ nhất là thực hiện quantize weights và activations của mô hình trước khi inference.
Điểm thứ hai là có thêm một bước tiến hành tinh chỉnh lại mô hình sau khi quantize, điều này đảm bảo mô hình sau khi quantize đạt độ chính xác cao hơn so với việc chỉ thực hiện lúc inference.
Điểm thứ ba là độ chính xác phụ thuộc vào phần cứng. Do Pytorch sử dụng hai thư viện để hỗ trợ chuyển đổi là: FBGEMM trên chip x86 và QNNPACK trên chip ARM. Do đó cần đảm bảo máy chúng ta dùng đề huấn luyện và triển khai cần giống nhau về mặt kiến trúc .
Điểm thứ 4 là chúng ta cần thực hiện fuse layer hay gộp các lớp convolution, batchnorm, relu thành một nhờ lớp nn.Sequential. Nhờ gom nhiều lớp thành một như này cho phép các thư viện tính toán trong một lần duy nhất qua đó cải thiện hiệu năng mô hình.
import torch
model = torch.quantization.fuse_modules(model, [['conv', 'bn', 'relu']])
Ví dụ cách sử dụng Static Quantization, các bạn có thể tham khảo bài viết (BETA) STATIC QUANTIZATION WITH EAGER MODE IN PYTORCH để theo dõi chi tiết hơn.
III. Lời kết
Do bài viết cũng tương đối dài và đến đây mình cũng hơi đói bụng  nên còn một phương pháp rất hay và quan trọng trong quantization là Quantization Aware Training mình sẽ giới thiệu cho các bạn ở bài viết sắp tới. Cảm ơn mọi người đã theo dõi bài viết của mình. Nếu thấy bài viết của mình có ích cho các bạn thì đừng ngần ngại cho mình một lần follow và upvote bài viết nhé
nên còn một phương pháp rất hay và quan trọng trong quantization là Quantization Aware Training mình sẽ giới thiệu cho các bạn ở bài viết sắp tới. Cảm ơn mọi người đã theo dõi bài viết của mình. Nếu thấy bài viết của mình có ích cho các bạn thì đừng ngần ngại cho mình một lần follow và upvote bài viết nhé

