Tổng quan
Ai khi bước vào con đường trở thành 1 AI engineer cũng đã gặp trường hợp : khi training 1 model nhưng accuracy của tập train tăng dần ( loss giảm dần ) nhưng accuracy của tập test không tăng cùng tập train mà đến 1 giai đoạn nào đó accuracy của tập test sẽ giảm dần ( loss tăng dần ).

Đó gọi là overfitting ? Liệu có cách nào để giúp model tránh overfitting , cải thiện độ chính xác. Để biết được thì chúng ta cần phải hiểu rõ Bias, Variance là gì ?
1. Bias
Bias là sự sai lệch giữa giá trị mà model chúng ta dự đoán được với giá trị thật ( predict - ground truth). Mô hình với low bias thì chênh lệch giữa giá trị dự đoán và giá trị thật nhỏ => Mô hình tốt. Và ngược lại high bias thì chênh lệch giữa predict và ground truth lớn => Mô hình lỗi cao trên cả tập huấn luyện ( training) và tập kiểm thử ( testing) => Underfitting
2. Variance
Variance đại diện cho độ phân tán dữ liệu. Variance cao chứng tỏ phân tán cao, tập trung chú yếu vào dữ liệu huấn luyện mà không mang được tính tổng quát trên dữ liệu chưa gặp bao giờ => Mô hình rất tốt trên tập dữ liệu huấn luyện nhưng kết quả rất tệ trên tập kiểm thử => Overfitting
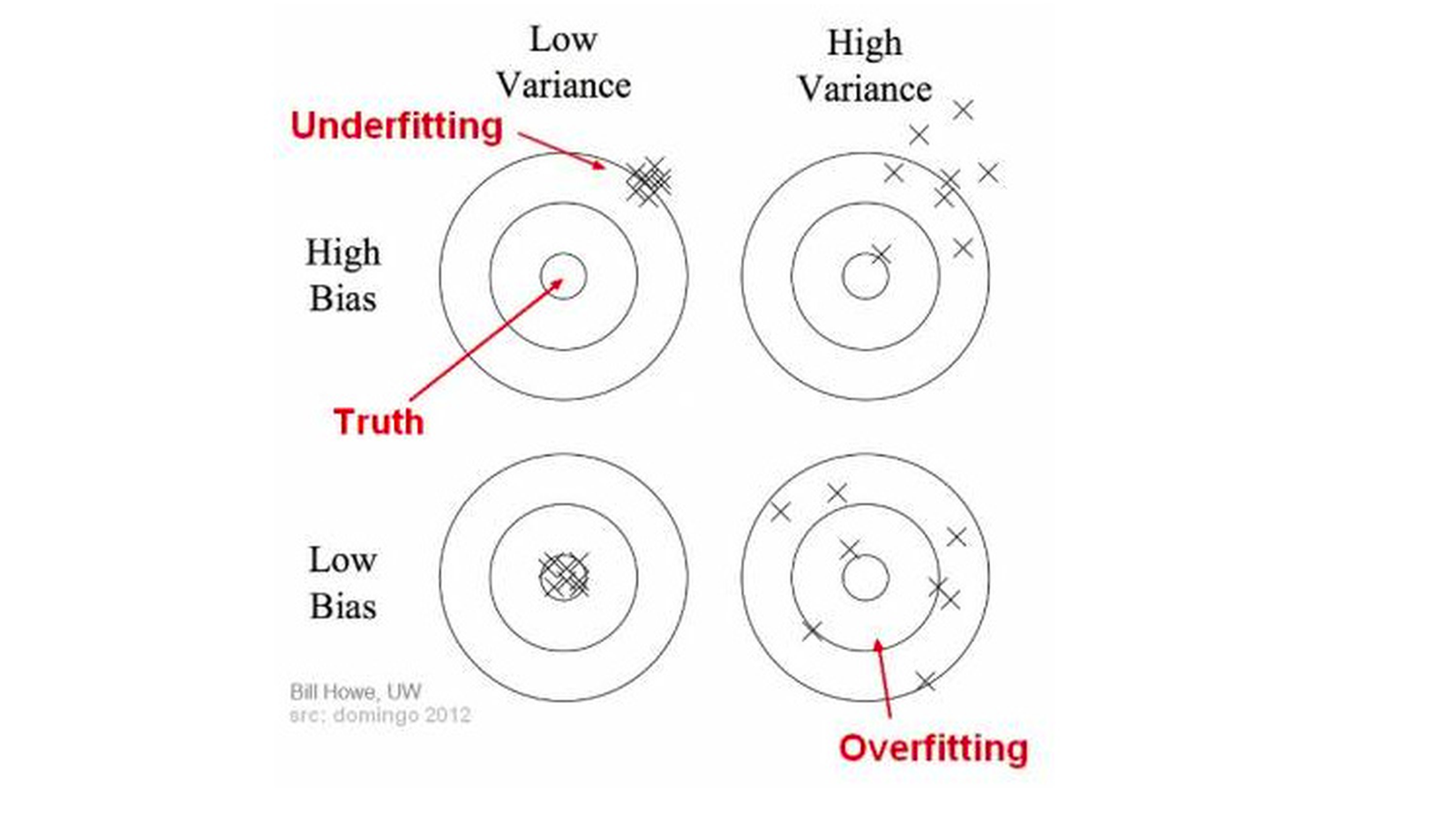
Underfitting, Overfitting là gì ?

Underfitting là mô hình mà high bias và variance low. Hiện tượng này xảy ra khi lượng dữ liệu quá ít hoặc ta cố gắng mô tả các dữ liệu phức tạp bằng các mô hình tuyến tính đơn giản như hồi quy. Khi gặp trường hợp này ta phải kiếm thêm data và tăng độ phức tạp của model ( tăng thêm 1 vài layer, node).
Overfitting là mô hình quá khít với dữ liệu, nó sẽ đúng trên tập training nhưng trên tập test (kiểm thử ) thì kết quả rất tệ. Mô hình này thường có bias nhỏ và variance lớn.Đặt câu hỏi vì sao nó lại đúng trên tập huấn luyện mà sai trên tập kiểm thử ?
Bởi vì khi training model trên rất nhiều dữ liệu nhiễu dẫn đến model bị quá phức tạp so với mức độ cần thiết => model không tổng quát hóa được nên khi gặp các dữ liệu chưa gặp bao giờ sẽ 'bỡ ngỡ' => dự đoán sai. Kiểu như 1 học sinh ôn bài để làm kiểm tra Toán, khi ôn bài học sinh đó chỉ ôn tủ các dạng bài mà thầy cô đã dạy ( có mẫu sẵn ) . Học sinh đó nghĩ là mai kiểu gì cũng làm trên 8 điểm, nhưng quá đen cho cậu ta, cậu ta gặp câu hỏi gần giống câu hỏi tủ nhưng đổi cấu trúc một chút, thế là không biết làm và được 0 điểm .
Train model cũng giống như việc học vậy, chúng ta không thể học qua loa là giải được 1 bài toán ( như underfitting), hay học tủ là có thể đạt điểm cao được ( như overfitting). Chúng ta cần phải học mà phải hiểu, tổng quát hóa được kiến thức nên gặp bài toán dạng nào cũng có thể giải được.
Các phương pháp tránh overfitting
1. Gather more data
Dữ liệu ít là 1 trong trong những nguyên nhân khiến model bị overfitting. Vì vậy chúng ta cần tăng thêm dữ liệu để tăng độ đa dạng, phong phú của dữ liệu ( tức là giảm variance).
Một số phương pháp tăng dữ liệu :
- Thu thập thêm dữ liệu : chúng ta phải craw thêm dữ liệu hay tới thực tiễn để thu thập, quay video, chụp ảnh,...Tuy nhiên trong nhiều trường hợp thì việc thu thập thêm dữ liệu là infeasible nên phương pháp này không được khuyến khích.
- Data Augmentation : Augmentation là 1 phương thức tăng thêm dữ liệu từ dữ liệu có sẵn bằng cách rotation, flip, scale, skew,... images. Phương pháp này được sử dụng rất phổ biến trong xử lý ảnh cho Deep learning.
![]()
1 số phương pháp data Augmentation:
 Use tf.image
Use tf.image
Use keras preprocessing layers
Use albumentation
Use openCV - GAN : GAN ( Generative Adverserial Network) là mô hình học không giám sát dùng để sinh dữ liệu từ nhiễu (noise). Nó là sự kết hợp của 2 model : Generative dùng để sinh ảnh từ nhiễu và Discriminator dùng để check ảnh được sinh ra có giống ảnh real hay không? GAN là mô hình hiên nay đang được sử dụng rất phổ biến và tính ứng dụng rất cao. Hiện có rất nhiều mô hình GAN như : CGAN, StyleGAN, StarGAN, CycleGAN,...Các bạn nên đọc cái này, thực sự rất bổ ích

Link tham khảo : nttuan8

2. Simple model
Một trong những nguyên nhân khiến model của bạn trở nên overfitting là: model của bạn quá sâu, phức tạp ( chẳng hạn như nhiều layer, node) trong khi chỉ có chút xíu dữ liệu. Ví dụ như bạn chỉ có <1 triệu nhưng bạn đòi mua nhà thì chịu ....Cách giải quyết ở đây : một là tăng thêm dữ liệu như ở trên, 2 giảm độ phức tạp của model bằng cách bỏ đi 1 số layer, node. Còn bỏ bao nhiêu layer, node thì dựa vào kinh nghiệm hoặc 'try and change'.
3. Use Regularization
Kĩ thuật regularization là thêm vào hàm mất lát ( loss) một đại lượng nữa.
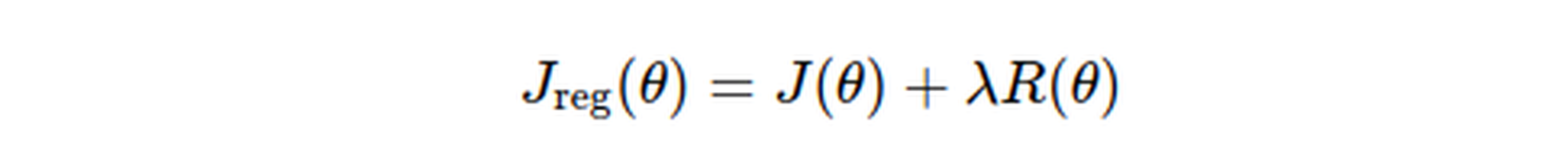
Đại lượng này sẽ tác động đến hàm loss. Cụ thể : nếu lamda lớn thì ảnh hưởng của đại lượng thêm vào lên hàm loss cũng lớn và ngược lại nếu lamda nhỏ thì ảnh hưởng của nó lên hàm loss cũng nhỏ. Nhưng lamda cũng không được quá lớn vì nếu quá lớn thì đại lượng thêm vào sẽ lấn át loss => mô hình xây dựng sẽ bị sai ( underfitting).
- l2 regularization :
![]()
Suy ra loss :![]()
Việc tối ưu hóa model cũng đồng nghĩa với việc làm giảm hàm mất mát ( loss ) => giảm weight . Nên norm2 regularization còn được gọi là 'weight decay' ( trọng số tiêu biến ). - l1 regularization:
![]()
Về cơ bản norm1 regularization cũng tương tự như chuẩn norm2 regularization. Nhưng đại lượng được thêm vào là tổng trị tuyệt đối của tất cả các phần tử.
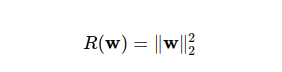
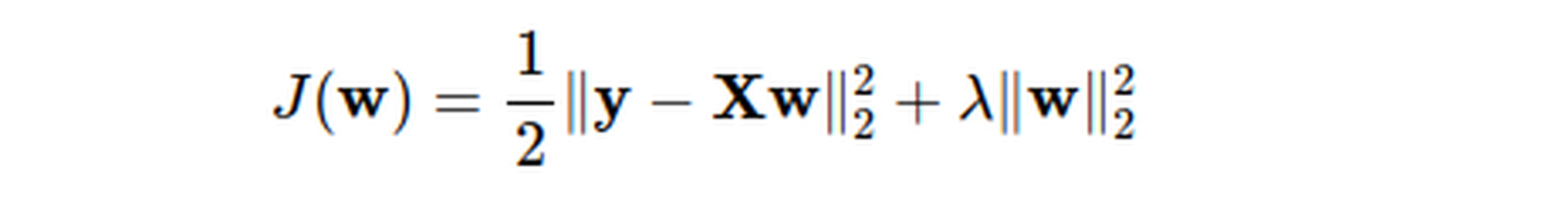
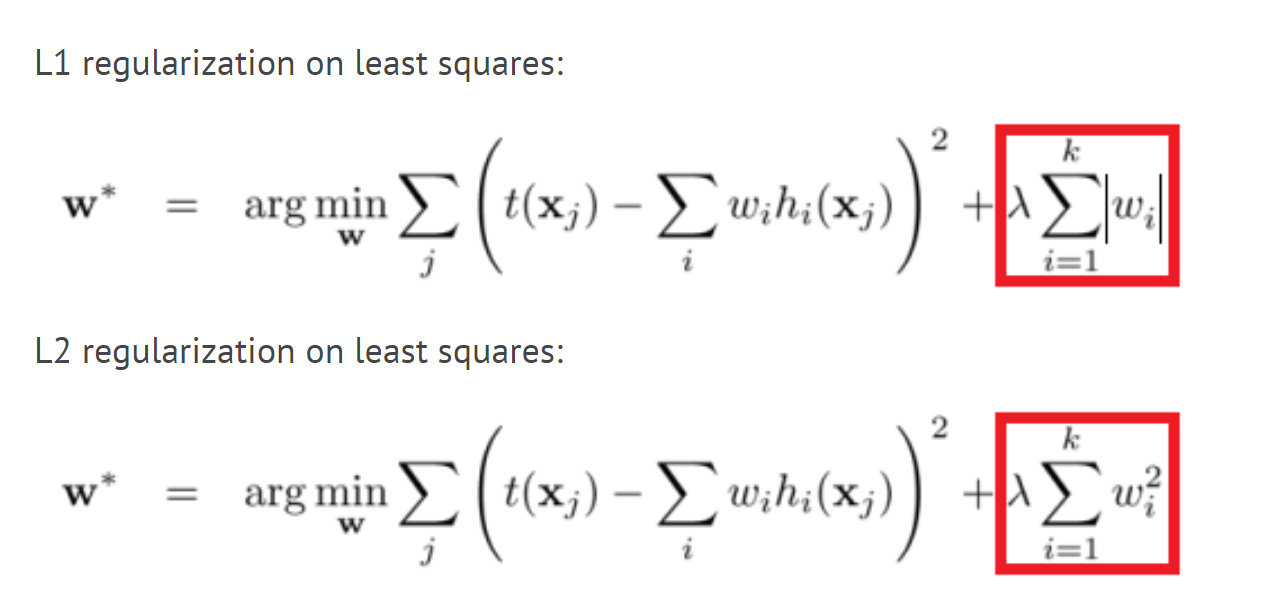
 Tóm lại : regularization là 1 kĩ thuật tránh overfitting bằng cách thêm vào hàm loss 1 đại lượng lamda. f(weight) => Tối ưu model ( giảm hàm loss ) => giảm weight => mô hình bớt phức tạp => tránh overfitting.
Tóm lại : regularization là 1 kĩ thuật tránh overfitting bằng cách thêm vào hàm loss 1 đại lượng lamda. f(weight) => Tối ưu model ( giảm hàm loss ) => giảm weight => mô hình bớt phức tạp => tránh overfitting.
4. Use Dropout
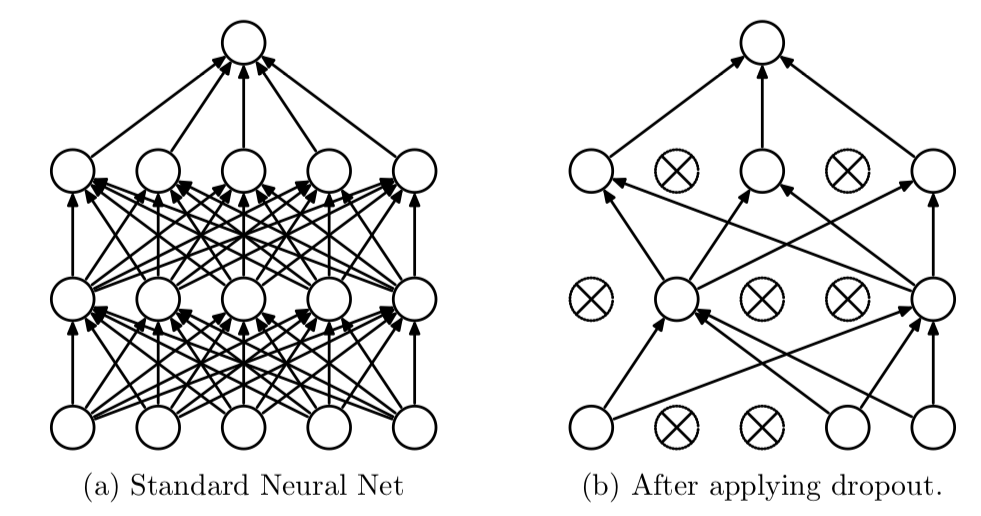
Dropout là kĩ thuật giúp tránh overfitting cũng gần giống như regularization bằng cách bỏ đi random p% node của layer => giúp cho mô hình bớt phức tạp (p thuộc [0.2, 0.5]) .
5. Early stoping
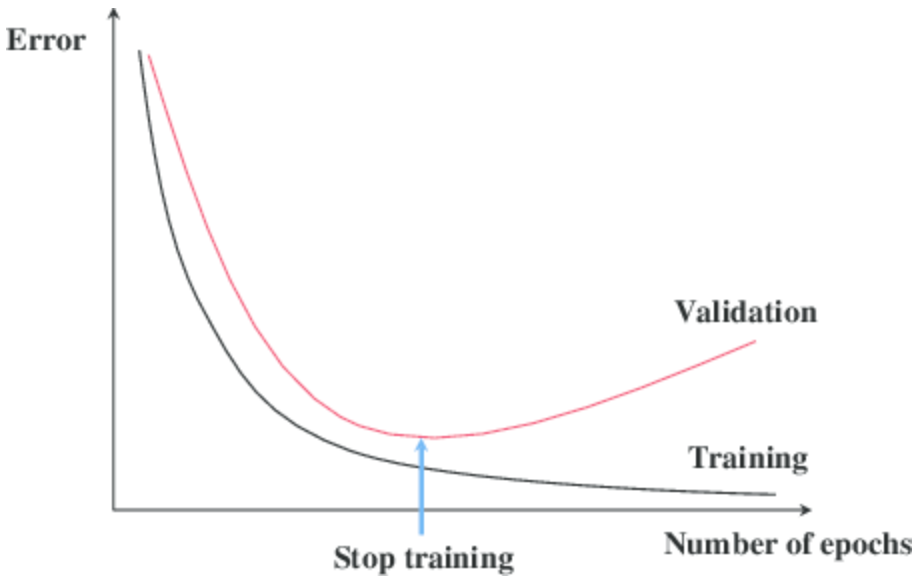
Khi training model thì không phải lúc nào (hàm mất mats) loss của tập train và tập test cũng đồng thời giảm, tới một epoch nào đó thì loss của tập train sẽ tiếp tục giảm nhưng loss của tập test không giảm mà tăng trở lại => Đó là hiện tượng overfitting. Vì vậy để ngăn chặn nó, thì ngay tại thời điểm đó người ta sẽ dừng việc training ( vì để chương trình tiếp tục training thì cũng không cải thiện được gì mà lại tốn tài nguyên ).
Kết luận
Hiện tượng overfitting là hiện tượng rất phổ biến trong việc training model nên việc gặp phải ( mắc phải ) thì là điều hết sức bình thường. Không có gì phải sợ cả, các bạn hãy thử 1 vài phương pháp trên kết hợp lại như : Dropout + Regularization + Augmentation.
Chúc các bạn thành công !





