Giới thiệu
Làm về xử lý ảnh, chắc hẳn các bạn sẽ bắt gặp 1 số bài toán như tái tạo ảnh, giảm nhiễu ảnh, làm sáng ảnh, hay bài toàn giảm chiều dữ liệu, … Gặp các bài toán này thì cũng có khá nhiều phương pháp để xử lý, với cá nhân mình thì mình nghỉ ngày tới kỹ thuật Autoencoder. Lướt một vòng google search thì mình chỉ tìm thấy các bài viết nước ngoài hoặc 1 số blog của các anh Việt Nam, còn Viblo thì chưa thấy, nên mình quyết định góp chút sức để làm phòng phú thêm cộng đồng Viblo
Cùng tìm hiểu về Autoencoder nào!
Nguồn: https://d1m75rqqgidzqn.cloudfront.net/wp-data/2020/04/29202749/Bloginfo29-04-2020-R-02-1024x522.png
Autoencoder là gì?
“An autoencoder is a type of artificial neural network used to learn data encodings in an unsupervised manner.”
Autoencoder là mạng ANN có khả năng học hiệu quả các biểu diễn của dữ liệu đầu vào mà không cần nhãn, nói cách khác, giả sử từ một hình ảnh có thể tái tạo ra một bức ảnh có liên quan chặt chẽ với bức ảnh đầu vào đó. Đầu vào loại mạng neural này không có nhãn, tức là mạng có khả năng học không giám sát (Unsupervised Learning)
Đầu vào được mạng mã hóa để chỉ tập trung vào các đặc trưng quan trọng nhất, tùy vào bài toán cụ thể. Các biểu diễn (coding) thường có chiều nhỏ hơn so với input của Autoencoder, đó là lý do Autoencoder có thể dùng trong các bài toán giảm chiều dữ liệu hoặc trích xuất đặc trưng.
Bên cạnh đó, Autoencoder còn có thể được sử dụng để tạo ra các mô hình học tập trung (Generative learning models), ví dụ như huấn luyện một tập hợp các khuôn mặt để tạo ra các khuôn mặt mới
Tham khảo một số bài viết, mình có thấy các tác giả nói rằng mục đích của Autoencoder là cố gắng học vào tạo ra ouput giống với input nhất có thể dựa vào việc tập trung vào các đặc trưng cần thiết. Tuy nhiên các bạn cẩn thận kẻo nhầm, tùy các bài toán cụ thể, ví dự như làm nét ảnh, làm mờ ảnh, hay kéo sáng ảnh mà đầu ra và đầu vào sẽ giống về nội dung chứ giá trị thì không hẳn. Chứ không phải là ảnh đầu ra và đầu vào phải giống hệt nhau cho mọi bài toán được, thế thì copy paste cho lành chứ Autoencoder với Deep Learning làm gì cho khổ?
Kiến trúc của Autoencoder
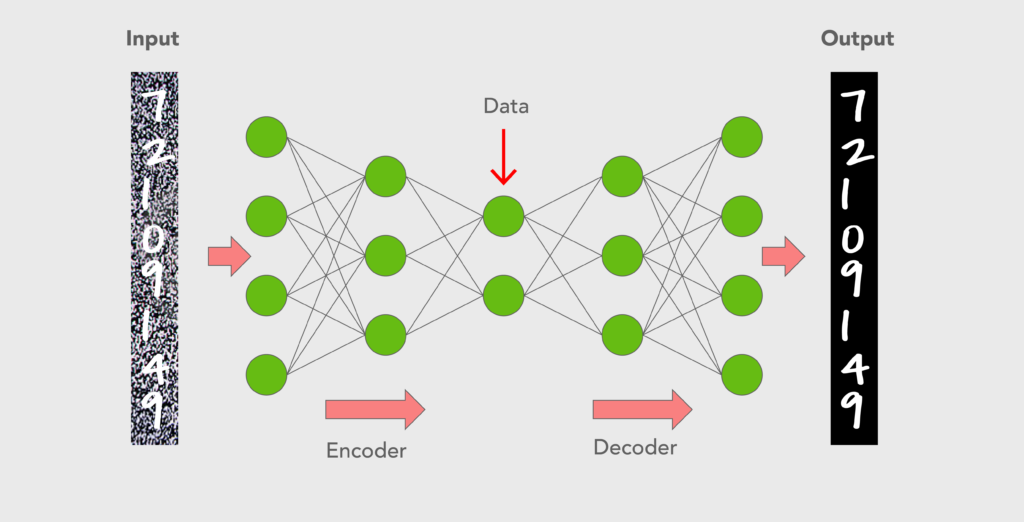
Autoencoder bao gồm 3 phần chính
- Encoder: Module có nhiệm vụ nén dữ liệu đầu vòa thành một biễu diễn được mã hóa (coding), thường nhỏ hơn một vài bậc so với dữ liệu đầu vào
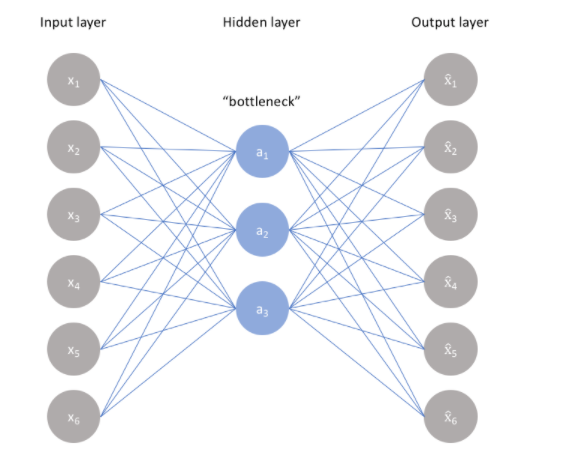
- Bottleneck: Module chứa các biểu diễn tri thức được nén (chính là output của Encoder), đây là phần quan trọng nhất của mạng bới nó mang đặc trưng của đầu vào, có thể dùng để tái tạo ảnh, lấy đặc trưng của ảnh, ….
- Decoder: Module giúp mạng giải nén các biểu diễn tri thức và tái cấu trúc lại dữ liệu từ dạng mã hóa của nó, mô hình học dựa trên việc so sánh đầu ra của Decoder với đầu vào ban đầu (Input của Encoder)
Autoencoder hoạt động như thế nào?
Để tìm hiểu về cách thức hoạt động của Autoencoder, trước hết chúng ta sẽ cùng tìm hiểu về mối liên quan giữa các khối Encoder, Bottleneck và Decoder
1. Encoder
Bao gồm một tập gợp các convolutional blocks, theo sau là các polling modules giúp cho việc nén đầu vào của mô hình thành một phần nhỏ gọn hơn, được gọi là Bottleneck. Ở đây thì ngoài việc sử dụng các Convolutional + Pooling thì có thể chỉ cần sử dụng các khối fully connected tùy vào đầu vào và bài toán yêu cầu. Ví dụ bài toán làm mờ chữ số viết tay, thì chỉ cần một vài lớp Fully connected cũng đã làm rất tốt nhiệm vụ của mình rồi Tiếp đến, với đầu ra là Bottleneck, bộ Decoder sẽ giải mã bằng một loạt các module Upsampling (hoặc Fully Connected) để đưa đặc trưng nén về dạng hình ảnh. Trong các bài toán đơn giản thì đầu ra được mong đợi là giống với đầu vào (nhiễu hơn hoặc nét hơn, …) Tuy nhiên với các bài toán cao hơn thì ảnh đầu ra mong muốn là một ảnh hoàn toàn mới, mang một mối liên hệ chặt chẽ với ảnh đầu vào, được hình thành từ đặc trưng của ảnh đầu vào đã cung cấp
2. Bottleneck
Phần quan trọng nhất cảu Autoencoder, cũng là phần mang kích thước nhỏ nhất Bởi Bottleneck được thiết kế từ việc mã hóa tối đa thông tin của ảnh đầu vào, vậy nên có thể nói rằng bottleneck mang đặc trưng, chi thức của ảnh đầu vào Với cấu trúc mã hóa – giải mã, mô hình trích xuất được đặc trưng của ảnh dưới dạng dữ liệu và thiết lập được mối tương quan giữa input và output của mạng Với việc Bottleneck có kichc thước nhỏ hơn ảnh đầu vào cũng như mang nhiều thông tin đặc trưng giúp ngăn cản mạng ghi nhớ quá nhiều. Bottle neck càng nhỏ, tủi ro overfitting càng thấp, tuy nhiên nếu kích thước Bottleneck quá nhỏ sẽ hạn chế khả năng lưu trữ thông tin của ảnh đầu vào, gây khó khăn cho việc giải mã ở khối Decoder
3. Decoder
Khối cuối cùng, mang nhiệp vụ giải mã từ Bottleneck để tái tạo lại hình ảnh đầu vào dựa vào các đặc trưng “tiềm ẩn” bên trong Bottleneck
Một số Hyper-parameter quan trong trong Autoencoder
Các bạn cần phân biệt Hyperparameter và parameter nhé. Một bài viết về các hiểu nhầm trong Machien Learning mình để tại đây để các bạn tham khảo
Có 4 hyperparameters cần quan tâm trước khi training một mô hình Autoencoder:
- Code size: kích thước của Bottleneck là 1 hyperparameter rất quan trọng được sử dụng mà chúng ta cần lưu ý. Kích thước Bottleneck quyết định lượng thông tin được nén. “Nhiều quá không tốt mà ít quá cũng không ổn”
- Number of layers: giống với hầu hết các mạng neural, một hyperparameter quan trọng để điều chỉnh độ sâu của encoder và decoder trong Autoencoder, càng sâu thì mô hình càng phức tạp, nhưng càng nông thì mô hình chạy càng nhanh, càng light weights
- Number of nodes per layer: Số lượng nodes trên 1 layer quyết định số weights ra sẽ sử dụng trên từng layer. Thông thường, số lượng nút này giảm dần theo mỗi lớp tiếp theo bởi đầu vào của lớp này là đầu ra của lớp trước đó, và đầu vào này thì dần trở nên nhỏ hơn trên các lớp
- Reconstruction Loss: Loss function là một thức không thể thiếu trong mạng neural. Hàm loss này sẽ phụ thuộc vào kiểu input và oupt của mô hình chúng ta muốn đáp ứng. Ví dụ với việc xử lý ảnh, các hàm loss thông thường được ưa chuộng là Mean Square Error (MSE) và L1 Loss. Còn với một số trường hợp ảnh nhị phân (MNIST), chúng ta có thể sử dụng Binary Cross Entropy sẽ tốt hơn.
Tổng kết
Như vậy, trong khuôn khổ bài viết đã khá là nhiều chữ và code tutorial thì chả thầy đâu thì mình nghỉ đọc vậy đã đủ rồi. Bài viết này mình mong muốn mang tới một cái nhìn tổng quan về Autoencoder cho người mới để hiểu hơn về nó mà biết vận dụng cho bài toán của mình. Code tutorial thì trên mạng có nhiều lắm, các bạn có thể tham khảo.
Trong bài viết tới mình sẽ tìm hiểu tiếp về 5 kiểu Autoencoder, mong cách bạn sẽ ủng hộ.
References
An Introduction to Autoencoders: Everything You Need to Know



