Trích dẫn:
Nội dung bài viết phân tích và tổng hợp các kiến thức có trong paper ["Traffic-Sign Detection and Classification in the Wild"] (2016)(https://cg.cs.tsinghua.edu.cn/traffic-sign/)
Tổng quan:
Bài báo đến từ đội ngũ Nhóm nghiên cứu của Phòng Nghiên cứu Khoa Học Máy Tính và Công Nghệ, Đại học Thanh Hoa Bắc Kinh (Tsinghua University), được công bố ở hội nghị CVPR năm 2016. Các tác giả bao gồm: Zhe Zhu, Dun Liang, Song-Hai Zhang, Xiaolei Huang, Baoli Li and Shi-Min Hu.
Bài báo thuộc chủ đề/Thể loại Object Detection: là 1 bài toán không mới và cũng đã đạt được rất nhiều các thành tựu trong những năm gần đây, cả phần ứng dụng và mô hình thuật toán. Điển hình là các phương pháp Object Detection sử dụng Deep Learning đã đạt được các bước cải thiện vượt trội so với các phương pháp xử lý ảnh thông thường khác.
Mục tiêu cốt lõi của nhóm tác giả là giới thiệu 2 mục tiêu và kết quả chính của bài báo:
- Xây dựng một tập data Tsinghua-Tencent 100K thực tế hơn các tập data về Traffic-Sign trước đó.
- Xây dựng được mạng CNN cải tiến để vừa xác định biển báo, vừa phân loại biển báo luôn.
Tác giả cung cấp bộ data set 100K tấm ảnh góc rộng từ Tencent Street View. Ngoài ra tác giả có cung cấp 1 file caffemodel và 3 file .prototxt để train và test cho mô hình Fast R-CNN.
Các công trình tiền nhiệm
Tác giả có trích dẫn nhiều bài báo trước đó cùng chủ đề:
- [1] Man vs. computer: Benchmarking machine learning algorithms for traffic sign recognition: 2012, link https://www.ini.rub.de/upload/file/1470692859_c57fac98ca9d02ac701c/stallkampetal_gtsrb_nn_si2012.pdf
- [2] The German Traffic Sign Recognition Benchmark: A multi-class classification competition, https://www.ini.rub.de/upload/file/1470692848_f03494010c16c36bab9e/StallkampEtAl_GTSRB_IJCNN2011.pdf
- [3] Traffic Sign Recognition with Multi-Scale Convolutional Networks http://yann.lecun.com/exdb/publis/pdf/sermanet-ijcnn-11.pdf
- [4] https://cs.nyu.edu/~fergus/teaching/vision/5_detection.pdf
- [5] An Empirical Evaluation of Deep Learning on Highway Driving https://arxiv.org/pdf/1504.01716.pdf
Kể từ khi có tập data về biển báo đầu tiên của Đức GTSDB và GTSRB [24,25] đến nay, có nhiều nhóm nghiên cứu đã làm về 2 pha này (detection & classification), và đạt đến gần 100% độ chính xác (recall & precision for detection) và 99.67% (classification)
Nói sơ qua về tập Data GTSRB sử dụng trong cuộc thi tại thời điểm ra mắt bài báo:
- Tập data bao gồm hơn 50,000 ảnh được chụp trên đường phố nước Đức
- Chia thành 43 lớp loại khác nhau của Traffic-sign
- Được trích xuất từ hơn 10 giờ video với độ phân giải 1360×1024 pixels, sau đó được convert từ dạng Raw sang RGB format
- Dữ liệu sau đó sử dụng NISYS Advanced Development and Analysis Framework để đánh dấu và gán nhãn thủ công
- Kích thước của traffic signs trong tập này dao động từ 15×15 đến 222×193 pixel
Các phương pháp đưa ra đã đạt kết quả rất tốt trên tập GTSRB, lên đến 99.6% tốt hơn cả con người. Từ 2012 đến nay các nhóm nghiên cứu đã Ứng dụng và cải tiến được đáng kể các thuật toán phổ biến trong object detection như:
- R-CNN -> SPPNet -> Fast R-CNN -> Faster R-CNN
- OverFeat: là một feature extractor được huấn luyện trên tập dữ liệu ImageNet
Vấn đề đặt ra:
- Tác giả nhận định các dataset trước đó không đại diện cho hầu hết các trường hợp thực tiễn, ví dụ như trong GTSRB, biển báo lại xuất hiện trong hầu hết các bức ảnh, và thuật toán chỉ việc phân loại biển báo trong ảnh mà thôi.
- Bộ dataset chưa có các trường hợp gây nhiễu làm lệch kết quả tính toán
- Trong thực tế biển báo chỉ chiếm một phần rất nhỏ trong ảnh, thường nhỏ hơn 1%. Trong khi đó dataset hiện tại thì hình biển báo chiếm tỉ lệ tương đối trong bức ảnh. Như vậy là không thực tiễn
- Trong ImageNet và COCO, hình được lấy từ Internet search engine, mà ở đó khá ít user tải ảnh từ thực tế cuộc sống mà có biển báo giao thông như khi ta đi trên đường, hoặc nếu có thì cũng chỉ là vô tình và ngẫu nhiên. Cách thu thập data này thiếu tính thực tế.
- Trong GTSRB, các biển báo được trích xuất từ một phân đoạn video, tức hình biển báo sẽ rất giống nhau ở mọi hình. Điều này dẫn đến độ đa dạng trong tập data sẽ không được như mong đợi.
Bộ dữ liệu mới
Data lấy từ Tencent Street View (từ 300 thành phố ở Trung Quốc và các tuyến đường kết nối chúng). Được chụp với camera 6 SLR và sau đó ghép nối lại với nhau. Các kỹ thuật xử lý ảnh như điều chỉnh độ phơi sáng cũng được dùng. Các ảnh này được chụp từ phương tiện giao thông và các thiết bị gắn trên vai với tần suất 10 phút.
Trong các tập data trước đây, đối tượng cần detect thường chiếm kích thước lớn (khoảng hơn 20%) trong ảnh, các loại biển báo ít đa dạng. Trong thực tế biển báo có thể là một phần nhỏ trong ảnh với kích cỡ thông thường khoảng 80x80p, và thường chiếm chỉ 0.2% bức ảnh.
Với bộ data mới này (Tsinghua-Tencent 100K), các tấm ảnh được chụp từ các camera trong những điều kiện ánh sáng và thời tiết khác nhau, chỉ chiếm một phần nhỏ và có thể ở bất cứ vị trí nào trong ảnh nên sẽ mô phỏng các tình huống thực tế tốt hơn.
Nhiều loại biển báo (100K ảnh với 30K biển báo), góc chụp đa dạng hơn (chính diện, nghiêng), có các biển nhìn rõ và cả những biển bị che khuất một phần
Ảnh chụp trong nhiều điều kiện thời tiết (trời nắng, có mây). Các tấm ảnh được chọn lọc và đánh nhãn bằng tay. Ghi dấu lại khung bao, các đỉnh của khung và gán nhãn cho biển báo trong từng tấm ảnh.
Một số ảnh chụp có background phức tạp làm tăng độ khó khi detect biển báo. Sau đây là ví dụ mẫu lấy từ bộ dữ liệu.

Các mô hình CNN được nhắc đến:
AlexNet (2012)
AlexNet là một trong những Mô hình đầu tiên giải quyết bài toán phân lớp (classification)một bức ảnh vào 1 lớp trong 1000 lớp khác nhau (vd gà, chó, mèo … ). Đầu ra của mô hình là một vector có 1000 phần tử. Mạng CNN này đã thắng hạng nhất trong cuộc thi ILSVRC năm 2012. Kiến trúc mạng như sau:
 Đầu vào của AlexNet là một bức ảnh RGB 3x256x256 ở cả tập train và tập test. Đây là kích thước chuẩn bắt buộc sử dụng trong mạng.
Sau khi chuẩn hóa, kích thước đầu vào được sử dụng là 227x227 và cắt ngẫu nhiên trên hình gốc 256x256.
Đầu vào của AlexNet là một bức ảnh RGB 3x256x256 ở cả tập train và tập test. Đây là kích thước chuẩn bắt buộc sử dụng trong mạng.
Sau khi chuẩn hóa, kích thước đầu vào được sử dụng là 227x227 và cắt ngẫu nhiên trên hình gốc 256x256.
Kiến trúc AlexNet bao gồm 5 convolutional Layer và 3 fully connected layer. Nó có tổng cộng 60 triệu tham số và 650 nghìn neural.
Các convolutional Layer (filter) đầu tiên có chức năng trích xuất các đặc trưng cơ bản của tấm ảnh:
- Filter đầu tiên chứa 96 kernel có kích thước 3x11x11, stride=4
- Các layer sau kết nối với layer trước đó qua một Overlapping Max Pooling ở layer thứ 1,2 và 5. Max Pooling layer thường được sử dụng để giảm chiều rộng và chiều dài của một tensor nhưng vẫn giữ nguyên chiều sâu
- ReLU nonlinerity được sử dụng sau tất các các convolution và fully connected layer. Theo tác giả, ReLU giúp cho mạng huấn luyện nhanh hơn và cải thiện độ lỗi gấp nhiều lần so với khi dùng hàm Tanh hay Sigmoid.
- Cho đến cuối cùng, layer thứ 7 là fully connected kết nối với layer 8 là một bộ phân lớp dùng softmax với 1000 vector đầu ra, với tổng giá trị bằng 1. Bạn có thể đọc thêm về mạng AlexNet tại đây: https://www.phamduytung.com/blog/2018-06-15-understanding-alexnet/#ixzz6op5N5Kb8
OverFeat(2013)
OverFeat là một mạng CNN dùng để detect (classification, localization and detection) đối tượng cực kỳ hiệu quả, được cải tiến dựa trên mạng CNN AlexNet của Alex Krizhevsky (2012). Dưới đây là bảng mô tả kiến trúc cơ bản của mạng OverFeat:
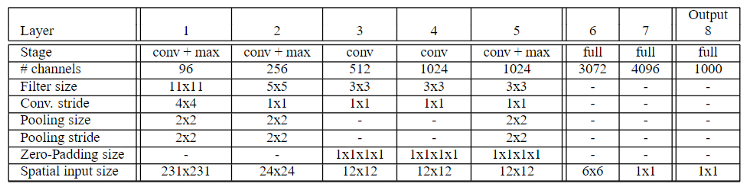
Các cải tiến của OverFeat so với AlexNet bao gồm:
- Pooling region không xài Overlapping, tức stride của lớp max pooling đúng bằng kích thước của kernel, các tấm kernel khi trượt sẽ không chồng lắp lên nhau (mạng AlexNet có chồng lên 1 pixel).
- Feature map sẽ to hơn một chút do dùng slide nhỏ hơn so với AlexNet.
- Sử dụng cửa số trượt sliding window hiệu quả hơn nhờ vào việc share kết quả tính toán của một vùng từ lần trước cho lần tính toán sau (thường sẽ overlap nhau rất nhiều).
- Sử dụng cơ chế multi-view voting: scale tấm ảnh ra thành nhiều tấm ảnh, sau đó dự đoán tất cả chúng, rồi lấy trung bình kết quả.
- Để localization, tìm ra bouding box của đối tượng, mạng này thay classifier layer (layer thứ 6,7,8) bằng một mạng hồi quy, sử dụng kết quả từ layer thứ 5 làm input. Ở đó, output cuối cùng của mạng hồi quy này là các vector 4 chiều mô tả bounding box của input tương ứng. Như vậy bằng việc tách nhánh ở cuối layer 5, tác giả đã xử lý được song song việc classification và tìm ra bounding box luôn một thể.
Bạn có thể đọc thêm về OverFeat tại đây: https://towardsdatascience.com/overfeat-review-1312-6229-4fd925f3739f
R-CNN(2014), Fast R-CNN(2015), Faster R-CNN(2016)
####Mạng R-CNN được đề xuất năm 2014 có thêm những cải tiến đáng kể trong kiến trúc mạng CNN. Cụ thể kiến trúc mạng được thể hiện trong hình sau:
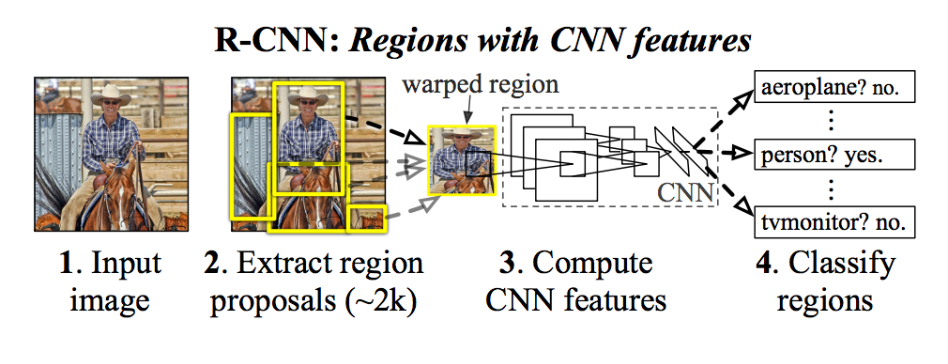
Sự khác biệt chính so với các kiến trúc mạng trước đó là ờ bước 2: Extract region proposals bằng một mạng riêng gọi là Region Proposal Network (RPN). Đầu ra của bước 2 là khoảng 2000 vùng ảnh nhỏ hơn trích xuất từ ảnh gốc, mỗi ảnh là một ứng viên có khả năng bao chứa đối tượng bên trong và được lựa chọn bằng thuật toán "selective search". 2000 tấm ảnh nhỏ này được tiếp tục đưa qua các lớp CNN khác tương tự như các mạng trước đó để phân loại.
Mạng Fast R-CNN(2015) ra đời ngay sau đó để khắc phục một số nhược điểm của mạng R-CNN. Kiến trúc mô hình như hình ảnh từ bài báo:
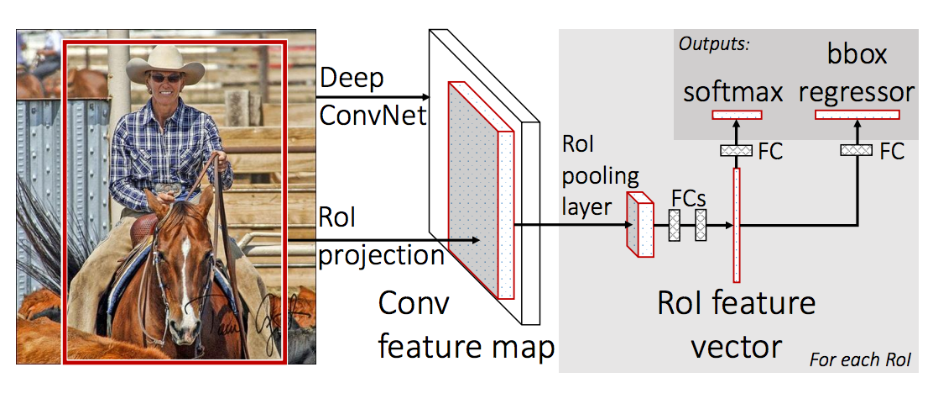
- Thay vì phải xử lý tận 2000 hình đấu ra ở lớp RPN cho mỗi ảnh, mạng mới này dùng phép chiếu ROI projection để lấy ra vị trí tương đối của một ảnh nhỏ bao chứa đối tượng. Song song với đó, Mạng dùng một pretrained-model khác như VGG16 để trích xuất ra Feature Map và hứng khung chiếu của ảnh nhỏ từ phép chiều ROI projection đã nêu. Quá trình này giúp tăng tốc độ trích xuất feature map lên thay vì phải trích xuất 2000 lần mà đa số các ảnh con sẽ trùng lắp nhau ở một vùng ảnh nào đó.
- Ở bước cuối cùng, thay vì tuần tự phân lớp ảnh sau đó dùng hồi quy để tìm bounding box, Fast R-CNN chủ động tách ra 2 luồng, một luồng dùng softmax để phân loại, một luồng dùng hồi quy để tìm ra bouding box của đối tượng.
Mạng Faster R-CNN(2016)
YOLOs (sẽ tiếp tục bổ sung)
Giải pháp đề xuất của nhóm tác giả:
Mô hình mới lấy ý tưởng từ cả mô hình OverFeat và Vehicle Detection như đã trình bày ở phần trên cho bài toán Traffic Sign Detection. Bảng sau đây mô tả tổng thể kiến trúc các layer của mô hình mạng mà tác giả đề xuất:
 Các thay đổi, điều chỉnh so với mô hình gốc như sau:
Các tác giả đã thử nghiệm việc chạy song song truoc khi xong layer thứ 7, và nhận thấy tách nhánh để chạy song song từ sau layer 6 là giải pháp cân bằng giữa thời gian tính toán và độ chính xác cần thiết (tách càng sớm thì performance càng nhanh nhưng tốn nhiều tài nguyên, tách quá trễ sẽ tính toán lâu hơn).
So với bài toán Vehicle Detection, thì layer cuối cùng có thêm 1 nhánh chạy song song giúp phân loại luôn loại biển báo.
Các thay đổi, điều chỉnh so với mô hình gốc như sau:
Các tác giả đã thử nghiệm việc chạy song song truoc khi xong layer thứ 7, và nhận thấy tách nhánh để chạy song song từ sau layer 6 là giải pháp cân bằng giữa thời gian tính toán và độ chính xác cần thiết (tách càng sớm thì performance càng nhanh nhưng tốn nhiều tài nguyên, tách quá trễ sẽ tính toán lâu hơn).
So với bài toán Vehicle Detection, thì layer cuối cùng có thêm 1 nhánh chạy song song giúp phân loại luôn loại biển báo.
Kết quả và đối sánh hiệu quả:
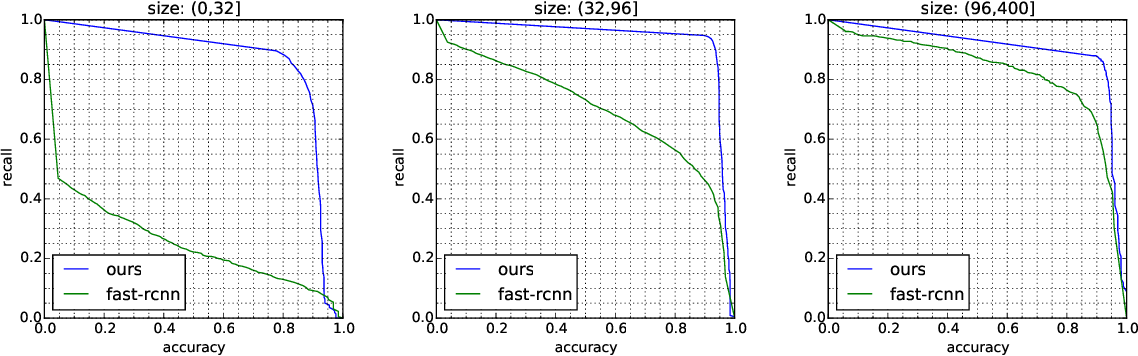
Trong thí nghiệm này, cả hai pha huấn luyện và kiểm thử đều thực hiện trên Linux PC với chip Intel Xeon E5-1620 CPU,2 NDIVIA tesla K20 GPU và 32GB RAM. Kết quả so sánh với mô hình Fast R-CNN trong việc classify loại biển báo, với các kích thước khác nhau trên bộ dữ liệu mới này:
Tài liệu tham khảo:
- The Graphics and Geometric Computing Group, Tsinghua University
- Towards Data Science, https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://cg.cs.tsinghua.edu.cn/traffic-sign/
- https://phamdinhkhanh.github.io/2019/09/29/OverviewObjectDetection.html#43-faster-r-cnn-2016


