Ở phần trước mình đã giới thiệu hai phần: Đồng bộ hóa đồng hồ và Đồng hồ logic ở bài Tìm hiểu về hệ phân tán (Phần 5: Đồng bộ hóa) - Part 1 thì hôm nay mình sẽ giới thiệu hai mục còn lại trong phần mục lục. Cùng tìm hiểu nhé!
Mục lục
- (1) Đồng bộ hóa đồng hồ (Clock Synchronization)
- (2) Đồng hồ logic (Logical clock)
- (3) Loại trừ lẫn nhau (Mutual exclusion)
- (4) Các giải thuật bầu chọn (Election algorithm)
3. Mutual exclusion
Nguyên tắc cơ bản của hệ phân tán là sự đồng thời và cộng tác của những đa tiến trình. Trong nhiều trường hợp , điều này có nghĩa là nhiều tiến trình cùng một lúc cùng truy cập vào một tài nguyên. Có nhiều giải thuật được xây dựng để cài đặt cơ chế loại trừ nhau thông qua các vùng tới hạn để tránh điều này xảy ra.
- Có ba giải thuật phổ biến là:
- Giải thuật tập trung (Centralized Algorithm)
- Giải thuật phân tán (Distributed Algorithm)
- Giải thuật vòng (TokenRing Algorithm).
3.1. Centralized Algorithm
Giả sử mỗi tiến trình có một số ID duy nhất. Tiến trình được bầu chọn làm điều phối (Coordinator) là tiến trình có số ID cao nhất.
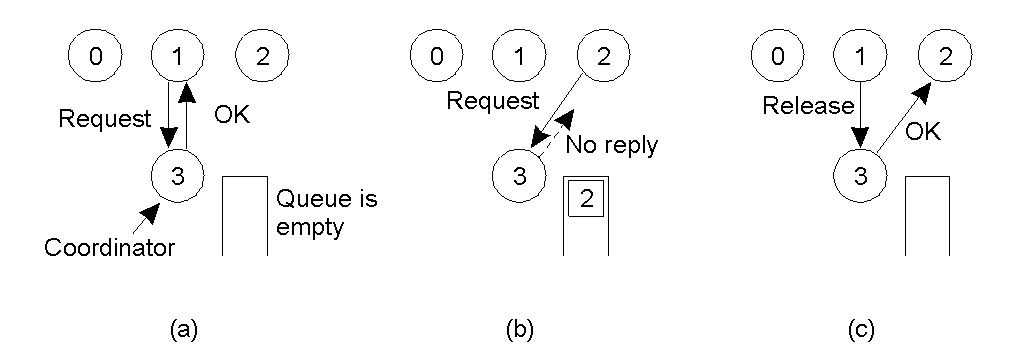
- Khi một tiến trình nào đó cần vào vùng giới hạn nó sẽ gửi một thông điệp xin cấp quyền .
- Nếu không có một tiến trình nào đang trong vùng giới hạn thì tiến trình điều phối sẽ gửi phản hồi cho phép.
- Còn nếu có một tiến trình khác đang ở trong vùn tới hạn rồi thì tiến trình điều phối sẽ gửi thông điệp từ chối và đưa tiến trình này vào hàng đợi cho đến khi không có tiến trình nào trong vùng tới hạn nữa.
- Khi một tiến trình rời khỏi vùng giới hạn nó sẽ gửi một thông điệp đến tiến trình điều phối thông báo trả lại quyền truy cập.
- Lúc này tiến trình điều phối sẽ gửi quyền truy cập cho tiến trình đầu tiên trong hàng đợi truy cập.
Ưu điểm:
- Giải thuật đảm bảo sự loại trừ lẫn nhau: bộ điều phối chỉ để một tiến trình truy cập tài nguyên trong 1 thời điểm.
- Không có tiến trình nào phải đượi vô thời hạn.
- Sự sắp xếp này dễ thực thi và chỉ yêu cầu 3 thông điệp cho mỗi lần sử dụng tài nguyên gồm: yêu cầu truy nhập tài nguyên, sự cho phép và giải phóng tài nguyên.
Nhược điểm:
- Nếu tiến trình điều phối bị hỏng thì hệ thống sẽ sụp đổ .Vì nếu một tiến trình đang trong trạng thái Block nó sẽ không thể biết được tiến trình điều phối có bị DEAD hay không .
- Trong một hệ thống lớn nếu chỉ có một tiến trình điều phối sẽ xuất hiện hiện tượng thắt cổ chai
3.2. Distributed Algorithm
- Khi một tiến trình muốn truy cập vào một tài nguyên chia sẻ, nó tạo một thông điệp bao gồm tên của tài nguyên, số xử lý của nó và thời gian (theo logic) hiện tại.
- Sau đó nó gửi thông điệp này tới các tiến trình khác và chính nó.
- Việc gửi các thông điệp đi là đáng tin cậy.
- Các tiến trình khác sau khi nhận được thông điệp này sẽ xảy ra ba tình huống:
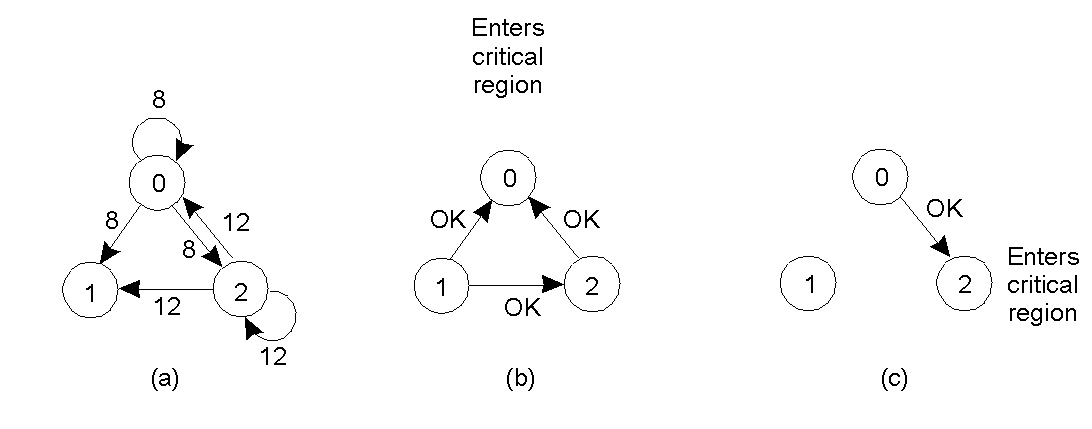
- (a) : Nếu bên nhận không ở trong tài nguyên chia sẻ và cũng không muốn vào vùng tài nguyên chia sẻ thì nó sẽ gửi thông điệp OK cho bên gửi.
- (b): Nếu bên nhận đang ở trong tài nguyên chia sẻ thay vì trả lời nó sẽ cho vào hàng đợi yêu cầu này.
- (c): Nếu bên nhận cũng muốn truy cập tài nguyên chia sẻ nhưng chưa được phép, nó sẽ so sánh nhãn thời gian (timestamp) của thông điệp gửi đến với timestamp chứa trong thông điệp mà nó gửi đi cho những tiến trình khác. Nếu thông điệp đến có timestamp thấp hơn, bên nhận sẽ gửi thông điệp OK, nếu không thì nó không gửi gì cả.
Sau khi gửi các gói tin yêu cầu cho phép, một tiến trình đợi đến khi các tiến trình khác cho phép. Ngay sau khi các tiến trình cho phép, tiến trình này được truy cập tài nguyên. Khi nó kết thúc, nó gửi 1 thông điệp OK đến tất cả các tiến trình khác ở trong hàng đợi của nó và xóa nội dung hàng đợi đó.
Ví dụ: Ở hình vẽ trên:
- Tiến trình 0 gửi 1 yêu cầu với timestamp = 8 đến tất cả các tiến trình.
- Trong cùng thời điểm đó, tiến trình 2 cũng làm tương tự với timestamp = 12.
- Tiến trình 1 không muốn truy cập tài nguyên, vì thế nó gửi OK đến cả 2 bên gửi.
- Cả tiến trình 0 và 2 nhận ra sự xung đột và cùng so sánh timestamp.
- Tiến trình 2 thua do có timestamp lớn hơn và nó phải gửi thông điệp OK đi.
- Tiến trình 0 truy cập vào tài nguyên và xếp tiến trình 2 vào hàng đợi của nó để xử lý và truy cập tài nguyên.
- Sau khi kết thúc, nó loại bỏ yêu cầu từ tiến trình 2 khỏi queue của nó và gửi thông điệp OK đến tiến trình 2 và cho phép nó thực hiện.
Nhược điểm:
- Khi tổng số lượng tiến trình trong hệ thống là n thì yêu cầu 2(n-1) thông điệp cho mỗi thực thể .
- Nếu bất cứ 1 tiến trình nào lỗi, nó sẽ gây lỗi thông điệp phản hồi yêu cầu và khiến toàn bộ các tiến trình tiến vào vùng giới hạn
- Thuật toán này chậm, phức tạp và chi phí đắt và ít mạnh mẽ như thuật toán tập trung
3.3. TokenRing Algorithm
Giả sử tất cả các tiến trình được sắp xếp trên một vòng tròn logic, các tiến trình đều được đánh số và đều biết đến các tiến trình cạnh nó.

- Bắt đầu quá trình truyền, tiến trình 0 sẽ được trao một thẻ bài.
- Thẻ bài này có thể lưu hành xung quanh vòng tròn logic.
- Nó được chuyển từ tiến trình k đến tiến trình (k+1) bằng cách truyền thông điệp điểm – điểm.
- Khi một tiến trình giành được thẻ bài từ tiến trình bên cạnh, nó sẽ kiểm tra xem có thể vào vùng tới hạn hay không. Nếu không có tiến trình khác trong vùng tới hạn nó sẽ vào vùng tới hạn.
- Sau khi hoàn thành phần việc của mình nó sẽ nhả thẻ bài ra và thẻ bài có thể di chuyển tự do trong vòng tròn.
- Nếu 1 tiến trình muốn vào vùng tới hạn thì nó sẽ giữ lấy thẻ bài, nếu không nó sẽ để cho thẻ bài truyền qua.
Nhược điểm:
- Vấn đề lớn nhất trong thuật toán này là thẻ bài có thẻ bị mất. Khi đó chúng ta phải sinh lại thẻ bài vì việc dò tìm lại thẻ bài là rất khó.
4. Election algorithm
- Khi tiến trình điều phối gặp lỗi thì sẽ phải có quá trình bầu chọn để chọn ra một tiến trình khác làm điều phối thay cho nó.
- Có hai giải thuật bầu chọn hay được sử dụng là:
- Giải thuật áp đảo (Bully Algorithm)
- Giải thuật vòng (Ring Algorithm)
4.1. Bully Algorithm
Giả sử:
- Mỗi một tiến trình đều có một ID duy nhất.
- Tất cả các tiến trình khác đều có thể biết được số ID và địa chỉ của mỗi tiến trình trong hệ thống.
- Chọn một tiến trình có ID cao nhất làm khóa.
- Tiến trình sẽ khởi động việc bầu chọn nếu như nó khôi phục lại sau quá trình xảy ra lỗi hoặc tiến trình điều phối bị trục trặc.

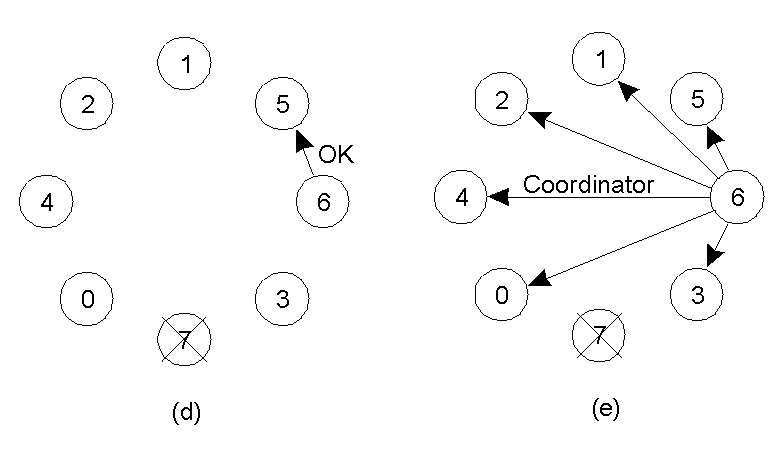
Các bước của giải thuật:
- P gửi thông điệp Election đến tất cả các tiến trình có ID cao hơn
- Nếu không có tiến trình nào phản hồi thì P sẽ trở thành tiến trình điều phối
- Nếu có một tiến trình có ID cao hơn phản hồi thì nó sẽ đảm nhiệm vai trò điều phối.
4.2. Ring Algorithm
Giả sử:
- Các tiến trình có một ID duy nhất và được sắp xếp trên 1 vòng tròn Logic.
- Mỗi một tiến trình có thể nhận biết được tiến trình bên cạnh mình.
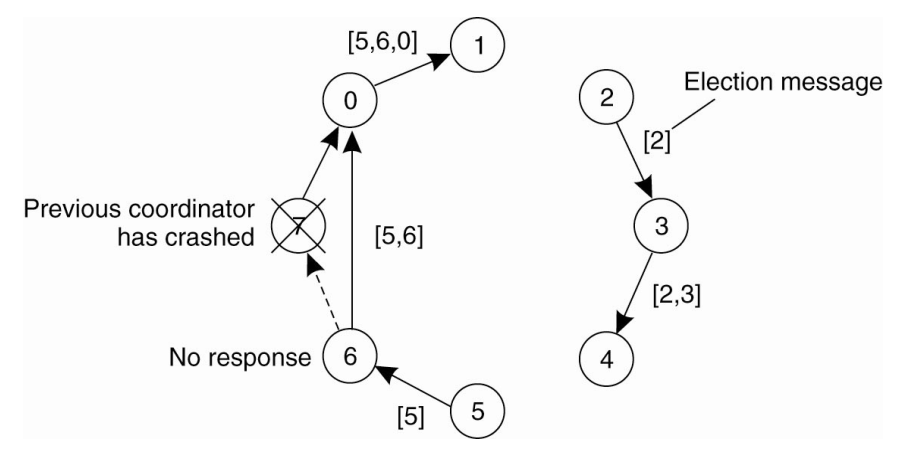
Các bước của giải thuật:
- Một tiến trình bắt đầu gửi thông điệp Election tới các nút còn tồn tại gần nhất, quá trình gửi theo 1 hướng nhất định.
- Nó sẽ thăm dò liên tiếp trên vòng cho đến khi tìm được 1 nút còn tồn tại.
- Mỗi một tiến trình sẽ gắn ID của mình vào thông điệp gửi.
- Cuối cùng sẽ chọn ra 1 tiến trình có ID cao nhất trong số các tiến trình còn hoạt động và gửi thông điệp điều phối cho tiến trình đó.
Đến đây mình xin phép kết thúc part 2 của phần Đồng bộ hóa. Hi vọng hai phần này sẽ giúp mọi người hiểu rõ hơn về cách mà các tiến trình đồng bộ hóa được với nhau trong hệ phân tán. Hẹn gặp mọi người ở phần 6 - Sao lưu và thống nhất dữ liệu
Thanks for reading
Tài liệu tham khảo: Bài giảng Hệ phân tán - ĐHBKHN

