Xin chào mọi người, chắc hẳn những ai đã từng tạo câu hỏi trên Viblo, stackoverflow, .. thì mọi người đều phải tự tạo tags cho chủ đề mình muốn hỏi để vừa nhanh có câu trả lời nhất. Tuy nhiên đôi lúc các bạn sẽ cảm thấy khá là lười biếng với việc thêm tags vào bài viết hay là quên. Vì vậy, hôm nay mình sẽ chia sẻ cho mọi người bài toán dự đoán tags cho question mà người dùng đăng lên.
Multi-Label classification là gì?
Đối với bài toán classification hẳn là khá quen thuộc đối với chúng ta, ví dụ khi bạn đưa vào một bức ảnh con mèo thì model sẽ gán nhãn của Multi_label classification bắt nguồn từ việc phân loại văn bản hay phân loại một bộ phim, như chúng ta đều biết một văn bản có thể thuộc nhiều chủ đề khác nhau hoặc là một bộ phim cũng có thể thuộc nhiều thể loại khác nhau, ... . Đối với việc phân loại văn bản thuộc những chủ để nào rất là quan trọng, ví dụ như khi bạn viết một bài viết trên trang Viblo chẳng hạn thì bài viết của bạn thuộc về chủ đề nào: python, Java, Machine Learning,... khi chúng ta đã phân loại được chủ đề thì có thể dễ dàng giúp người đọc tiếp cận được bài viết nhanh hơn hoặc bạn có thể tìm được những bài viết liên quan một cách nhanh chóng hơn. Hoặc có thể áp dụng trên một bài hát hay một bộ phim khi gán nhãn thể loại cho nó.
Một số metrics để đánh giá
Để đánh gía xem model của mình có kết quả như thế nào thì đối với multi-label và single-label thường khác nhau. Đối với single-label thì việc phân loại sẽ là mô hình của bạn gán nhãn đúng hay sai cho đầu vào của bạn, ví dụ bạn đưa vào bức ảnh dog thì nó đoán là cat thì model của bạn đang đoán sai. Tuy nhiên, đối với multi-label classification việc đánh giá này không còn là sai hay đúng, bởi vì một một đầu vào đều có thể cho ra kết quả nhiều nhãn khác nhau.
Micro-averaging & Macro-averaging
Để đo lường một multi-classs classifier chúng ta cần phải tính trung bình các lớp bằng một cách nào đó. Có 2 phương pháp được thực hiện Micro-averaging (trung bình vi mô) & Macro-averaging (trung bình vĩ mô).
Micro-averaging
Trong trung bình vi mô chúng ta tính tổng các True Positive, True Negative, False Positive, False Negative cho mỗi lớp sau đó cộng lại chia trung bình.
 Hình 1: Micro averaging
Hình 1: Micro averaging
Macro-averaging
Phương pháp Macro-average precision là trung bình cộng của các precision theo class, tương tự với Macro-average recall.
 Hình 2: Macro averaging
Phương pháp tính trung bình vĩ mô sẽ hiệu quả hơn khi bạn muốn xem cách hệ thống hoạt động trên trổng thể các tập dữ liệu. Còn trung bình vi mô có thể sẽ hữu ích khi tập dữ liệu có kích thước khác nhau. Trong phân loại nhiều lớp sẽ được ưu tiên hơn khi bạn cảm thấy nghi ngờ dữ liệu có thể có sự mất cân bằng về lớp.
Hình 2: Macro averaging
Phương pháp tính trung bình vĩ mô sẽ hiệu quả hơn khi bạn muốn xem cách hệ thống hoạt động trên trổng thể các tập dữ liệu. Còn trung bình vi mô có thể sẽ hữu ích khi tập dữ liệu có kích thước khác nhau. Trong phân loại nhiều lớp sẽ được ưu tiên hơn khi bạn cảm thấy nghi ngờ dữ liệu có thể có sự mất cân bằng về lớp.
Bạn có thể tham khảo cách tính về 2 phương pháp này tại đây. Ở đây anh Tiệp đã hướng dẫn tính một cách cực kỳ chi tiết.
Hamming-Loss
Hamming loss là tỉ lệ nhãn sai trên tổng số nhãn.
 Hình 3: Hamming loss
Hình 3: Hamming loss
Phân tích và xử lý dữ liệu
Dữ liệu ở bài toán này mình sử dụng tập dữ liệu của cuộc thi Facebook Recruiting III - Keyword Extraction
Chúng ta cùng thử phân tích xem dữ liệu gồm những gì nhé! Ở đây mình code trực tiếp trên kernel của kaggle luôn nha mn  .
.
import pandas as pd
import numpy as np
df = pd.read_csv("/kaggle/input/facebook-recruiting-iii-keyword-extraction/Train.zip")
df.head()
 Hình 4: Dữ liệu
Dữ liệu gồm 4 columns: Id, title, body, tags. Kích thước của dữ liệu (6034195, 4). Ở đây mình sẽ thử mới một subsets có size (10000, 4) cho nhanh nhé
Hình 4: Dữ liệu
Dữ liệu gồm 4 columns: Id, title, body, tags. Kích thước của dữ liệu (6034195, 4). Ở đây mình sẽ thử mới một subsets có size (10000, 4) cho nhanh nhé
Số lượng tag trong mỗi câu hỏi là bao nhiêu?
Để trả lời cho câu hỏi này chúng ta sẽ thực hiện như sau: tách ở tags và count xem.
df["tag_count"] = df["Tags"].apply(lambda x : len(x.split()))
df["tag_count"].value_counts()
 Hình 5: count tags
Dựa vào hình 5 chúng ta có thể nhận ra rằng đa phần mỗi bài đều có 2-3 tags là nhiều. Thử vẽ biểu đồ lên xem như thế nào nhé.
Hình 5: count tags
Dựa vào hình 5 chúng ta có thể nhận ra rằng đa phần mỗi bài đều có 2-3 tags là nhiều. Thử vẽ biểu đồ lên xem như thế nào nhé.
sns.countplot(df["tag_count"])
plt.title("Number of tags in questions ")
plt.xlabel("Number of Tags")
plt.ylabel("Frequency")
 Hình 5.1: chart count tags
Hình 5.1: chart count tags
Tổng số unique tags:
vectorizer = CountVectorizer(tokenizer = lambda x: x.split())
tag_bow = vectorizer.fit_transform(df['Tags'])
print("Number of questions :", tag_bow.shape[0])
print("Number of unique tags :", tag_bow.shape[1])
Vậy ta sẽ có Number of questions : 9996, Number of unique tags : 6124
Tần suất xuất hiện của các tags:
freq = tag_bow.sum(axis=0).A1
tag_to_count_map = dict(zip(tags, freq))
list = []
for key, value in tag_to_count_map.items():
list.append([key, value])
tag_df = pd.DataFrame(list, columns=['Tags', 'Counts'])
tag_df.head()
 Hình 6: tần suất xuất hiện các tag
Hình 6: tần suất xuất hiện các tag
tag_df_sorted = tag_df.sort_values(['Counts'], ascending=False)
plt.plot(tag_df_sorted['Counts'].values)
plt.grid()
plt.title("Distribution of frequency of tags based on appeareance")
plt.xlabel("Tag numbers for most frequent tags")
plt.ylabel("Frequency")
 Hình 6.1: Distribution prequency
Hình 6.1: Distribution prequency
Vẽ word map show cho chất nào =))
tag_to_count_map
tupl = dict(tag_to_count_map.items())
word_cloud = WordCloud(width=1600,height=800,).generate_from_frequencies(tupl)
plt.figure(figsize = (12,8))
plt.imshow(word_cloud)
plt.axis('off')
plt.tight_layout(pad=0)
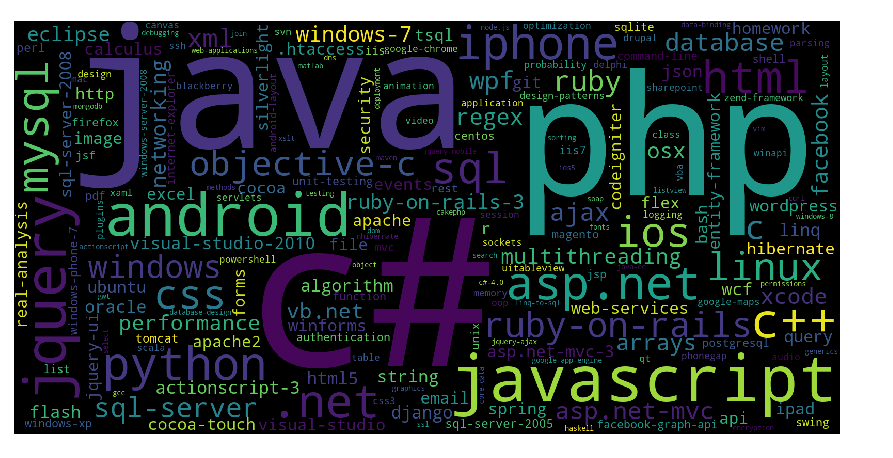
Hình 7: word map
Dựa vào word map ở hình 7 chúng ta có thể nhận thấy có một số tags phổ biến (tần suất xuất hiện nhiều nhất) như: "c#", "java", "php", "android", "javascript", "jquery", "C++"
cùng xem 20 tags có tần suất nhiều nhất:
i=np.arange(20)
tag_df_sorted.head(20).plot(kind='bar')
plt.title('Frequency of top 20 tags')
plt.xticks(i, tag_df_sorted['Tags'])
plt.xlabel('Tags')
plt.ylabel('Counts')
plt.show()
 Hình 8: 20 tags có tần suất xuất hiện nhiều nhất
Hình 8: 20 tags có tần suất xuất hiện nhiều nhất
Xử lý text
stop_words = set(stopwords.words('english'))
stemmer = SnowballStemmer("english")
Tiến hành loại bỏ một số ký tự đặc biệt và code trong content:
qus_list=[]
qus_with_code = 0
len_before_preprocessing = 0
len_after_preprocessing = 0
for index,row in df.iterrows():
title, body, tags = row["Title"], row["Body"], row["Tags"]
if '<code>' in body:
qus_with_code+=1
len_before_preprocessing+=len(title) + len(body)
body=re.sub('<code>(.*?)</code>', '', body, flags=re.MULTILINE|re.DOTALL)
body = re.sub('<.*?>', ' ', str(body.encode('utf-8')))
title=title.encode('utf-8')
question=str(title)+" "+str(body)
question=re.sub(r'[^A-Za-z]+',' ',question)
words=word_tokenize(str(question.lower()))
question=' '.join(str(stemmer.stem(j)) for j in words if j not in stop_words and (len(j)!=1 or j=='c'))
qus_list.append(question)
len_after_preprocessing += len(question)
df["question"] = qus_list
avg_len_before_preprocessing=(len_before_preprocessing*1.0)/df.shape[0]
avg_len_after_preprocessing=(len_after_preprocessing*1.0)/df.shape[0]
preprocessed_df = df[["question","Tags"]]
print("Shape of preprocessed data :", preprocessed_df.shape)
preprocessed_df.head()

 Hình 9: content sau khi đã được làm sạch
Hình 9: content sau khi đã được làm sạch
Xử lý tags
vectorizer = CountVectorizer(tokenizer = lambda x: x.split(), binary='true')
y_multilabel = vectorizer.fit_transform(preprocessed_df['Tags'])
def tags_to_consider(n):
tag_i_sum = y_multilabel.sum(axis=0).tolist()[0]
sorted_tags_i = sorted(range(len(tag_i_sum)), key=lambda i: tag_i_sum[i], reverse=True)
yn_multilabel=y_multilabel[:,sorted_tags_i[:n]]
return yn_multilabel
def questions_covered_fn(numb):
yn_multilabel = tags_to_consider(numb)
x= yn_multilabel.sum(axis=1)
return (np.count_nonzero(x==0))
questions_covered = []
total_tags=y_multilabel.shape[1]
total_qus=preprocessed_df.shape[0]
for i in range(100, total_tags, 100):
questions_covered.append(np.round(((total_qus-questions_covered_fn(i))/total_qus)*100,3))
yx_multilabel = tags_to_consider(1000)
print("Number of tags in the subset :", y_multilabel.shape[1])
print("Number of tags considered :", yx_multilabel.shape[1],"(",(yx_multilabel.shape[1]/y_multilabel.shape[1])*100,"%)")


Thực hiện training
Chia tập train và test thành 2 phần với tỉ lệ là 80:20
X_train, X_test, y_train, y_test = train_test_split(preprocessed_df, yx_multilabel, test_size = 0.2,random_state = 42)
vectorizer = TfidfVectorizer(min_df=0.00009, max_features=200000, tokenizer = lambda x: x.split(), ngram_range=(1,3))
X_train_multilabel = vectorizer.fit_transform(X_train['question'])
X_test_multilabel = vectorizer.transform(X_test['question'])
Fit Logistic Regression với OneVsRest Classifier
clf = OneVsRestClassifier(SGDClassifier(loss='log', alpha=0.00001, penalty='l2'))
clf.fit(X_train_multilabel, y_train)
y_pred = clf.predict(X_test_multilabel)
 Hình10: So sánh thử 1 bài xem sao.
Hình10: So sánh thử 1 bài xem sao.
Ở Hình trên chúng ta test thử thì nhận thấy đúng 2/3 tags có vẻ ổn nhỉ?
xem xem kết quả score như nào nhé:
print("Accuracy :",metrics.accuracy_score(y_test,y_pred))
print("Macro f1 score :",metrics.f1_score(y_test, y_pred, average = 'macro'))
print("Micro f1 scoore :",metrics.f1_score(y_test, y_pred, average = 'micro'))
print("Hamming loss :",metrics.hamming_loss(y_test,y_pred))
 Hình11: kết quả
Hình11: kết quả
Kết quả không đc tốt lắm do mình mới chỉ lấy 10000 sample thôi
Kết Luận
Bài viết này mình viết với mục đích review lại kiến thức và cũng để chia sẻ cho những bạn cần và đang tìm hiểu về multi-label classification. Nếu có gì sai sót mong nhận được sự góp ý của mọi người. Và nhớ upvoted cho mình nha =))
Reference
https://towardsdatascience.com/journey-to-the-center-of-multi-label-classification-384c40229bff
https://www.kaggle.com/vikashrajluhaniwal/multi-label-classification-for-tag-predictions


