Các bạn có thể xem đầy đủ các phần tại đây nhé
Đầu tiên mình định dịch ra là nút lá, nhưng nghe nó không được hay cho lắm nên quyết định giữ nguyên tên của nó là Leaf Nodes.
Mục đích của Index là để lưu trữ dữ liệu đã được sắp xếp theo thứ tự. Nếu ta lưu dữ liệu theo kiểu vật lý, với các cục index này nằm cạnh cục index kia theo thứ tự, thì nếu một ngày đẹp trời có một lệnh INSERT muốn chèn một cục index vào giữa thì điều gì sẽ xảy ra? Tất cả các cục index phía sau sẽ bị đẩy về sau để lấy chỗ cho cục index này chèn vào, việc này tốn rất nhiều thời gian và lệnh INSERT sẽ chạy siêu chậm.
Giải pháp để khắc phục vấn đề này là mấy ông làm ra cơ sở dữ liệu sẽ không lưu thứ tự tuần tự theo vật lý mà xây dựng một kiểu dữ liệu logic đảm báo thứ tự giữa các cục index độc lập với việc cục index này được lưu ở đâu trong bộ nhớ.
Cấu trúc dữ liệu cho vấn đề này là một danh sách liên kết đôi (doubly linked list.)
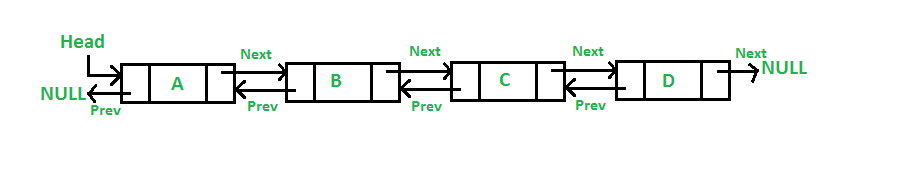
Cấu trúc của nó như một sợi xích, mỗi một mắt xích đều liên kết tới mắt trước mắt sau của nó. Nếu bạn cần chèn một node vào giữa hai node thì chỉ cần cập nhật lại liên kết của hai node đó là được, các node khác không ảnh hưởng gì. Node mới lưu ở chỗ nào đó xa xa hay gần hai node kia cũng được, miễn là trỏ đúng thì thứ tự của linked list vẫn đảm báo bình thường.
Với cấu trúc dữ liệu này database có thể đọc index từ đầu tới đuôi, hoặc từ đuôi tới đầu. Cấu trúc dữ liệu này cũng tương đối phổ biến (được học trong môn cấu trúc dữ liệu này) được mang đi trong các ngôn ngữ lập trình ví dụ:
| Ngôn ngữ lập trình | Tên thư viện |
|---|---|
| Java | java.util.LinkedList |
| .NET Framework | System.Collections.Generic.LinkedList |
| C++ | http://www.cplusplus.com/reference/list/list/ |
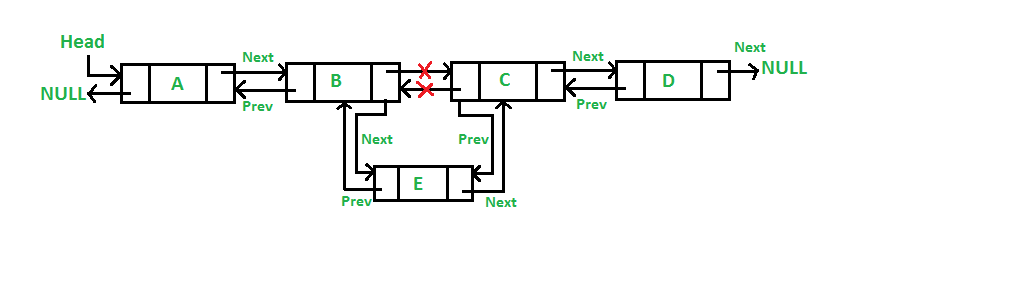
Database có sử dụng mỗi cục index là một node trong danh sách liên kết không không? Đáp án là không. Mỗi một node trong danh sách liên kết này có thể chứa một hoặc nhiều cục index, mỗi node được gọi là index leaf nodes. Tại sao lại như vậy? Bởi vì đơn vị lưu trữ nhỏ nhất của một database là page hoặc block, dung lượng của nó thường to hơn dung lượng của một index (thường cố định tầm vài kilobyte), database dùng các khoảng trống còn lại trong các block này để chèn thêm vài cục index vào cho khỏi lãng phí. Vì vậy trong mỗi node thường có vài cục index chứ không phải một cục. Vậy khi insert một cục index mới vào giữa hai cục trong cùng một leaf node thì sao? không phải lại như ban đầu là dịch các cục index sau đi à? có tốn hiệu năng không? Đáp án là đúng thế (hoặc chắc thế, tùy db sẽ hành xử khác nhau), nhưng như ban đầu thì cần dịch tất cả các cục index của toàn bộ index, còn ở đây chỉ cần dịch các cục trên một node hoặc vài node thôi nên hiệu năng nếu có ảnh hưởng thì không đáng kể.
Tóm lại ta có thứ tự của index được duy trì bởi hai điều, một là các cục index trong cùng một leaf node và hai là các leaf node liên kết với nhau bởi danh sách liên kết.
!
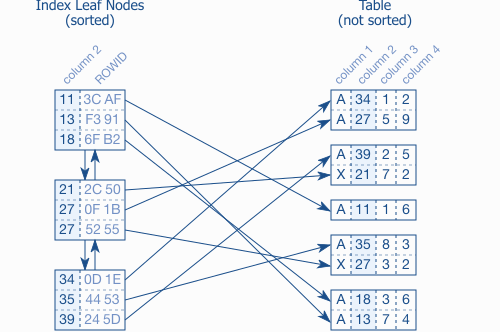
Trong hình trên mô tả index leaf nodes và liên kết của nó với table data, mỗi cục index bao gồm một index column(key, column2) và một liên kết tương ứng tới table row (qua ROWID hoặc RID). Khác với index, table được lưu trong heap nên chả có tý thứ tự nào. Các row trong cùng một block lẫn ở các block khác nhau cũng không có tý liên hệ nào với nhau cả.
Nhưng mà nếu index chỉ được lưu trữ thế này, nếu tìm dữ liệu không phải cũng phải duyệt từ đầu đến cuối à? Thế có nhanh hơn tý nào đâu? Đáp án của tốc độ thần thánh của index sẽ được mô tả trong bài sau B-Tree. Bây giờ cũng muộn rồi mình đi ngủ đây. Bài sau B-Tree



