Lời mở đầu
CNN (Convolutional Neural Network) lần đầu được ra mắt và áp dụng vào bài toán Classification (phân loại) là LeNet-5 vào năm 1989 của nhóm nghiên cứu của thầy Yann LeCun. Và với sự ra mắt tiếp đó của AlexNet vào năm 2012, chiến thắng cuộc thi phân loại ảnh ImageNet, CNN đã dần có được sự thống trị của mình trong các bài toán phân loại ảnh. Rất nhiều các kiến trúc CNN mới ra đời như VGG, Inception, ResNet, DenseNet,... và gần đây nhất là ConvNext.
Tuy nhiên, những sự phát triển vượt bậc này không chỉ nằm ở trong mỗi kiến trúc của chúng. Những thay đổi trong quá trình training, bao gồm những sự thay đổi trong hàm loss, cách xử lý dữ liệu, các phương pháp optimization khác nhau cũng đóng một vai trò vô cùng quan trọng. Những thay đổi này giống như những sát thủ thầm lặng, chỉ được nhắc tới rất ngắn trong các paper hoặc thậm chí là không nhắc tới, mà phải đọc source code mới có thể tìm ra, và cũng nhận được rất ít những sự quan tâm.
Hôm nay, chúng ta sẽ khám phá những thay đổi này, giúp cải thiện độ chính xác của model mà hầu như không làm tăng độ nặng tính toán. Có khá nhiều những thay đổi vô cùng nhỏ nhặt, được gọi là "tricks" (thủ thuật), như thay đổi stride trong lớp Convolution, thay đổi learning rate. Tuy nhiên, kết hợp nhiều thay đổi nhỏ sẽ tạo ra được sự thay đổi lớn. Chúng ta sẽ đánh giá những thay đổi này trên một số CNN và tìm hiểu tác động của chúng.
Quy trình training

Một mạng nơ-ron train với Stochastic Gradient Descent (SGD) sẽ tuân theo quy trình training như thuật toán 1.
Baseline cho quy trình training
Chúng ta cần một quy trình training baseline dùng để làm so sánh với sự thay đổi trong các quy trình về sau. Tiền xử lý dữ liệu trong lúc train và validation sẽ khác nhau. Trong lúc train, ta thực hiện tuần tự các bước sau:
- Lấy ngẫu nhiên ảnh, xử lý ảnh thành dạng float cho từng pixel với giá trị trong khoảng [0, 255].
- Ngẫu nhiên crop một vùng chữ nhật có tỉ lệ được lấy ngẫu nhiên trong khoảng [, ], diện tích của vùng được lấy ngẫu nhiên trong khoảng [%, %], sau đó được resize thành ảnh vuông với kích thước .
- Sử dụng Horizontal Flip với tỉ lệ
- Thay đổi hue, staturation và brightness với hệ số được lấy ngẫu nhiên trong khoảng [, ].
- Thêm nhiễu PCA với hệ số được lấy từ phân phối chuẩn
- Normalize kênh màu RGB bằng việc trừ đi và chia cho
Trong lúc validation, ta resize cạnh ngắn hơn của ảnh xuống , cạnh còn lại được resize theo tỉ lệ của ảnh. Sau đó, ta crop ra một vùng ở trung tâm của ảnh và normalize RGB y như lúc training.
Weight của các lớp Convolution và Fully-Connected (FC) được khởi tạo ngẫu nhiên theo thuật toán Xavier. Với các lớp BatchNorm (BN), được khởi tạo là và được khởi tạo là .
Nesterov Accelerated Gradient (NAG) Descent được sử dụng trong training. Model được train với 120 epochs, sử dụng 8 GPU V100 với tổng batch size là 256. Learning rate được khởi tạo là 0.1 và giảm đi mỗi 10 lần ở epoch thứ 30, 60 và 90.
Kết quả baseline
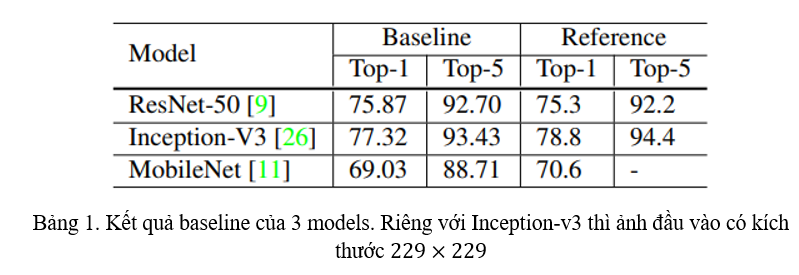
Áp dụng training đối với 3 model: ResNet-50, Inception-v3 và MobileNet. Kết quả được thể hiện ở Bảng 1.
Training một cách hiệu quả
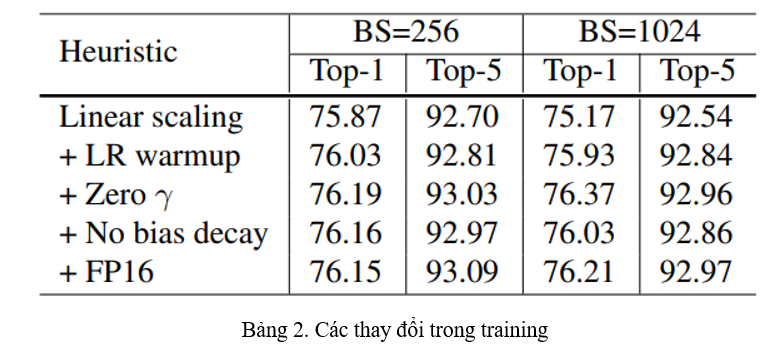
Training với batch size khác nhau
Vì mỗi máy tính sẽ có các cấu hình phần cứng khác nhau, nên chúng ta phải điều chỉnh batch size để phù hợp với phần cứng đó. Tuy nhiên, việc điều chỉnh batch size khác nhau sẽ đem lại những ảnh hưởng đến độ chính xác của mô hình chúng ta. Để có thể thay đổi batch size mà vẫn có độ chính xác tốt, các kĩ thuật dưới đây sẽ giúp chúng ta đạt được điều đó.
Linear scaling learning rate
Trong mini-batch SGD, gradient descent là một quá trình ngẫu nhiên vì data được lấy ngẫu nhiên ở mỗi batch. Việc tăng batch size sẽ không thay đổi kì vọng của SGD nhưng sẽ làm giảm phương sai. Nói cách dễ hiểu hơn là, việc có một batch size lớn hơn sẽ giảm đi nhiễu ở trong các lần đạo hàm, vì vậy, ta cần phải tăng learning rate để quá trình hội tụ của SGD hiệu quả hơn. Giả sử learning rate ban đầu là với batch size là 256, khi chuyển sang batch size là learning rate mới sẽ được tính theo công thức .
Learning rate warmup
Khi bắt đầu training, các tham số thường được khởi tạo ngẫu nhiên và sẽ khác rất nhiều so với tham số cuối cùng của model. Vì vậy, việc sử dụng một learning rate lớn thường sẽ gây khó khăn cho việc hội tụ ở giai đoạn đầu. Từ đó sinh ra giai đoạn "warmup", ta sẽ sử dụng một learning rate nhỏ rồi chuyển lại về learning rate ta muốn khi mà model đã đạt được một sự ổn định. Giả sử ta sử dụng epoch đầu tiên để warmup, learning rate ta muốn là , thì tại batch thứ với , learning rate sẽ tính theo công thức .
Zero
ResNet bao gồm các Residual Block, mỗi Residual Block bao gồm một vài lớp Convolution. Với đầu vào , gọi là đầu ra của lớp cuối cùng trong Residual Block, thì đầu ra của cả Residual Block sẽ là . Lưu ý rằng lớp cuối cùng trong Residual Block có thể là BatchNorm (BN). BN trước tiên sẽ standardize , tạo ra , sau đó thực hiện biến đổi theo công thức . Cả và đều là các tham số học được và thường được khởi tạo với giá trị và . Với việc khởi tạo là cho toàn bộ các lớp BN ở cuối Residual Block, các Residual Block sẽ trả lại luôn giá trị đầu vào của chúng là , làm cho model như có ít lớp hơn, do đó sẽ dễ train hơn ở các giai đoạn đầu.
No bias decay
Chúng ta thường áp dụng weght decay cho các parameters, bao gồm cả weight và bias. Việc này giống như sử dụng L2 regularization lên các parameters. Tuy nhiên, có các nghiên cứu đã chỉ ra rằng chỉ nên áp dụng regularization lên weight để tránh overfitting. Vì vậy, chiến lược no bias decay chỉ áp dụng weight decay lên weight của các lớp convolution và FC. Các parameter khác như và trong lớp BN không được áp dụng.
Kết quả
Tinh chỉnh model
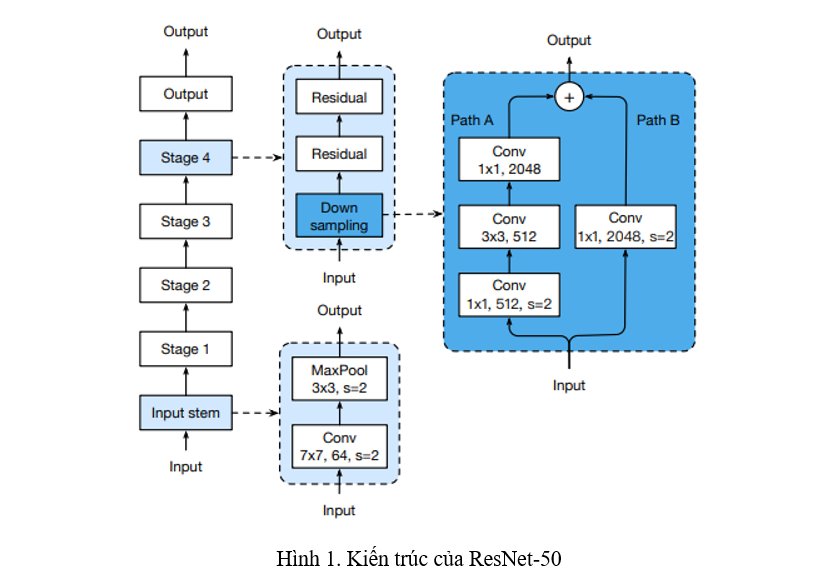
Tinh chỉnh model là những thay đổi vô cùng nhỏ đến cấu trúc của mạng nơ-ron, chẳng hạn như thay đổi stride trong một lớp Convolution. Những thay đổi vô cùng nhỏ đó sẽ không ảnh hưởng đáng kể đến tốc độ của model nhưng lại có thể đem lại một vài thay đổi không nhỏ đến độ chính xác của model. Trong mục này, ta sẽ cải tiến ResNet-50 (Hình 1) để cho thấy sự hiệu quả của việc tinh chỉnh model.
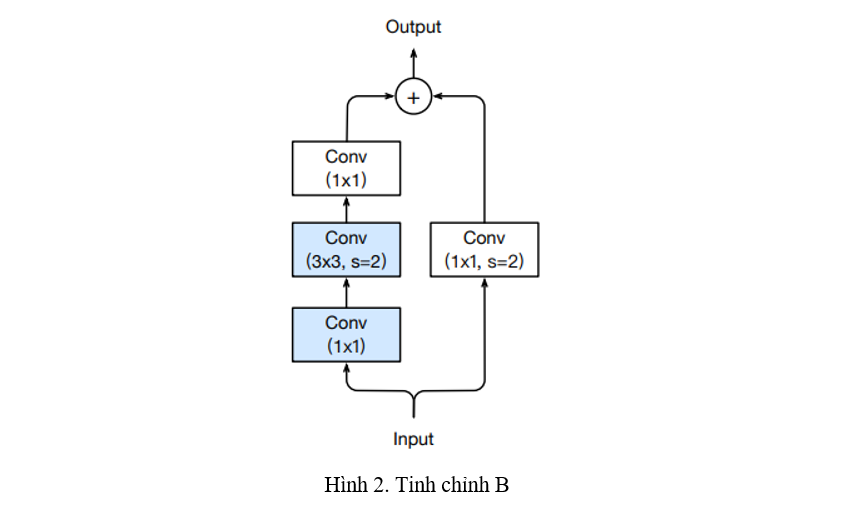
Tinh chỉnh B (Hình 2)
Cải tiến B thay đổi khối Down sampling của ResNet. Quan sát thấy rằng việc sử dụng Convolution với stride 2 trong Path A sẽ làm mất rất nhiều thông tin từ Feature map đầu vào, ResNet-B đổi stride trong Convolution thành 1, stride trong Convolution thành 2 và đảm bảo đầu ra từ Path A vẫn giữ nguyên kích thước.
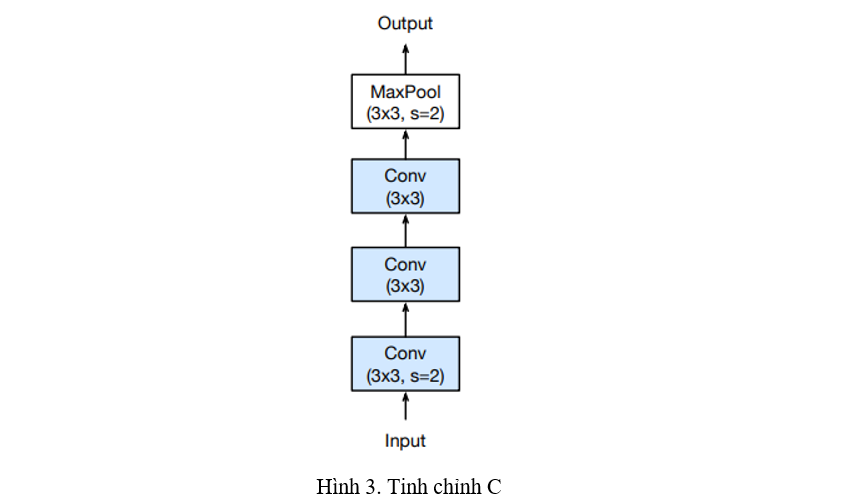
Tinh chỉnh C (Hình 3)
Quan sát thấy khối lượng tính toán của lớp Convolution gấp 5.4 lần so với lớp Convolution . Tinh chỉnh này thay đổi Input stem, thay thế lớp Convolution thành 3 lớp Convolution . Điều này giúp trích xuất thông tin tốt hơn mà không làm tăng độ phức tạp tí
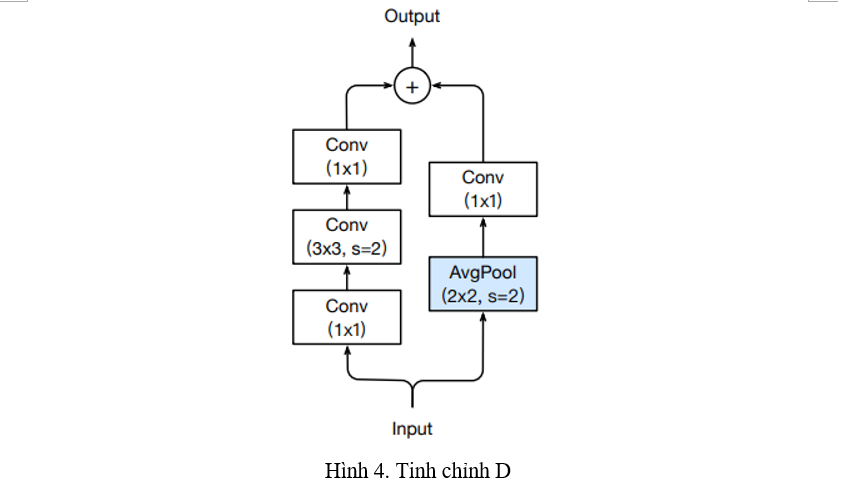
Tinh chỉnh D (Hình 4)
Trong khối Down sampling của ResNet, ở Path B cũng sử dụng Convolution với stride 2 gây mất đi nhiều thông tin. Tinh chỉnh này thêm vào một lớp Average Pooling với stride 2 trước Convolution, và thay stride của lớp Convolution thành 1.
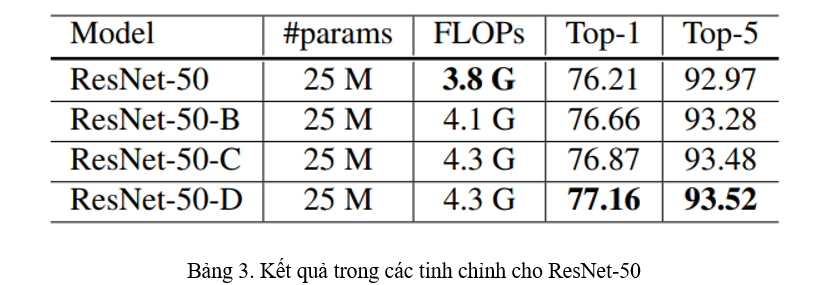
Kết quả
Cải tiến training
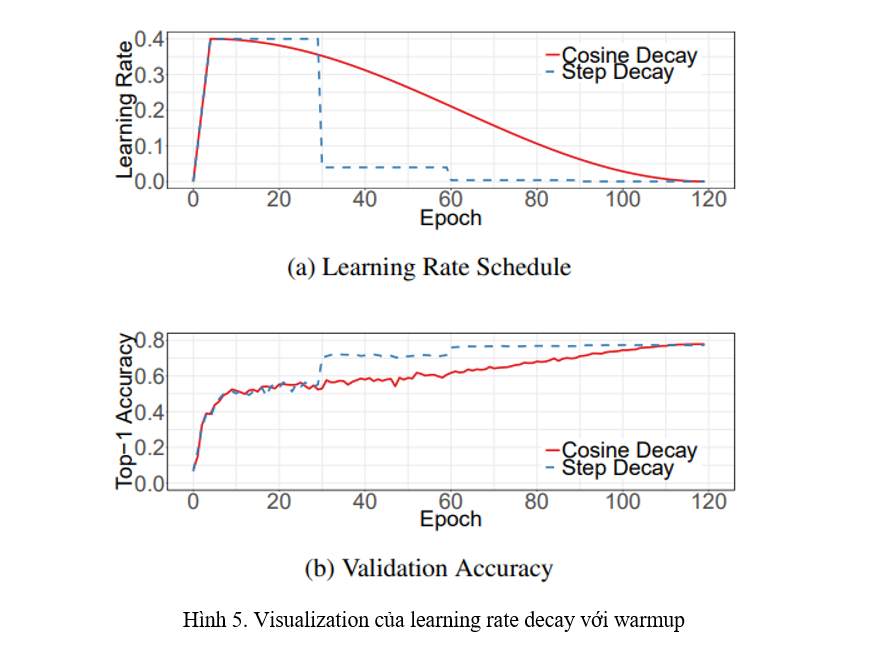
Learning rate decay (Hình 5)
Việc lựa chọn learning rate đúng là cực kì quan trọng. Sau learning rate warmup đã nhắc tới ở trên, ta sẽ giảm từ từ learning rate. Chiến thuật giảm learning rate đơn giản hay được lựa chọn là:
- Giảm 0.1 learning rate mỗi 30 epochs, gọi là step decay
- Giảm 0.94 learning rate mỗi epoch
Một chiến thuật nữa là giảm learning rate theo hàm . Giả dụ tổng số batch là (bỏ qua warmup), thì ở tại batch thứ , learning rate được tính theo công thức:
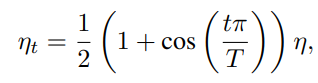
với là learning rate lựa chọn. Chiến thuật này được gọi là Cosine Annealing.
Label smoothing
Lớp cuối cùng của một mạng nơ-ron phân loại thường là một lớp FC với số unit bằng số class, kí hiệu là , để sinh ra giá trị dự đoán. Với một ảnh đầu vào, mạng nơ-ron sẽ sinh ra giá trị dự đoán cho class kí hiệu là . Giá trị dự đoán này có thể được normalized sử dụng softmax để thu được xác suất dự đoán của từng class. Gọi là output của softmax với , xác suất của class , có thể được tính theo công thức:
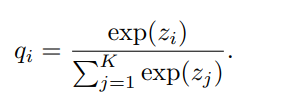
Có thể dễ dàng thấy là và nên có thể coi là một phân phối.
Mặt khác, giả dụ ground truth label cho ảnh là , ta có thể dựng một phân phối xác suất ground truth cho nếu và nếu ngược lại. Trong training, mục tiêu của ta là minimize Cross Entropy (CE) loss.
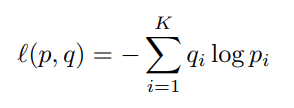
để làm cho 2 phân phối là phân phối dự đoán từ model và phân phối ground truth trở nên giống nhau. Cụ thể hơn, qua cách xây dựng , ta thấy . Kết quả tối ưu nhất sẽ là . Nói cách khác, việc này khuyến khích các class khác nhau trở nên cực kì phân biệt với nhau, do đó có thể dẫn tới overfitting.
Ý tưởng về label smoothing được giới thiệu ở trong Inception-v2. Nó thay đổi cách biểu diễn ground truth label thành dạng:
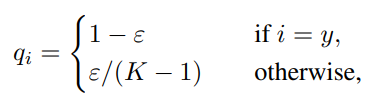
với là một hằng số nhỏ. Lúc này, kết quả tối ưu sẽ trở thành:
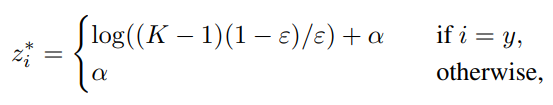
với là một số thực bất kì. Điều này khiến kết quả từ lớp FC sẽ generalized tốt hơn.
Knowledge distillation
Trong knowledge distillation, ta sử dụng một teacher model để giúp đỡ train model hiện tại, gọi là student model. Teacher model thường là một model được pre-trained với accuracy cao, để giúp student model cải thiện accuracy mà độ phức tạp của student model vẫn giữ nguyên.
Trong training, ta thêm vào distillation loss để phạt sự khác nhau giữa output từ teacher và student. Cho trước một input, giả sử là phân phối ground truth, và là output của student model và teacher model. Ta sẽ dùng CE loss làm distillation loss theo công thức như sau:
![]()
với là hyper-parameter để làm mượt output của softmax để chắt lọc kiến thức từ kết quả dự đoán của teacher.
Mixup training
Trong phần baseline cho training, đầu vào đã được đi qua một số augmentations. Ở đây, ta sử dụng thêm một phương pháp augmentation nữa gọi là MixUp. Trong MixUp, ta sẽ lấy ngẫu nhiên 2 mẫu dữ liệu và , sau đó tạo nên một mẫu dự liệu mới theo công thức kết hợp:

với được lấy ngẫu nhiên theo phân phối .
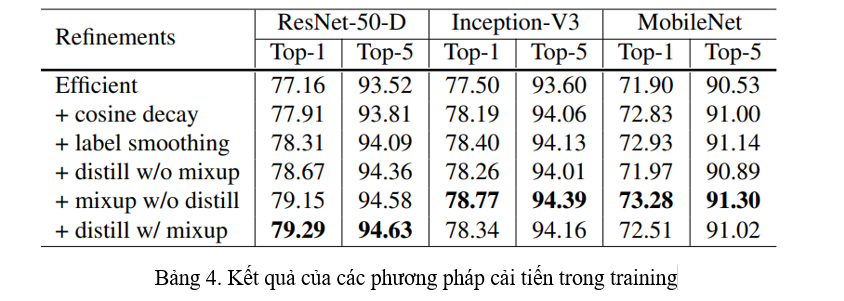
Kết quả
TL;DR
Phía trên là những phân tích rất dài, trình bày sơ qua những phương pháp đó là gì, áp dụng ra sao và có ảnh hưởng tới kết quả của một model Classification như nào. Tuy nhiên, có một số những phương pháp khá dễ áp dụng và đạt hiệu quả ổn định mà mình đã có dịp sử dụng qua dưới đây:
- Learning rate warmup: Cho learning rate tăng từ từ ở những epoch đầu
- Learning rate decay: Learning rate sẽ giảm theo thời gian
- Label smoothing: thay vì sử dụng one-hot encode thì label sẽ được smooth hơn, tránh overfitting
- Áp dụng các phương pháp augmentation phù hợp với bộ dữ liệu sử dụng: đây là một phương pháp mình thấy cực kì đơn giản mà độ hiệu quả mang lại khá cao
Hy vọng các bạn có thể áp dụng được những phương pháp nói trên vào các bài toán Image Classification của mình và đem lại hiệu quả tốt.



