1. Giới thiệu về bài toán Automatic Object Removal
Trong thời đại bùng nổ của kĩ thuật số, đặc biệt sự phát triển vượt bậc của các nền tảng mạng xã hội. Nhu cầu về chia sẻ hình ảnh, hay thiết kế ấn phẩm đang ngày càng được chú trọng quan tâm hơn.
Chính vì vây, các ứng dụng liên quan đến chỉnh sửa hình ảnh là rất cần thiết. Trong đó, Xoá vật thể không mong muốn, dư thừa là một trong những thao tác phổ biến khi chỉnh sửa ảnh. Không chỉ dành riêng với các nhà photoshop chuyên nghiệp, mà ngay đến những người dùng bình thường cũng đã có nhu cầu sử dụng cao.

Hình 1: Người (ô màu đỏ) là thứ bạn muốn xóa.
1.1. Input và Output của bài toán
Xoá đối tượng trong ảnh (Object Removal), cụ thể là xoá đối tượng người dùng muốn xoá, xoá đối tượng dư thừa. Đó là một thao tác thường được sử dụng trong chỉnh sửa ảnh.
- Input: Đưa vào một bức ảnh với kích thước bất kỳ, nhập loại đối tượng bạn muốn xoá.
- Output: Một bức ảnh sau khi đã xoá đối tượng và có cùng kích thước với bức ảnh đầu vào.
![]() Hình 2: Input và Output của bài toán.
Hình 2: Input và Output của bài toán.

1.2. Hướng tiếp cận của bài toán
Khi tìm hiểu của các bên khác triển khai bài toán này, ví dụ như Tool Content-Aware Fill trong phần mềm Photoshop, Remove Objects from Photos Online with Ease | PicsArt, ... mình nhận thấy rằng: Mỗi ứng dụng tuy có cách triển khai khác nhau, đi từ đơn giản cho đến phức tạp nhưng nhìn tổng quan các ứng dụng đều có chung một cách giải quyết:

Hình 3: Hướng tiếp cận của bài toán.
Ngoài ra, cũng có khá nhiều các paper đã ra mắt, nghiên cứu về phần này. Có thể kể đến như:
- Phương pháp Adversarial Scene Editing: Automatic Object Removal from Weak Supervision[1]: Phương pháp này là một mô hình được phát triển từ mạng GAN (Generative Adversarial Networks) thông qua các nhãn theo cấp của ảnh mà không cần các thông tin về hộp giới hạn (boundary box) hay vùng đối tượng (mask).
- Ứng dụng Person Remover: People removal in images using Pix2Pix and YOLO[2]: Xác định đối tượng bằng mô hình YOLO, sau đó từ ảnh cut đối tượng, ta chạy qua mô hình Pix2Pix để sinh ra ảnh mới. (lúc đầu mình cũng làm theo cách này, nhưng mà ôi giời ôi, đến đoạn training Pix2Pix thì không được như mơ 😁)
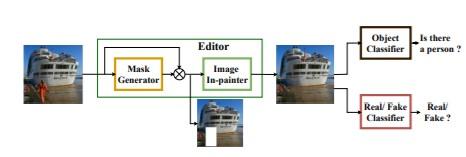
Hình 4: Kiến trúc của phương pháp Adversarial Scene Editing.
Mỗi phương pháp kể trên đều có những ưu, nhược điểm của riêng nó như:
- Phương pháp tạo vùng (mask) của Adversarial Scene Editing cho kết quả tốt hơn với việc sử dụng YOLO. Bằng chứng là các vùng bị xoá sẽ nhỏ hơn thay vì một ô vuông như bài toán Person Remover. Kết quả khi sử dụng mask rõ ràng tốt hơn.
- Sử dụng 2 model riêng biệt như bài toán Person Remover lại có vẻ tốt cho việc cải tiến. Dễ dàng có thể đào tạo lại để có kết quả tốt 1 trong 2 model.
Từ những điểm này, mình xin đề xuất phương pháp tiếp cận mới, lấy được các ưu điểm của 2 phương pháp trên. Đó là:
- Sử dụng DeepLabv3 hoặc FCN để Phân vùng ảnh, hình dáng chi tiết của mọi đối tượng có trong ảnh.
- Sau đó sử dụng thuật toán Candy để sinh ra Edge, tiền xử lý để vẽ lại mask những object cần xoá.
- Cuối cùng, chạy tất cả qua Image Inpainting (model được chọn là EdgeConnect, để lấp đầy vùng cần xoá, ảnh đầu ra không còn chứa các đối tượng mình mong muốn mà nhìn vẫn rất tự nhiên.
2. Cách giải quyết bài toán
Vì những mô hình Image Segmentation như DeepLabV3, FCN, ... đã quá quen thuộc rồi nên mình xin phép không đề cập đến, mà đi thẳng vào phần chính của chúng ta.
2.1. Mô hình EdgeConnect
2.1.1. Ý tưởng của mô hình
“Lines first, color next” hiểu theo nghĩa đơn giản đó là đường nét trước, màu sắc tiếp theo. Đây là cách mà các nghệ sĩ làm việc, tạo nên bức tranh của mình. Rõ ràng, để hoàn thành một tác phẩm, người nghệ sĩ sẽ phải tạo phác thảo bố cục cho bức ảnh trước. Các cạnh, đường đóng vai trò quan trọng tạo dựng không gian, hình dạng của đối tượng trong cảnh.
Từ điều đó, tác giả của mô hình tin rằng: mô hình cải thiện và tạo ra các chi tiết tốt, trước hết cần cải thiện cấu trúc hình ảnh thông qua cạnh của nó. Việc tạo cạnh, là một nhiệm vụ dễ dàng hơn so với các nhiệm vụ khác.

Hình 5: Input đầu vào, tạo cạnh và kết quả của mạng.
2.1.2. Kiến trúc của mô hình
Mô hình EdgeConnect được chia thành hai phần:
- Edge Generation: tập trung việc tạo các cạnh ảo ở các vùng missing pixel. (như bức ảnh giữa hình 5 - phần màu đen là được vẽ bằng Canny Edge Detector, phần màu xanh là do Edge Generation sinh ra)
- Image Completion: sử dụng các cạnh ảo và ước tính cường độ pixel RGB cho các vùng missing pixel để sinh ra 1 ảnh hoàn chỉnh.
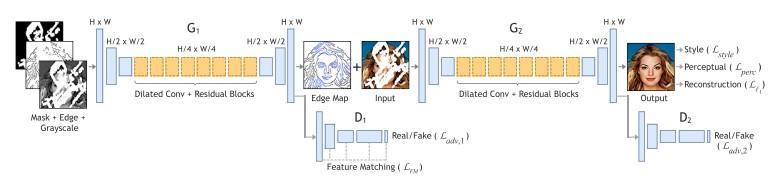
Hình 6: Kiến trúc của mô hình EdgeConnect.
Về chi tiết cách xây dựng mô hình, hàm loss và training đánh giá, tác giả cũng đã nói rõ trong paper, bạn nào hứng thú có thể đọc tìm hiểu nhá!
Ngoài ra, về các chỉ số đánh giá tác giả sử dụng trong paper, hay xa hơn là cho các bài toán Image Generation, mình cũng đã có một bài viết trên viblo nói về phần này 😁
Link bài ở đây nhá: https://viblo.asia/p/cac-chi-so-danh-gia-duoc-su-dung-cho-bai-toan-image-generation-is-fid-psnr-ssim-XL6lA0zDZek
2.2.Xây dựng bài toán automatic object removal
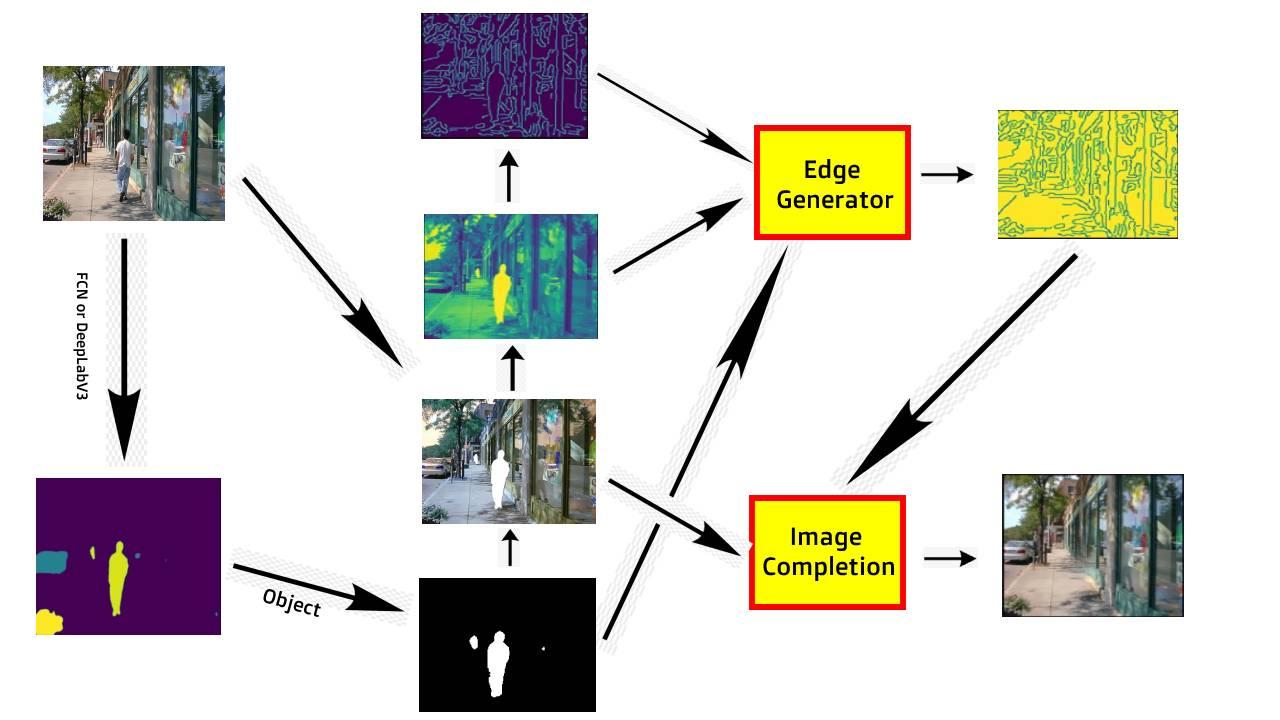
Hình 7:Hướng giải quyết bài toán Xóa vật thử tự động.
Trình tự thực hiện như sau:
- Đầu tiên, cho một ảnh bất kỳ chứa đối tượng cần xóa (ví dụ hình 6 là mình muốn xóa người trong hình)
- Tiếp theo, chạy qua mô hình DeepLabV3 hoặc FCN để ra được một mask như hình (các bạn cũng có thể chọn các mô hình khác để thay thế, sở dĩ mình chọn vì nó có sẵn trong Torchvision của Pytorch, chỉ cần lôi ra dùng thôi 😁)
- Tiếp đến, xử lý output của mô hình segment: tạo mask mới chỉ chứa mỗi object cần xóa, tạo ảnh xám, tạo ảnh chứa cạnh.
- Cuối cùng, cho chạy qua mô hình EdgeConnect gồm 2 phần Edge Generator và Image Completion (như hình 6)
- Kết quả, sẽ tạo ra một bức ảnh mới đã hoàn toàn xóa người 😋.
2.3.Thực nghiệm
Sau khi đã xây dựng xong, và đây là kết quả mình test với một số ảnh:


Nhận xét:
- Tuy đã giải quyết được khá nhiều vấn đề của bài toán Image Generation, nhưng thời gian xử lý còn khá là lâu, khoảng 25-35s. Điều này, có thể cải thiện bằng việc thay đổi mô hình phần segment, chuyển mô hình EdgeConnect về dạng TensorRT, ...
- Bài toán chỉ có thể xoá được đối tượng trong ảnh, còn cụ thể đối tượng đó là gì thì chưa xoá được (ví dụ cùng là 1 bức ảnh có 2 người, bài toán mới chỉ giải quyết vấn đề xoá người, còn chưa giải quyết vấn đề chỉ xoá 1 trong 2 người).
3. Kết luận
Tự động xoá vật thể là một chủ đề còn khá mới mẻ trong lĩnh vực AI nói chung và Computer Vision nói riêng.
Mình đã tiến hành trình bày và giải quyết từng nội dung như sau:
- Giới thiệu về bài toán Tự động xoá vật thể trong ảnh, một vài công trình liên quan. Cùng với đó, đề xuất phương pháp tiếp cận và hướng giải quyết vấn đề.
- Giới thiệu sơ qua về mô hình EdgeConnect (ý tưởng, kiến trúc mô hình)
- Xây dựng bài toán Object Removal, kết quả thực nghiệm mà mình thu được.
4. Tài liệu tham khảo
- Rakshith Shetty, Mario Fritz, and Bernt Schiele. “Adversarial Scene Editing: Automatic Object Removal from Weak Supervision”. In: NeurIPS. 2018.
- Javier Gamazo. “Person Remover: People removal in images using Pix2Pix and YOLO”. In: 2019. URL: https://github.com/javirk/Person_remover.
- Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.

