Giới thiệu
Như chúng ta đã biết, CNN gần đây được dùng để giải quyết các vấn đề trong lĩnh vực về thị giác máy tính và phân tích ảnh y tế. Tuy nhiên, hầu hết các cách tiếp cận mới chỉ dừng lại trong việc xử lý ảnh 2D, mà dữ liệu ảnh y tế thường được sử dụng lại là các khối ảnh 3D. Nên trong bài báo này, tác giả đề xuất 1 cách tiếp cận để xử lý ảnh 3D dựa trên các khối thể tích.
Ngoài ra, tác giả còn giới thiệu 1 loss function mới, dựa trên hệ số Dice, nhằm xử lý việc mất cân bằng giữa các voxels foreground và background.
Trong bài báo này, tác giả hướng tới việc segment các khối tuyến tiền liệt MRI. Đây là 1 việc khá khó khăn, do mỗi tuyến tiền liệt lại có 1 hình dạng khác nhau ở mỗi lần quét và phụ thuộc nhiều vào các phương pháp quét. Ngoài ra, cũng có nhiều sự biến dạng và các biến thể của phân bố cường độ.
Việc annotate cho các khối ảnh y tế cũng không hề dễ dàng, việc annotate cần người có chuyên môn và chi phí không hề nhỏ. Chính vị thế việc tự động annotate cũng trở nên cần thiết.
Kiến trúc V-net
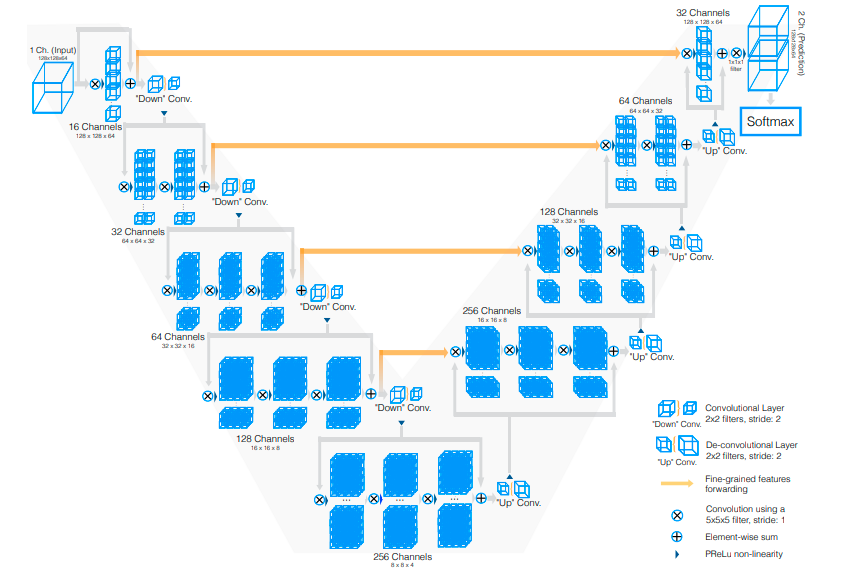
Kiến trúc V-net được thể hiện hoàn toàn trong hình vẽ trên. Phần bên trái bao gồm 1 đường dẫn 'nén' lại, trong khi đường bên phải là 1 đường giải 'nén' cho đến khi đạt được kích thước ban đầu.
Nhánh bên trái
Phần bên trái của mạng được chia làm các stage khác nhau, hoạt động ở các độ phân giải khác nhau. Mỗi stage gồm 1-3 lớp tích chập.
Ở mỗi stage, 1 khối residual được học. Đầu ra của stage trước được làm thành đầu vào của 1 chuỗi các lớp tích chập, sau mỗi lớp tích chập này đều có hàm phi tuyến, kết quả của chuỗi này được kết hợp với đầu vào ban đầu để tạo thành output của stage hiện tại. Chính vì thế, V-net đảm bảo được sự hội tụ tương tự như U-net (không dùng đến khối residual).
Trong mỗi stage, các lớp tích chập trong đó sử dụng kernel kích thước 5x5x5 voxels, mỗi voxels là 1 đơn vị nhỏ nhất trong không gian lưới 3D.
Dọc theo đường dẫn nén, kích thước feature map giảm đi 1 nửa bằng cách nhân với kernel kích thước 2x2x2 voxels và bước nhảy 2. Cũng vì thế, số channels của mỗi feature map tăng lên gấp đôi qua mỗi stage.
Việc thay các tầng pooling bằng các lớp tích chập cũng làm giảm kích thước feature map trong quá trình huấn luyện.
Hàm kích hoạt phi tuyến được sử dụng là PReLU. Mọi người có thể tham khảo thêm ở đây
Nhánh bên phải
Bên phía này, mạng tiến hành trích xuất các đặc trưng và mở rộng không gian các feature map có kích thước nhỏ để thu thập và tập hợp các thông tin cần thiết cho việc phân đoạn khối 2 channels
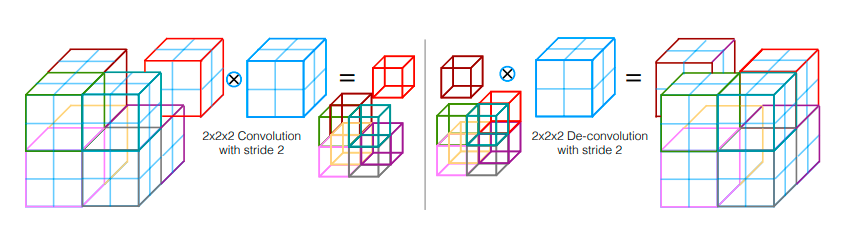
Ở mỗi stage, phép giải chập được dùng để tăng kích thước feature map, tiếp theo là 1-3 lớp tích chập. Đầu vào kết hợp cả đầu ra của stage trước đó với đầu ra của stage tương ứng bên phía trái mô hình.
Trong phía phải, các khối Residual cũng được học tương tự như phía trái.
2 feature map được tính ở lớp tích chập cuối cùng (lớp này có kernel kích thước 1x1x1) có cùng kích thước với khối đầu vào. Cả 2 feature map này được segment theo xác suất gồm miền foreground và background bằng việc áp dụng soft-max.
Kết nối ngang giữa 2 nhánh
Cũng giống như U-net, thông tin về vị trí các stage cũng không được dùng trong đường dẫn nén. Nhưng kết quả trích xuất đặc trưng của nhánh bên trái được chuyển tiếp sang nhánh bên phải bằng các kết nối ngang tương ứng.
Việc này giúp cung cấp thêm thông tin về vị trí cho nhánh bên phải và cải thiện chất lượng ở contour cuối cùng.
Ngoài ra, những kết nối này cũng giúp cải tiện thời gian hội tụ của mô hình.
Dice Loss
Công thức về cơ bản thì giống với Dice Loss được dùng trong ảnh 2D
Với voxels, trong đó là số voxels được dự đoán, là số ground truth voxels
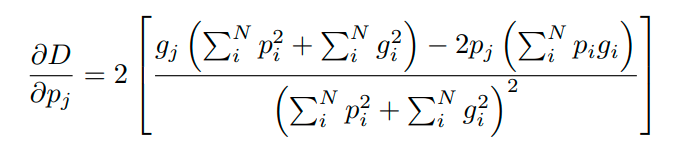
Kết quả
Training
Tất cả các khối ảnh trong mạng đều được đưa về kích thước 128x128x64 voxels và có độ phân giải là 1x1x1.5 millimet.
Bộ dữ liệu huấn luyện chỉ có 50 khối MRI, được annotate thủ công, được lấy từ tập dữ liệu PROMISE 2012. Bộ dữ liệu khá nhỏ vì có các chuyên gia được yêu cầu theo dõi việc annotate thủ công, đi cùng với đó là chi phí annotate.
Dữ liệu khá đa dạng, được thu thập ở nhiều bệnh viên khác nhau, các thiết bị và cách thức thu thập cũng khác nhau.
Việc huấn luyện yêu cầu bộ nhớ cao nên mỗi batch chỉ gồm 2 khối mẫu.
Testing
Việc test được thực hiện trên 30 khối MRI chưa từng được nhìn thấy
Ngưỡng để chấp nhận 1 voxel có xác suất là foreground là 0.5
Việc đánh giá được đo trên hệ số Dice và độ đo khoảng cách Hausdorff. Chi tiết về độ đo Hausdorff, mọi người có thể tham khảo ở đây
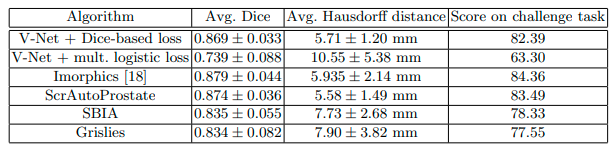
Trong bảng đánh giá trên:
- V-net sử dụng Dice loss cho kết quả tốt hơn hẳn logistic loss
- V-net cũng tỏ ra chiếm ưu thế hơn so với các phương pháp trước đo, nhưng vẫn chưa thể tốt hơn Imorphics
Trong tương lai, tác giả cũng sẽ tiếp tục nhắm tới mục tiêu segment cho các khối ảnh chứa các phương thức khác nhau như ảnh siêu âm và độ phân giải cao hơn bằng cách chia nhỏ mạng với nhiều GPU
Tham khảo
https://arxiv.org/pdf/1606.04797.pdf
https://www.sciencedirect.com/topics/computer-science/hausdorff-distance



