1. Giới thiệu
- Việc vừa phát hiện và nhận dạng văn bản trong các ảnh có bối cảnh tự nhiên là 1 việc khó khăn, chưa có giải pháp nào có thể giải quyết 1 cách hoàn toàn. Trong 1 vài năm gần đây thì có 1 số hệ thống mới cố gắng giải quyết ít nhất là một trong 2 việc trên. Trong bài viết này, chúng ta cùng tìm hiểu về STN-OCR là 1 mạng neural sâu bán giám sát, nó bao gồm 1 mạng spatial transformer được dùng để phát hiện các vùng chứa văn bản trong ảnh, và 1 mạng để nhận dạng văn bản vừa phát hiện.
- STN-OCR là 1 hệ thống nhận dạng văn bản theo kiển end-to-end trong ảnh mang bối cảnh tự nhiên, nhưng STN-OCR không dễ huấn luyện. Mô hình này gần như có thế phát hiện chữ ở các dòng được sắp xếp khác nhau trong văn bản cũng như nhận dạng chúng
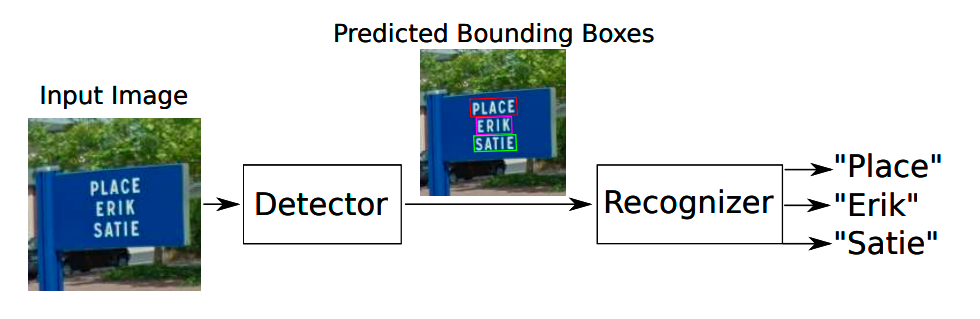
- So với hầu hết các hệ thống nhận dạng văn bản hiện tại đều trích xuất tất cả thông tin của ảnh trong 1 lần, thì STN-OCR lại khoanh vùng các miền chứa văn bản, sau đó là nhận dạng nội dung văn bản theo từng vùng một.
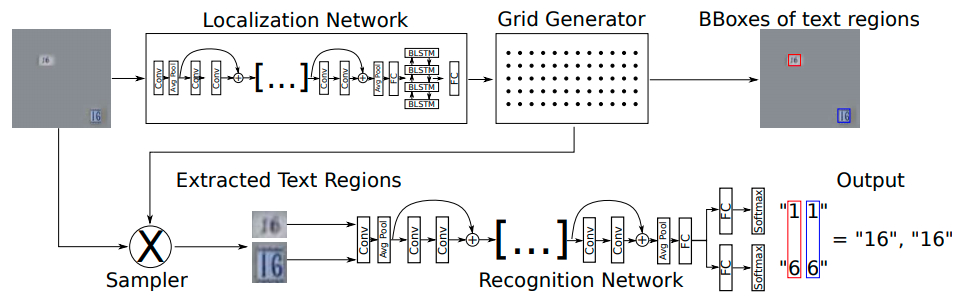
2. Phần phát hiện văn bản
- Gồm 3 phần:
- 1 hàm f_loc được tính bởi 1 mạng cục bộ, hàm này để tính các parameters.
- Sau khi có các parameters sẽ tiến hành tạo 1 Sampling Grid. Sampling Grid được dùng để định nghĩa phần nào trong các features của input ánh xạ với các features trong output.
- Dùng Sampling Grid bên trên để tạo 1 map features cho output được biến đổi không gian bằng 1 phương pháp nội suy.
Localization Network
- Mạng cục bộ lấy các features map là input và xuất ra các parameters đã được biến đổi. Trong hệ thống này, sử dụng các ảnh làm input đầu vào và dự đoán N ma trận 2 chiều được biến đổi, và N có thể là số characters, words hoặc lines
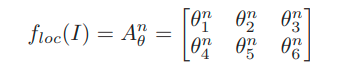
-
Ma trận A^n được tạo từ mạng CNN chuyển tiếp cùng với RNN, g_loc cũng là mạng chuyển tiếp. Mỗi ma trận trong số N ma trận được tính bằng cách dùng hidden state h_n cho mỗi step của RNN.
-
![]()
-
Các tác giả của paper dùng ResNet là mạng CNN, các residual connections của ResNet giúp giữ lại các gradient mạnh cho các layer tích chập đầu tiên, khiến ResNet hoạt động nhanh hơn và tốt hơn các mạng khác như VGG16.
-
Bidirectional Long-Short Term Memory (BLSTM) được dùng như 1 mạng RNN.
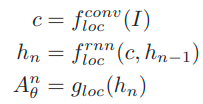
Grid Generator
- Grid Generator tạo ra N grids G_i^n với tọa độ u_i^n và v_i^n cho feature map của input bằng việc sử dụng các grid có khoảng cách đều nhau G_0 với tọa độ y_h_o, x_w_o và ma trận A_n^0
- Khi đó, kết quả là N grids G_i^N với bouding boxes các vùng văn bản có thể được trích xuất từ input feature map.
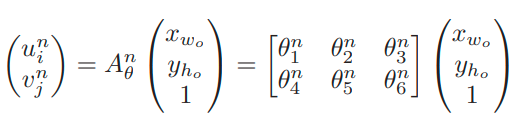
Image Sampling
- N sampling grid G_i^N có thể được dùng để lấy những giá trị sample của feature map tại các tọa độ tương ứng u_i^n, v_i^n. Tuy nhiên, những điểm này không phải lúc nào cũng khớp hoàn toàn với grid các giá trị rời rạc trong input feature map. Do đó, các tác giả trích xuất giá trị tại một tọa độ nhất định bằng cách dùng các giá trị nội suy bi-linearly của những điểm lân cận gần nhất. Lấy giá trị của N output feature maps O^n tại các vị trí i, j bằng công thức bên dưới
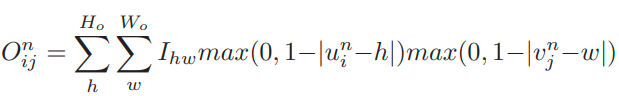
3. Phần nhận dạng văn bản
- Trong phần nhận dạng văn bản này, N vùng văn bản khác nhau được tạo từ phần phát hiên văn bản sẽ được xử lý 1 độc lập cho từng phần. Các tác giả cũng sử dụng ResNet cho phần nhận dạng này. Phân phối xác suất y^ trên không gian nhãn L_epsilon được dự đoán trong phần này, trong đó Lq = L U q với L = 0-9a-z và q đại diện cho nhãn trống.
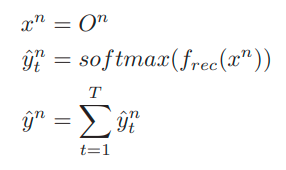
- Các tác giả cũng đề xuất dùng CTC để huấn luyện mô hình và truy xuất nhãn có khả năng xảy ra cao nhất bằng cách đặt y^ là đường dẫn nhãn có thể xảy ra nhất PI
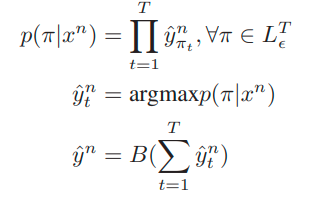
- L_epsilon^T là tập tất cả các nhãn có chiều dài T và p(PI | xn) là xác suất mà đường đi PI thuộc L được dự đoán bởi DNN. B là hàm loại bỏ tất cả các nhãn trống và những nhãn bị lặp lại.
4. Kết quả và thử nghiệm
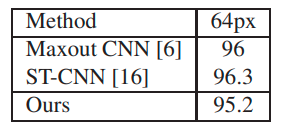
- Các tác giả đã đánh giá cấu trúc mạng trong 1 số bộ dữ liệu phát hiện và nhận dạng văn bản, như SVHN dataset, Robust dataset và FSNS dataset. Trong bảng bên dưới là độ chính các phần nhận dạng với bộ dữ liệu SVHN. Robust được dùng để đánh giá cho cả phần phát hiện và nhận dạng các ký tự đơn trong mô hình. FSNS là bộ dữ liệu khó khăn nhất đối với mô hình. Vì FSNS chứa nhiều dòng khác nhau với độ dài text khác nhau được lồng vào ảnh mang bối cảnh tự nhiên

Kết luận
- STN-OCR là 1 hệ thống end-to-end nhận dạng văn bản với bối cảnh tự nhiên, là 1 mạng với nhiều task. Nó chứa 2 phần gồm: Phát hiện văn bản và nhận dạng văn bản, phần phát hiện được huấn luyện theo mô hình học bán giám sát. Hệ thống có thể phát hiện 1 loạt các dòng văn bản được sắp xếp và nhận dạng nội dung. Tuy nhiên, nó lại không có khả năng phát hiện các phần văn bản có vị trí ngẫu nhiên trong ảnh.
- Một điểm nổi bật của hệ thống này là huấn luyện theo phương pháp bán giám sát. Do vấn đề về dữ liệu huấn luyện, các mô hình Deep Learning không giám sát và bán giám sát ngày càng trở nên quan trọng. Trong mô hình này, tác giả chỉ sử dụng hình ảnh làm input đầu vào, hàm loss chỉ dựa trên độ chính các khi nhận dạng từ, khoanh vùng các văn bản được học từ chính mạng đó, có nghĩa là nó có thể học cách quyết định xem nên tìm vùng văn bản ở đâu. Ngoài ra, mô hình này cũng có thể giải quyết các vấn đề như ảnh bị dịch chuyển, nghiêng, xoay bằng cách dùng biến đổi affine.



