Hiểu được ngôn ngữ nói, hoặc là chuyển được âm thanh thành dạng chữ viết là 1 trong những mục tiêu đầu tiên của xử lý ngôn ngữ máy tính. Thực tế, xử lý tiếng nói đã được tiến hành bởi máy tính nhiều thập kỉ trước. Mục tiêu của automatic speech recognition (công nghệ tự nhận dạng giọng nói) là ánh xạ bất kì waveform nào:

về dạng chữ viết:
Tự động nhận dạng tiếng nói bởi bất kì người nào trong bất kì môi trường nào vẫn còn rất nhiều thách thức cần giải quyết, tuy nhiên công nghệ ASR đã phát triển so với ngày xưa rất nhiều và có thể ứng dụng rất nhiều trong cuộc sống. ASR rất hữu ích như sinh caption cho audio hoặc video text, tự động dịch các bộ phim hoặc video hay là các buổi stream phát sóng trực tiếp,...
1. Trích xuất đặc trưng cho ASR: Log Mel Spectrum
Bước đầu tiên trong ASR là chuyển đổi waveform đầu vào thành 1 chuỗi các vector đặc trưng, mỗi vector biểu diễn thông tin trong 1 khoảng thời gian của tín hiệu. Cùng xem cách để chuyển 1 file âm thanh thô thành chuỗi các vector log mel spectrum.
1.1 Sampling và Quantization
1 tín hiệu được lấy mẫu bằng cách đo biên độ tại 1 thời điểm riêng biệt, tần số lấy mẫu (sampling rate) là số lượng mẫu được lấy trong 1s. Để đo chính xác, ta ít nhất phải có 2 mẫu trong cùng 1 chu kì: 1 mẫu để đo phần dương của tín hiệu và 1 mẫu để đo phần âm của tín hiệu. Càng nhiều mẫu sẽ càng tăng độ chính xác, nhưng ít hơn 2 mẫu sẽ làm mất mát thông tin. Tần số lấy mẫu phải >= 2 lần tần số lớn nhất xuất hiện trong tín hiệu, được gọi là tần số Nyquist. Phần lớn tần số trong khoảng nghe được của con người là thấp hơn 10000 Hz, vì thế tần số lấy mẫu 20000 Hz được coi là phù hợp. Nhưng với tiếng của điện thoại được lọc qua 1 mạch chuyển kênh và chỉ có tần số thấp hơn 4000Hz là được truyền đi qua điện thoại. Do đó, sampling rate 8000 Hz là phù hợp, với âm thanh microphone sẽ là 16000 Hz.
Mặc dù sử dụng sử dụng sampling rate cao sẽ cho kết quả chính xác hơn với ASR, ta không thể kết hợp các sampling rate khác nhau cho quá trình training và testing hệ thống ASR. Nếu chúng ta testing trên tập dữ liệu điện thoại như Switchboard (8 KHz sampling), chúng ta phải hạ lấy mẫu tập training xuống 8KHz. Tương tự, nếu chúng ta training ở tập dữ liệu hỗn hợp mà bao gồm cả tiếng telephone, ta phải hạ tần số lấy mẫu xuống 8KHz.
Giá trị biên độ được lưu trữ dưới dạng integer 8 bit (trong khoảng giá trị từ -128 đến 127) hoặc 16 bit (giá trị từ -32768 đến 32767). Quá trình biểu diễn các số thực dưới dạng số nguyên được gọi là quantization (lượng tử hóa). Với mỗi sample tại thời điểm n được quantized dưới dạng waveform .
1.2 Windowing
Sau khi có được biểu diễn lượng tử của waveform, sau đó ta cần trích xuất các đặc trưng từ 1 window của âm thanh. Âm thanh được trích xuất từ mỗi window gọi là frame. Window bao gồm 3 tham số: window size hay là frame size, frame stride hay là shift hoặc offset giữa các cửa sổ, và shape của cửa sổ.
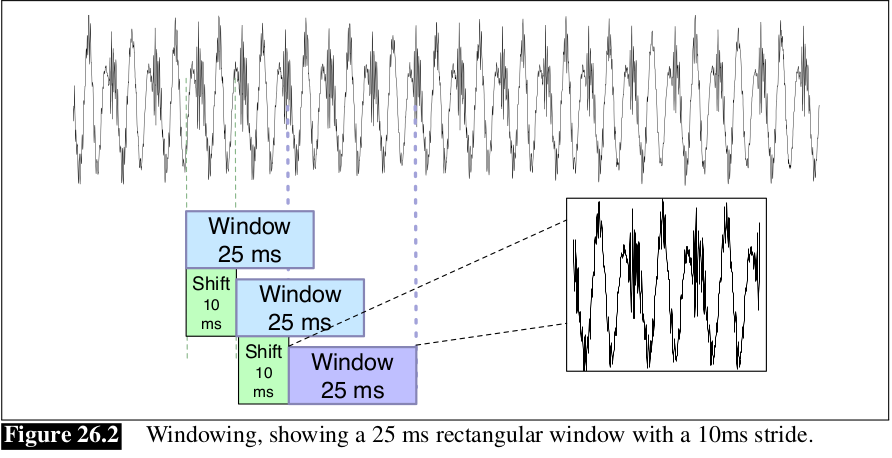
Để trích xuất tín hiệu, ta nhân giá trị của tín hiệu tại thời điểm n, bởi giá trị của window tại thời điểm n, :
Hình dạng của window là hình chữ nhật, tuy nhiên window sẽ cắt đứt tín hiệu tại các điểm biên. Để tránh điều này, ta thường sử dụng Hamming window, làm shrink giá trị của tín hiệu về 0 tại biên của window, tránh sự không liên tục. Cùng xem phương trình:
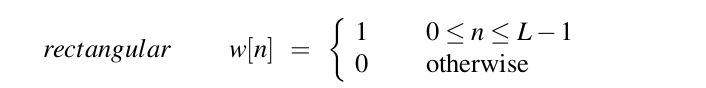

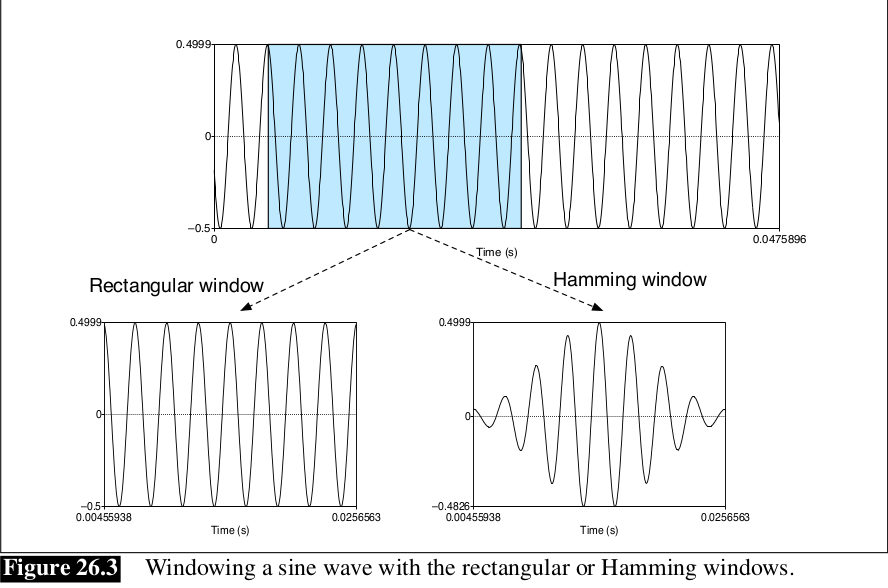
1.3 Discrete Fourier Transform
Bước tiếp theo là trích xuất các thông tin đặc trưng từ cửa sổ tín hiệu. Để trích xuất thông tin tín hiệu từ 1 chuỗi rời rạc (hay nói cách khác là 1 mẫu tín hiệu) ta dùng discrete Fourier transform hay DFT.
Đầu vào của DFT là 1 chuỗi và đầu ra, với mỗi N dải tần số rời rạc, là 1 số phức biểu diễn độ biên độ và pha của thành phần tần số ở trong tín hiệu ban đầu. Nếu chúng ta plot biên độ theo miền tần số, ta có thể visualize spectrum. Ví dụ hình bên dưới biểu diễn 1 khoảng Hamming window 25ms và spectrum của nó sau khi được tính toán qua phép DFT.
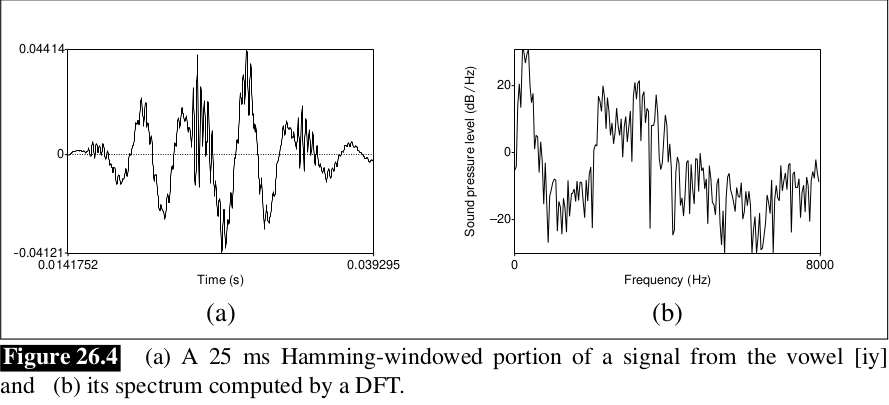
Ở đây sẽ không đề cập sâu về DFT, ngoại trừ giải tích Fourier dựa vào công thức Euler với j là 1 đơn vị ảo:
Mình xin được nhắc lại công thức cho những người đã học môn xử lý tín hiệu (signal processing), DFT được định nghĩa như sau:
1.4 Mel Filter Bank và Log
Kết quả của phép FFT cho chúng ta biết về năng lượng tại mỗi dải tần số. Tai người lại không cảm nhận như nhau tại mọi dải tần số, nhạy hơn ở tần số thấp và kém nhạy hơn ở tần số cao. Do đó người ta đã đề xuất ra Mel Scale với mel là 1 đơn vị của cao độ. Phổ mel được tính toán theo công thức:
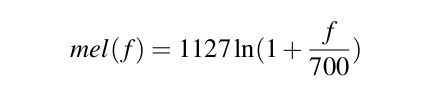
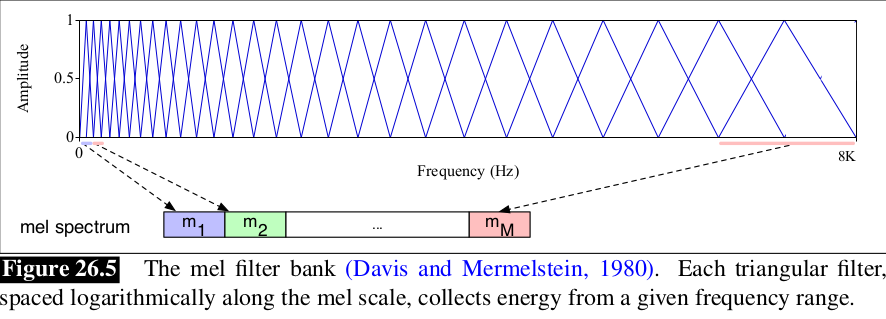
Cuối cùng, ta lấy log của mỗi giá trị mel spectrum. Con người ít nhạy hơn với sự thay đổi biên độ tại biên độ cao hơn tại biên độ thấp.
2. Speech Recognition Architecture
Kiến trúc cơ bản cho các tác vụ ASR là Encoder-Decoder (được áp dụng với RNNs và Transformers), khá giống với kiến trúc của task Machine Translation. Thông thường, từ log mel spectral feature, ánh xạ tới các chữ cái, mặc dù cũng có thể ánh xạ tới morpheme như wordpiece hoặc BPE.
Hình bên dưới thể hiện kiến trúc encoder-decoder, khá tương tự như attention-based encoder decoder hay AED, hoặc listen attend spell (LAS). Đầu vào của 1 chuỗi t vector đặc trưng , 1 vector mỗi 10ms frame. Đầu ra có thể là chữ cái hoặc word-piece. Khi đó đầu ra chuỗi , với kí hiệu bắt đầu và kết thúc của câu là <sos> và <eos>, và mỗi là 1 kí tự.
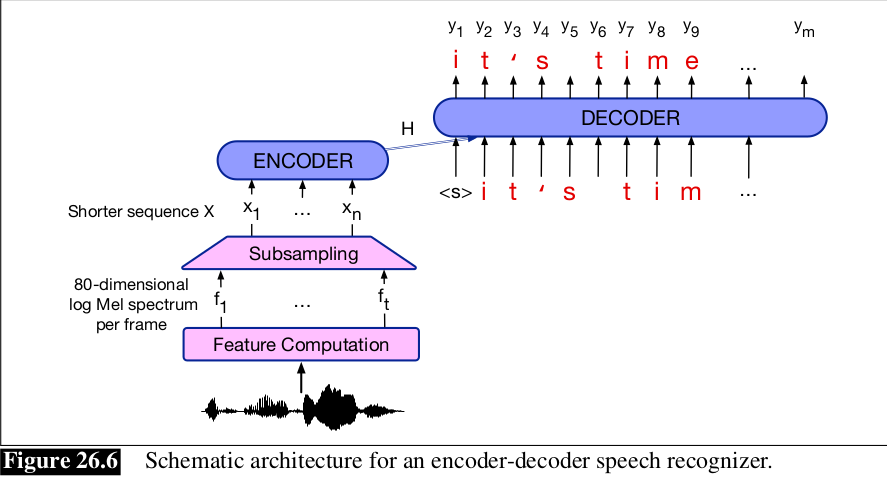
Bởi vì độ dài câu là khác nhau, nên kiến trúc encoder-decoder cho tiếng nói phải có 1 bước nén các thông tin từ khối encoder trước khi cho vào khối decoder. Mục tiêu của việc subsampling là sinh ra 1 chuỗi ngắn hơn sẽ là đầu vào cho khối decoder. Thuật toán đơn giản nhất gọi là low frame rate: với mỗi thời gian i, ta concatenate vector đặc trưng với 2 vector trước và tạo thành 1 vector mới dài hơn 3 lần. Sau đó ta xóa đi và . Thay vì được 1 vector đặc trưng 40 chiều mỗi 10ms, ta thu được 1 vector 120 chiều mỗi 30ms, với độ dài chuỗi ngắn hơn .
Sau bước nén này, kiến trúc encoder-decoder cho giọng nói tương tự như kiến trúc cho Machine Translation (dịch máy), với sự kết hợp của mạng RNN hay Transformer.
Ta có thể sinh ra mỗi chữ cái cho đầu ra nhờ vào thuật toán greedy decoding:
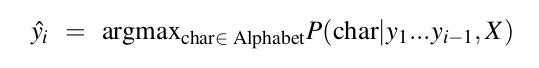
Hoặc là có thể sử dụng beam search, đây là thuật toán thường xuyên được sử dụng cho các bài toán language model. Beam search khởi đầu với 1 chuỗi rỗng. Tại mỗi bước, nó thực hiện tìm kiếm toàn bộ trên không gian của bước đó và lấy ra k kết quả có score cao nhất. Với là trọng số của language model, kết hợp với chuẩn hóa độ dài câu và xác suất của language model , ta có phương trình tính score:
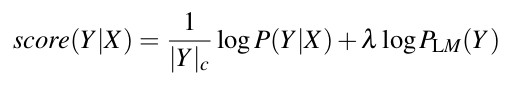
Learning
Encoder-decoder cho tiếng nói được huấn luyện với hàm loss cross-entropy được dùng cho các bài toán về language model. Tại timestep i của pha decoding, hàm loss chính là logarith xác suất của kí tự đúng :
Hàm loss cho toàn bộ câu là tổng của các loss:
Chúng ta thường sử dụng teacher forcing sẽ giúp model hội tụ nhanh hơn.
3. CTC Loss
Chúng ta đã biết rằng speech recognition có 2 tính chất làm cho nó rất phù hợp với kiến trúc encoder-decoder, với khối encoder sẽ làm nhiệm vụ sinh ra encoding biểu diễn giá trị của vector đầu vào, sau đó khối decoder sẽ sử dụng vector biểu diễn đấy kết hợp cơ chế attention để sinh ra câu đích tương ứng. Trong xử lý tiếng nói, ta có 1 câu giọng nói đầu vào X ánh xạ tới 1 chuỗi các kí tự Y, khi đó, rất khó để xác định được phần nào của X sẽ tương ứng với phần nào của Y.
Do đó chúng ta sẽ tìm hiểu về CTC (Connectionist Temporal Classification) là 1 thuật toán và hàm loss có thể giải quyết rất hiệu quả vấn đề này. Ý tưởng của CTC là sẽ output mỗi kí tự tại mỗi frame của input, do đó output sẽ có cùng độ dài với input, sau đó kết hợp và loại bỏ các kí tự thừa để tạo thành 1 chuỗi hoàn chỉnh.
Giả sử âm thanh đầu vào là dinner, chúng ta có 1 hàm để chọn ra các kí tự xác suất cao nhất cho mỗi frame đầu vào, biểu diễn là . Ta gọi chuỗi các chữ cái tương ứng với mỗi input frame là alignment. Hình bên dưới mô tả 1 alignment, và cùng xem nếu nó kết hợp lại và loại bỏ các kí tự liên tiếp trùng nhau.
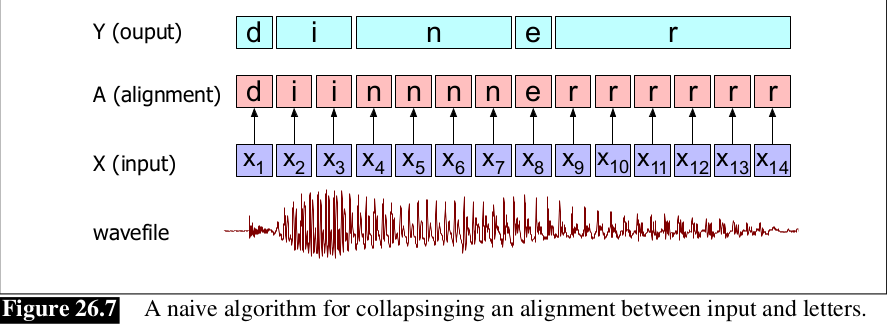
Như chúng ta có thể thấy, thuật toán hoạt động không hiệu quả, thuật toán chuyển đổi giọng nói thành diner thay vì dinner. Do đó, CTC giải quyết vấn đề này bằng cách thêm vào 1 kí tự đặc biết gọi là blank, viết là . Định nghĩa ánh xạ B : a y giữa alignment a và output y, thu gọn các chữ cái trùng nhau và loại bỏ tất cả blank. Cùng xem hình bên dưới để hiểu rõ hơ nhé.
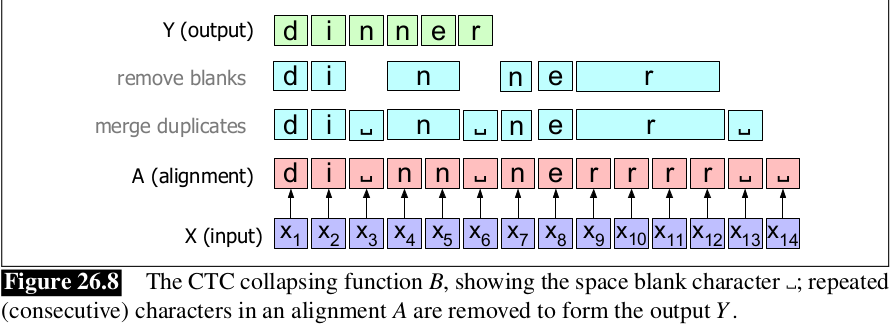
Hàm CTC là many-to-one, có rất nhiều alignment ánh xạ tới cùng 1 chuỗi đầu ra. Ví dụ hình bên dưới không phải là alignment duy nhất cho kết quả là dinner. Tập hợp các alignment cùng sinh ra 1 output Y giống nhau, gọi là nghịch đảo của B, kí hiệu là , và biểu diễn tập hợp đó là .
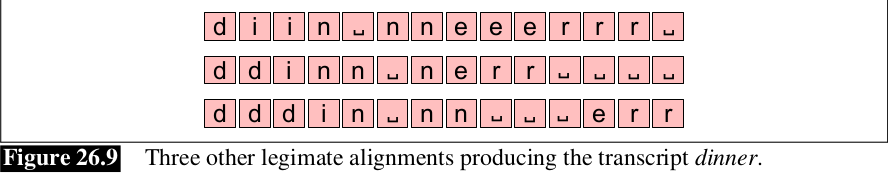
3.1 CTC Inference
Trước khi tìm hiểu cách tính , đầu tiên cùng xem cách CTC gán xác suất cho mỗi alignment cụ thể . CTC giả sử rằng với input X, CTC output tại thời điểm t là độc lập với output ở các thời điểm khác:
Do đó để chọn ra alignment tốt nhất , ta có thể chọn các kí tự có xác suất cao nhất tại mỗi timestep t:
Sau đó đưa alignment qua CTC cắt bớt các kí tự thừa để thu được đầu ra Y. Hình bên dưới, ta lấy encoder, sinh ra hidden state tại mỗi timestep, và decode bằng cách lấy softmax trên tập các kí tự có trong từ điển.
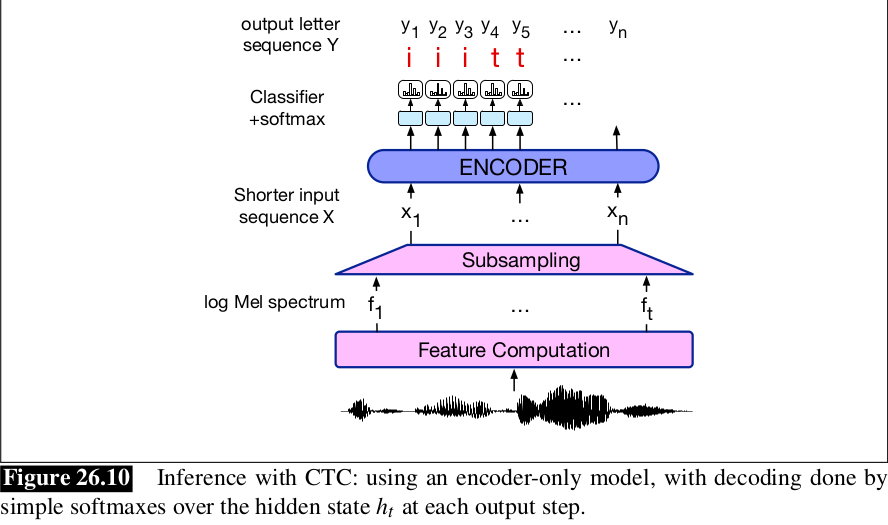
Có 1 vấn đề phát sinh trong quá trình inference ở CTC: ta chọn alignment có khả năng cao nhất A, nhưng chưa chắc alignment xác suất cao nhất lại tương ứng với xác suất cao nhất của output Y sau khi collapse. Bởi vì có rất nhiều alignment cùng dẫn đến 1 chuỗi đầu ra giống nhau. Ví dụ, tưởng tượng alignment có khả năng cao nhất A với input X = [] là chuỗi [a b ] nhưng 2 alignment cao tiếp theo lại là [b b] và [ b b]. Khi đó, output Y = [b b], bằng tổng xác suất 2 alignment kia có khả năng chính xác hơn Y = [a b].
Tuy nhiên, việc tính tổng xác suất tất cả các alignment sẽ rất tốn kém do có quá nhiều alignment, do đó người ta đề xuất tính xấp xỉ của tổng bằng cách sử dụng 1 biến thể của Viterbi beam search mà giữ trong beam các alignment xác suất cao nhất mà ánh xạ tới cùng 1 output, sau đó cộng tất cả chúng lại như 1 xấp xỉ tổng. Để hiểu 1 cách rõ ràng hơn, các bạn có thể tham khảo bài viết được giải thích rất chi tiết này https://distill.pub/2017/ctc/
3.2 CTC Training
Để huấn luyện 1 hệ thống ASR sử dụng CTC, chúng ta sử dụng hàm loss negative log-likelihood. Do đó, loss cho toàn bộ tập dữ liệu D là tổng của các negative log-likelihoods của correct output Y cho mỗi input X:
Để tính toán CTC loss cho mỗi cặp đầu vào (X, Y), ta cần tính xác suất của Y cho trước X, hay chính là tính tổng tất cả các alignment mà collapse lại thành Y. Nói cách khác:
Tính toán tất cả các alugnment có thể xảy ra là không khả thi vì có quá nhiều alignment. Tuy nhiên ta có thể tính tổng bằng cách sử dụng dynamic programming để merge các alignment. Thuật toán dynamic programming cho training và inference được trình bày trong Connectionist Temporal Classification
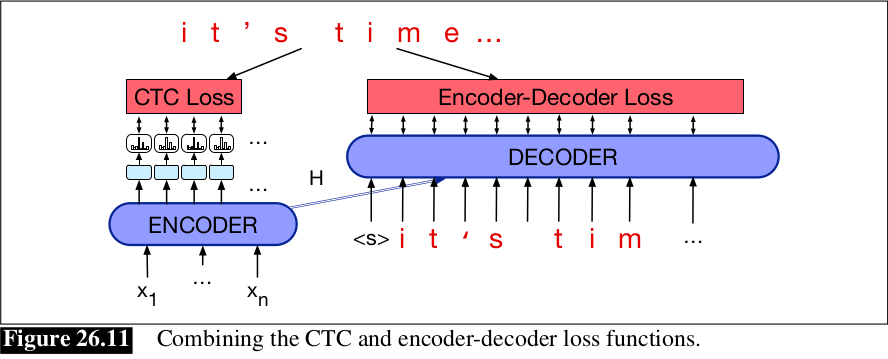
3.3 Kết hợp CTC and Encoder-Decoder
Chúng ta cũng có thể kết hợp 2 kiến trúc/loss function ta vừa mô tả ở trên, cross-entropy loss từ kiến trúc encoder-decoder, và CTC loss. Cho quá trình training, ta có thể đánh trọng số 2 loss với trên tập dev:
Cho quá trình inference, ta có thể kết hợp với 2 language model, cùng với length penalty và các trọng số đã được học:
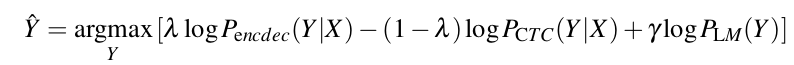
3.4 Streaming Models: RNN-T for improving CTC
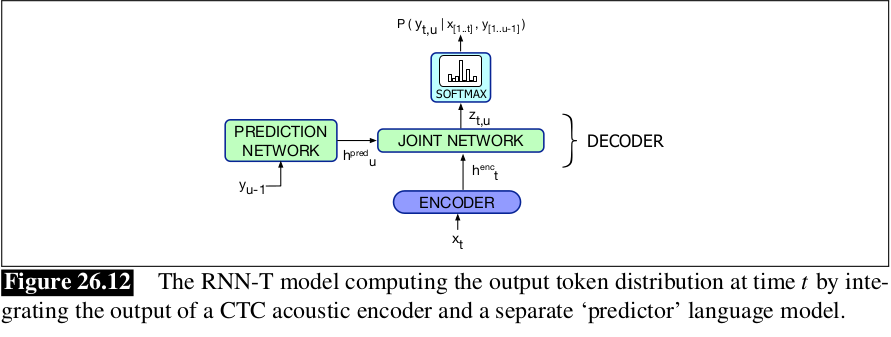
Bởi vì có 1 giả định độc lập trong CTC: cho rằng output tại thời điểm t là độc lập với output tại thời điểm t - 1, nhận dạng trong CTC không đạt kết quả tốt như là nhận dạng attention-based encoder-decoder. Tuy nhiên, nhận dạng CTC có thể dùng cho bài toán streaming. Streaming là nhận dạng từ ngay lúc nói luôn hơn là chờ nói hết cả câu rồi mới nhận dạng. Các thuật toán sử dụng cơ chế attention cần phải tính toán chuỗi hidden state trên toàn bộ đầu vào rồi cung cấp phân phối attention cho decoder để nó tiến hành việc decode. Ngược lại, thuật toán CTC có thể input các chữ cái từ trái sang phải ngay lập tức.
Nếu chúng ta muốn làm việc với bài toán streaming, chúng ta cần 1 cách để cải thiện mô hình CTC recognition bằng cách loại bỏ giả định độc lập ở phía trên. Mô hình RNN-Transducer (RNN-T) là 1 model như vậy. RNN-T có 2 thành phần chính: đầu tiên là CTC model, và 1 language model chia cắt gọi là predictor mà phụ thuộc vào đầu ra của các token ở phía trước. Tại mỗi timestep t, CTC encoder output 1 hidden state cho trước input . Language model predictor lấy đầu ra token ở trước làm input, và output hidden state . Sau đó được đưa qua 1 mạng khác có output được đưa qua lớp softmax để dự đoán kí tự tiếp theo.
3.5 ASR Evaluation: Word Error Rate
1 metric tiêu chuẩn dùng để đánh giá hệ thống ASR là word error rate (WER). WER dựa vào có bao nhiêu từ được sinh ra từ mô hình khác biệt so với bản dịch gốc. Bước đầu tiên trong việc tính toán word error là tính toán minimum edit distance giữa các từ, sau đó trả về số lượng tối thiểu các từ substitution, insertion, và deletion. WER được định nghĩa như sau (do phương trình có bao gồm insertion nên có thể tỉ lệ WER sẽ lớn hơn 100%):
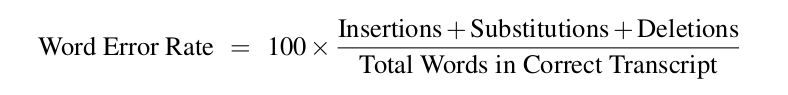
Các bạn có thể tham khảo 1 bài viết khác của mình về WER tại đây.
4. Tổng kết
Trên đây là những tổng hợp kiến thức của mình trong quá trình tự tìm hiểu về Speech Recognition, chủ yếu được tham khảo từ chương 26 cuốn Speech and Language Processing. Trong quá trình viết không thể tránh khỏi những sai sót, nên nếu có câu hỏi gì bạn hãy cmt vào bên dưới, mình sẽ cố gắng trả lời 1 cách sớm nhất. Cảm ơn mọi người rất nhiều!!!