Ở Part 1 chúng ta đã đi qua các bước hướng dẫn cách cài đặt Pandas, cách tạo và xem thông tin của một Dataframe. Như đã đề cập ở phần trước thì nội dung trong Part 2 này giúp chúng ta làm quen các thao tác với Pandas để làm sạch và xử lý dữ liệu.
Mình sẽ thực hiện xử lý với một bảng dữ liệu được lấy từ Kaggle . Trước hết ta cần phải đọc được dữ liệu từ file .csv và có một cái nhìn bao quát về nó.
import pandas as pd
df = pd.read_csv('../input/customer-personality-analysis/marketing_campaign.csv', sep='\t')
df.head()
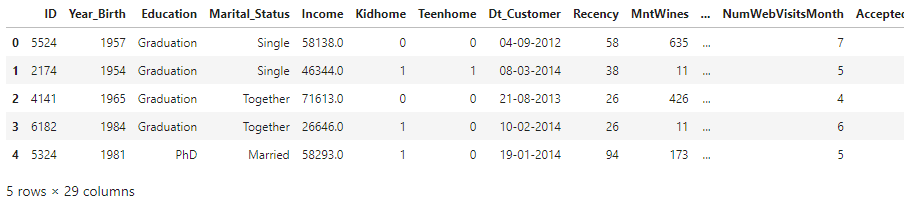 Sử dụng lệnh
Sử dụng lệnh .info() để biết được những thông tin cần thiết của bộ dữ liệu này như:
- Số lượng dòng: 2240
- Số lượng cột: 29
- Tên cột
- Loại dữ liệu và số lượng hiện có của mỗi cột
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2240 entries, 0 to 2239
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 2240 non-null int64
1 Year_Birth 2240 non-null int64
2 Education 2240 non-null object
3 Marital_Status 2240 non-null object
4 Income 2216 non-null float64
5 Kidhome 2240 non-null int64
6 Teenhome 2240 non-null int64
7 Dt_Customer 2240 non-null object
8 Recency 2240 non-null int64
9 MntWines 2240 non-null int64
10 MntFruits 2240 non-null int64
11 MntMeatProducts 2240 non-null int64
12 MntFishProducts 2240 non-null int64
13 MntSweetProducts 2240 non-null int64
14 MntGoldProds 2240 non-null int64
15 NumDealsPurchases 2240 non-null int64
16 NumWebPurchases 2240 non-null int64
17 NumCatalogPurchases 2240 non-null int64
18 NumStorePurchases 2240 non-null int64
19 NumWebVisitsMonth 2240 non-null int64
20 AcceptedCmp3 2240 non-null int64
21 AcceptedCmp4 2240 non-null int64
22 AcceptedCmp5 2240 non-null int64
23 AcceptedCmp1 2240 non-null int64
24 AcceptedCmp2 2240 non-null int64
25 Complain 2240 non-null int64
26 Z_CostContact 2240 non-null int64
27 Z_Revenue 2240 non-null int64
28 Response 2240 non-null int64
dtypes: float64(1), int64(25), object(3)
memory usage: 507.6+ KB
Ngoài ra ta có thể xem thêm thống kê bằng lệnh .describe() hoặc .describe().T
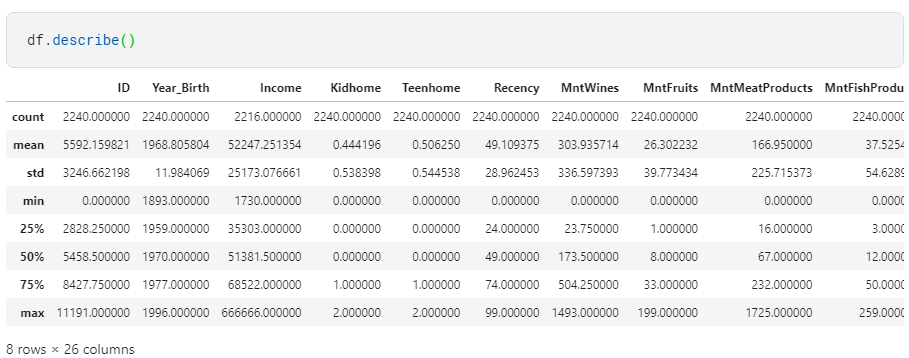
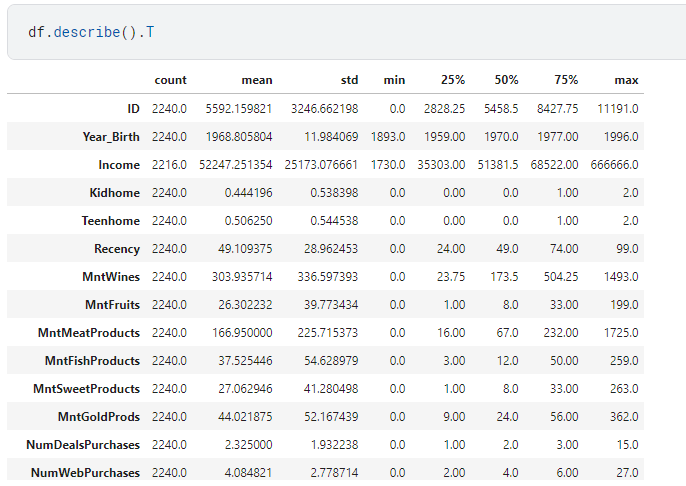
1. Handling duplicates
Thật may mắn khi các dòng trong bộ dữ liệu này không trùng nhau. Tuy nhiên đối với bộ dữ liệu khác ta cần phải kiểm tra kĩ điều này. Đôi khi chính các giá trị trùng lắp này lại cho bạn một kết quả không mong muốn tí nào 🙄🙄
Bạn cảm thấy dữ liệu bị trùng không mang lại lợi ích gì cả? Đơn giản ta chỉ việc xóa những dòng bị trùng này bằng lệnh .drop_duplicates(inplace = True)
Note: Khi dùng cụm (inplace = True) thì có nghĩa dữ liệu sẽ được thay đổi trực tiếp trên chính dataframe ban đầu. Nếu bạn muốn thay đổi và lưu thành một dataframe mới thì nên xóa cụm đó đi nhé!
2. Cleaning empty cells
Đôi khi, dữ liệu bị thiếu cũng có thể góp phần làm cho kết quả bị sai lệch. Để thống kê số lượng bị rỗng ta có thể dùng .isnull().sum(). Sau đó ta có 2 cách để xử lý lượng data bị thiếu này, hoặc xóa bỏ cả dòng chứa thông tin bị thiếu đó, hoặc điền vào các ô đó bằng các giá trị mean, median, mode tùy vào ý nghĩa của chúng.
ID 0
Year_Birth 0
Education 0
Marital_Status 0
Income 24
Kidhome 0
Teenhome 0
Dt_Customer 0
Recency 0
MntWines 0
MntFruits 0
MntMeatProducts 0
MntFishProducts 0
MntSweetProducts 0
MntGoldProds 0
NumDealsPurchases 0
NumWebPurchases 0
NumCatalogPurchases 0
NumStorePurchases 0
NumWebVisitsMonth 0
AcceptedCmp3 0
AcceptedCmp4 0
AcceptedCmp5 0
AcceptedCmp1 0
AcceptedCmp2 0
Complain 0
Z_CostContact 0
Z_Revenue 0
Response 0
dtype: int64
Removing null values
Để xóa hoàn toàn cả dòng chứa thông tin bị thiếu, bạn chỉ việc dùng .dropna(inplace=True). Tác dụng khi dùng inplace=True ở đây cũng giống như ở mục 1, dữ liệu sẽ được thay đổi trực tiếp trên chính dataframe ban đầu của bạn. Trường hợp bạn cần xóa cột chứa ô rỗng thì sử dụng .dropna(axis=1) .
Dữ liệu có giá trị rất lớn đối với mọi dự án. Bạn chỉ nên xóa bỏ dữ liệu rỗng khi bản thân thật sự hiểu về chúng và số lượng missing data rất ít.
Imputation
Việc thay các ô rỗng bằng các giá trị trung bình (mean), giá trị trung vị (median), giá trị xuất hiện nhiều (mode) sẽ ít rủi ro hơn so với việc bỏ chúng đi hoàn toàn.
Ví dụ bạn cần điền vào các ô rỗng ở cột Income bằng các giá trị mean, ta cần tính giá trị mean trước
mean_income = df["Income"].mean()
mean_income
Lúc này mean_income có giá trị là 52247.25135379061. Tiếp theo ta điền giá trị mean này vào các ô chứa giá trị rỗng.
df.fillna(mean_income, inplace=True)
Ta cùng kiểm tra lại xem còn giá trị nào rỗng không nhé
ID 0
Year_Birth 0
Education 0
Marital_Status 0
Income 0
Kidhome 0
Teenhome 0
Dt_Customer 0
Recency 0
MntWines 0
MntFruits 0
MntMeatProducts 0
MntFishProducts 0
MntSweetProducts 0
MntGoldProds 0
NumDealsPurchases 0
NumWebPurchases 0
NumCatalogPurchases 0
NumStorePurchases 0
NumWebVisitsMonth 0
AcceptedCmp3 0
AcceptedCmp4 0
AcceptedCmp5 0
AcceptedCmp1 0
AcceptedCmp2 0
Complain 0
Z_CostContact 0
Z_Revenue 0
Response 0
dtype: int64
Summary
Part 2 này đã giúp chúng ta có được hướng đi ban đầu trong việc tiếp cận với dữ liệu dạng bảng. Tuy nhiên bạn cần tìm hiểu tiếp để có được quyết định tốt nhất đối với từng kiểu dữ liệu khác nhau.
Hẹn gặp các bạn ở những bài chia sẻ tiếp theo nhé!
Tài liệu tham khảo
- Applied Data Science with Python - Coursera
- 100 Days of Code: The Complete Python Pro Bootcamp for 2022 - Udemy
- Pandas Tutorial - W3School
- Python Pandas Tutorial: A Complete Introduction for Beginners


