Cho trước 1 tập test, mục tiêu là đưa ra 1 chỉ số đánh giá sự tương đồng của tập test đối với đầu ra của mô hình sinh. Tuy nhiên, việc đánh giá mô hình sinh không dễ dàng như các mô hình phân lớp.
Một chỉ số có thể dùng để đánh giá là log likelihood. Cụ thể hơn, với mỗi điểm dữ liệu, chúng ta sẽ tính log likelihood của mô hình với điểm này, rồi lấy kì vọng trên toàn tập test
Nhược điểm là chỉ số này chỉ có thể tính toán được với mô hình xác suất, ví dụ như mô hình đồ thị xác suất, mô hình dạng flow, một số mô hình ngôn ngữ, Đối với các mô hình kiểu GAN, chúng ta không biết xác suất của dữ liệu, do đó không thể tính ra log likelihood. Một chỉ số xác suất khác có thể sử dụng là mê tríc Wasserstein giữa hai phân bố, do mê tríc này có thể tính toán giữa 2 tập rời rạc. Tuy nhiên, việc áp dụng toàn bộ dữ liệu sẽ không hiệu quả.
Đối với các mô hình GAN, chúng ta có thể sử dụng hai chỉ số là Frechet Inception Distance (FID) và Inception Score (IS). Hai chỉ số này đều sử dụng mô hình phụ là Inception, trong đó IS so sánh phân bố của nhãn trước và sau khi biết ảnh sinh bởi GAN, FID so sánh embedding của dữ liệu và đầu ra của GAN khi đi qua mô hình Inception. Nhược điểm của các chỉ số này là ảnh hưởng bởi bias của mô hình phụ.
Để đánh giá mô hình sinh, chúng ta có thể dựa trên tính chất hình học của không gian dữ liệu. Nếu các tính chất này thỏa mãn bất biến nào đó, chúng có thể được dùng để phân loại không gian, từ đó so sánh giữa dữ liệu test và dữ liệu sinh ra bởi mô hình.
Tô pô và đồng điều
Chúng ta sẽ khảo sát tính chất của không gian dữ liệu, tức là không gian mà phân bố dữ liệu tập trung gần đó. Để cho đơn giản, chúng ta sẽ đặt một quan hệ tương đương giữa các không gian, và tính chất mong muốn sẽ như nhau với các không gian tương đương. Do đó, việc đánh giá mô hình sinh sẽ trở thành so sánh không gian của mô hình và không gian của dữ liệu, từ đó quy về việc khảo sát các tính chất trên.
Giả sử chúng ta có một hình khối lập phương bằng đất sét. Chúng ta có thể nắn bóp khối hình này mà không chọc thủng hay kết dính các phần để tạo thành một hình cầu. Việc làm này có thể mô tả bởi một song ánh liên tục. Mặt khác, chúng ta cũng có thể biến đổi hình cầu thành khối lập phương một cách tương tự, do đó chúng ta muốn ánh xạ ngược của nó cũng liên tục. Hai hình này do đó có thể xem là tương đương nhau, và các tính chất chúng ta muốn sử dụng cũng giống nhau trên hai hình này.
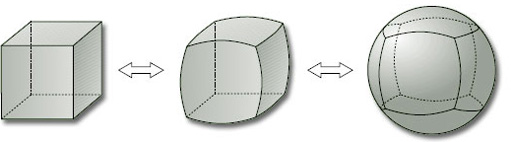
Tuy nhiên không có cách làm nào tương tự để biến khối lập phương thành một hình xuyến. Do đó ta có thể nói hình xuyến không tương đương với hình lập phương. Nếu không gian dữ liệu và không gian mô hình không tương đương nhau, có thể kết luận là mô hình sinh không chính xác. Ngược lại, nếu hai không gian này tương đương, có thể kết luận là trên khía cạnh nào đó mô hình đã học được tính chất hình học của dữ liệu.
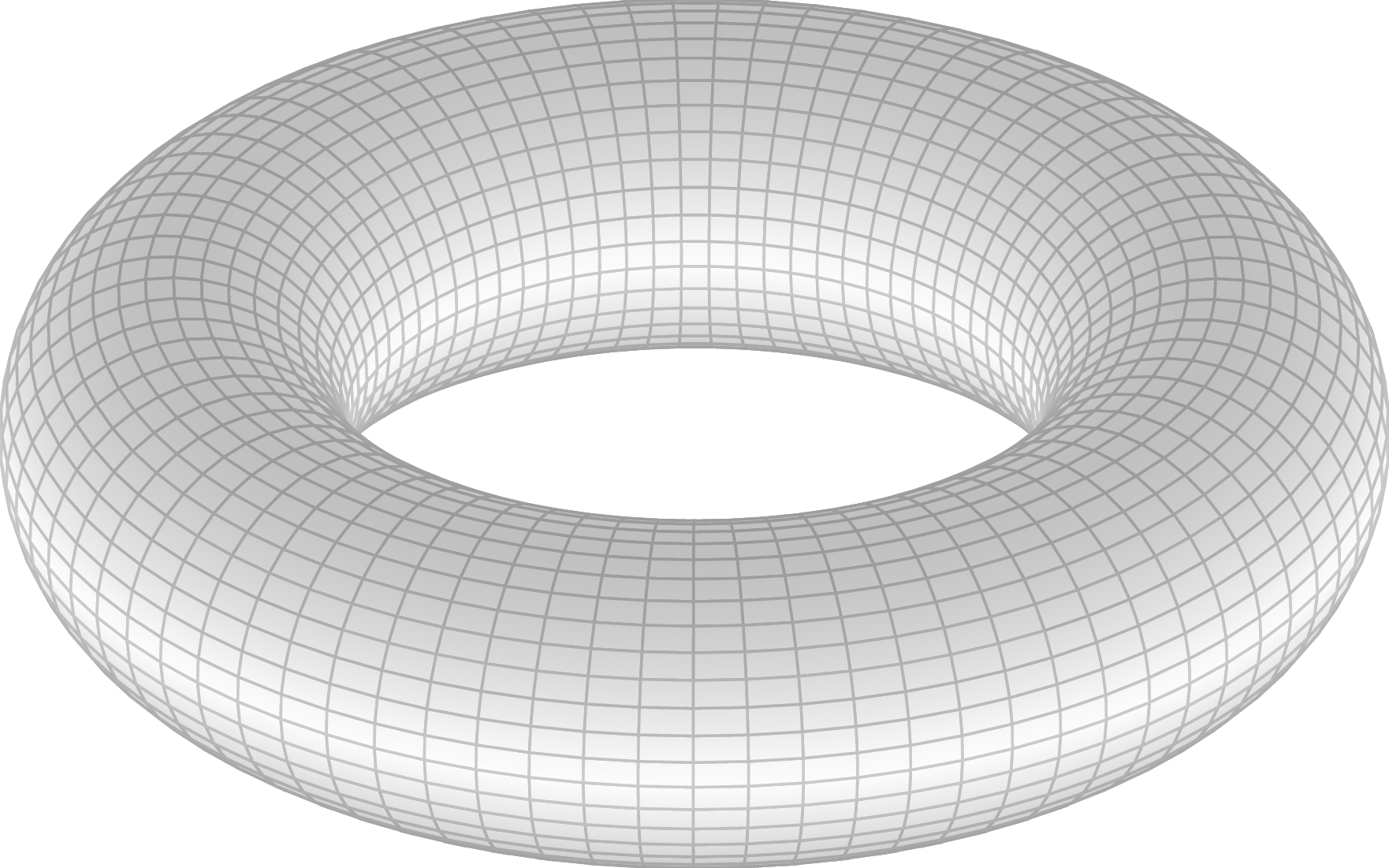
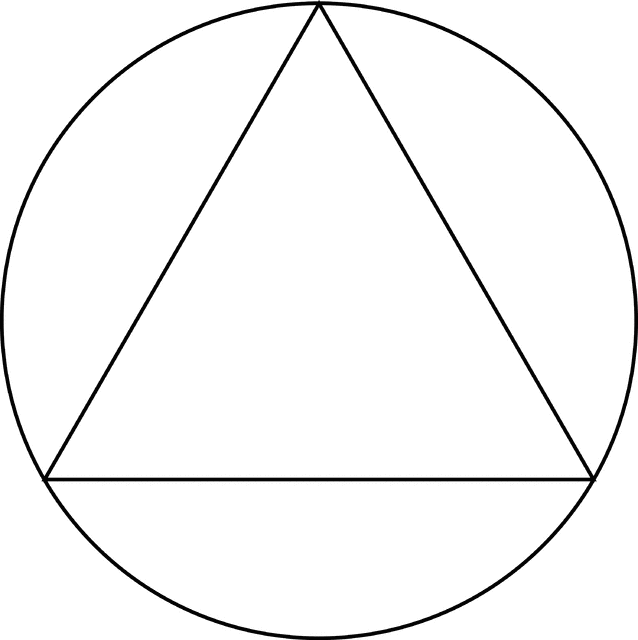
Làm sao để phân biệt hai không gian có tương đương không? Ta có thể thấy điểm khác nhau ở đây là hình xuyến có một lỗ ở giữa, trong khi hình lập phương và hình cầu là một khối đặc. Như vậy, số lượng "lỗ" cũng như loại của nó (hãy xem xét hình xuyến với một mặt cầu) của không gian là một tính chất có thể dùng để so sánh.
Giả sử chúng ta muốn đếm số lỗ của một đường tròn, yêu cầu tất cả các điểm trên đường tròn đó. Điều này có thể thực hiện một cách đơn giản hơn bằng cách xấp xỉ đường tròn bởi 1 hình tam giác. Lúc này dữ kiện yêu cầu chỉ đơn giản là 3 đỉnh và 3 cạnh, từ đây ta biết rằng 3 cạnh này tạo thành 1 đường khép kín, vậy có 1 lỗ, và lỗ này có số chiều là 1 do được bao bọc bởi ba đoạn thẳng 1 chiều.
Đối với lỗ có số chiều cao hơn, ta có thể mở rộng cách làm bên trên. Thay vì dùng đoạn thẳng 1 chiều xác định bởi 2 đầu mút, ta có thể dùng mở rộng chiều của nó, gọi là một đơn hình, định nghĩa bởi một tập điểm sao cho với 2 điểm bất kì có cạnh nối giữa chúng. Một ví dụ là xấp xỉ mặt cầu bởi 1 tứ diện, mỗi mặt của tứ diện này sẽ là một đơn hình, định nghĩa bởi 3 đỉnh và 3 cạnh. Một tính chất của đơn hình là mỗi mặt của một đơn hình sẽ là một đơn hình, ví dụ cạnh của đơn hình (hình tam giác) là đơn hình (đoạn thẳng). Tập hợp tất cả đơn hình của một cách xấp xỉ được gọi là phức đơn hình.
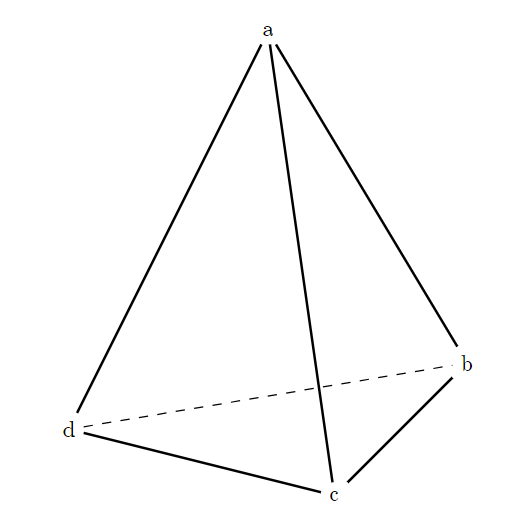
Quay lại với việc đếm số lỗ, ta sẽ cần định nghĩa một toán tử biên ánh xạ từ các đơn hình sang các đơn hình là các biên của chúng. Với một tập các đơn hình, ta có thể xét chúng có kết hợp với nhau tạo thành 1 lỗ hay không bằng cách xét biên của các đơn hình này có khép kín hay không. Tuy nhiên điều này là chưa đủ. Xét tứ diện khuyết mặt đáy , ta có thể thấy dù tạo thành một chu trình, nhưng do chúng có thể tạo thành từ biên của , vì vậy không tạo thành lỗ. Ta sẽ định nghĩa nhóm đồng điều thứ là các chu trình sinh bởi đơn hình mà không thể tạo ra từ các biên của các đơn hình, hay chính xác hơn là nhóm thương của các chu trình tạo bởi đơn hình với biên của các đơn hình. Số phần tử sinh của nhóm này sẽ tương ứng với số lỗ bậc cần tìm.
Đồng điều bền vững
Ở phần trên chúng ta đã tìm hiểu cách để đếm số lỗ khi xấp xỉ không gian bởi tập các đơn hình. Vấn đề ở đây là làm thế nào để xây dựng một cách xấp xỉ như vậy từ một tập hữu hạn điểm, tương ứng với các sample của mô hình sinh cũng như của phân bố dữ liệu. Dễ thấy rằng cấu trúc đơn hình bên trên tương đương với một đồ thị, trong đó đơn hình là đỉnh, đơn hình là cạnh, đơn hình là đồ thị con đầy đủ gồm đỉnh. Như vậy vấn đề trở thành tìm dạng đồ thị của tập các điểm dữ liệu. Các cách dựng đồ thị khác nhau sẽ tạo ra các phức đơn hình khác nhau, từ đó sinh ra các nhóm đồng điều khác nhau.
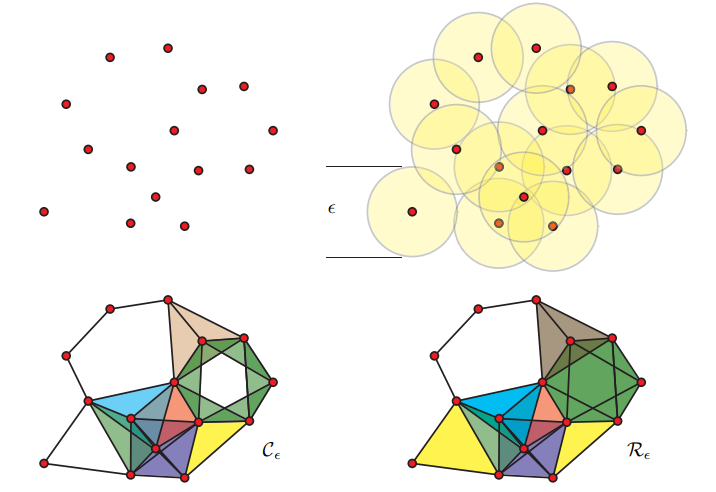
Cách xấp xỉ đơn giản nhất là sử dụng phức Rips. Với hằng số , ta định nghĩa một cạnh nối giữa hai điểm nếu . Vấn đề ở đây là làm thế nào để tìm ra xấp xỉ tốt nhất. Nếu quá bé, đồ thị sẽ thưa, các điểm không liên kết với nhau. Nếu lớn, các điểm sẽ liên kết quá dễ dàng, và trong trường hợp quá lớn, dữ liệu xấp xỉ sẽ tương đương với một hình khối đặc.
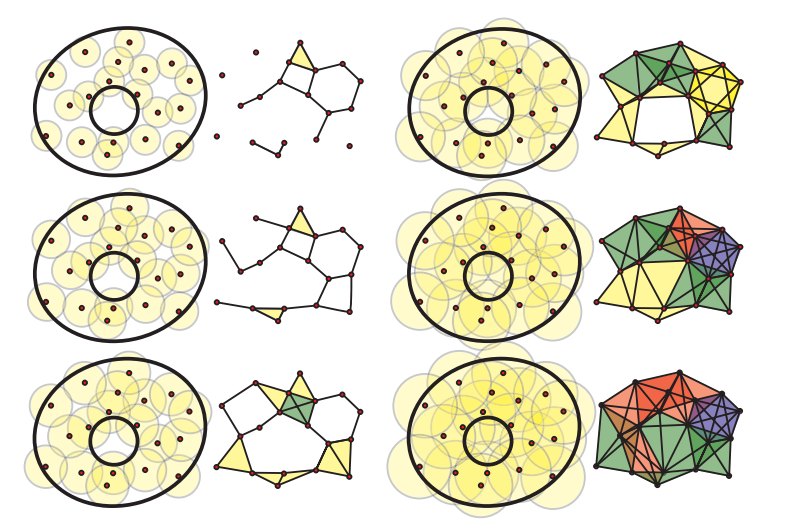
Cách làm ở đây là tăng dần . Khi lớn dần, các điểm bắt đầu kết nối với nhau để tạo thành lỗ bậc 1, sau đó các đơn hình bậc cao dần dần xuất hiện để tạo thành lỗ bậc cao hơn, cùng lúc đó lỗ bậc thấp lại biến mất do xuất hiện thêm cạnh trong chúng. Trong toàn bộ quá trình này, sẽ có những lỗ được tính là nhiễu. Những lỗ được chọn sẽ là những lỗ bền vững, tức là những lỗ có thời gian tồn tại đủ lâu theo tham số . Ta có thể dựng ra mã vạch tương ứng với thời gian tồn tại của các phần tử sinh của các nhóm đồng điều để khảo sát điều này.
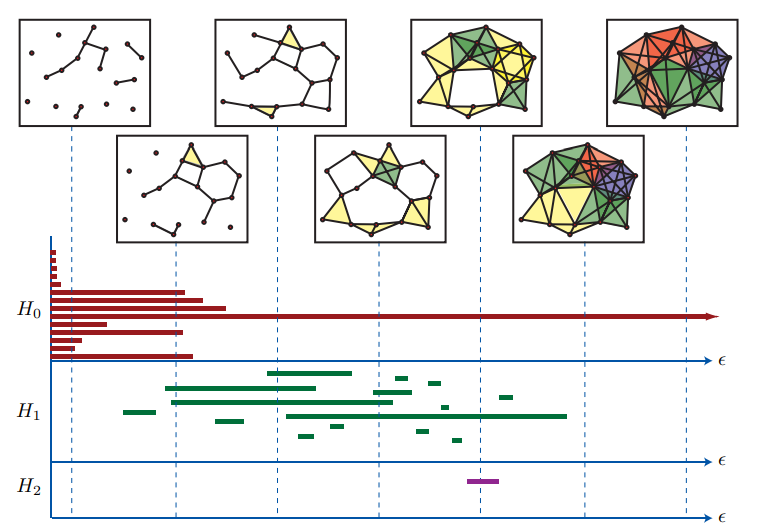
Ngoài phức Rips, ta cũng có những cách khác để dựng nhóm đồng điều, ví dụ như phức Cech, phức witness; trong đó phức witness hiệu quả với số lượng điểm lớn. Tương tự như phức Rips, các cách làm này cũng dùng tham số để xây dựng nhóm đồng điều một cách từ từ, do đó có thể tính mã vạch tương tự như trên. Các đối tượng này có thể tính toán với numpy và thư viện GUDHI.
So sánh dữ liệu với Geometry score
Dựa vào những công cụ trên, chúng ta có thể định nghĩa một chỉ số so sánh giữa 2 tập dữ liệu. Chúng ta đã có mã vạch ứng với thời gian xuất hiện, mục tiêu của chúng ta là tìm ra số các lỗ, tức là số phần tử sinh thực sự của nhóm đồng điều. Thay vì tìm giá trị chính xác, chúng ta sẽ tìm phân bố của giá trị này trên tập các giá trị cho trước.
Tại mỗi thời điểm , chúng ta sẽ định nghĩa số các phần tử sinh của nhóm đồng điều thứ đang xuất hiện tại thời điểm đó như sau
ở đây là tập của các khoảng thời gian tồn tại của các phần tử sinh nhóm đồng điều thứ .
Thời gian tồn tại trung bình (Relative living times - RLT) của số các phần tử sinh của nhóm đồng điều thứ sẽ được định nghĩa là xác suất theo để
Phân bố chúng ta cần tìm sẽ là . Sau khi đã có phân bố của số các phần tử sinh của nhóm đồng điều, chúng ta có thể so sánh sự tương đồng giữa hai tập dữ liệu bằng cách so sánh 2 phân bố này. Để đơn giản, chúng ta chỉ cần sử dụng các nhóm đồng điều thứ 1, tức là . Với tập dữ liệu , ta sẽ so sánh và khoảng cách hoặc mê tríc Wasserstein. Chỉ số này được gọi là Geometry Score
Thử nghiệm
Kết quả dưới đây được lấy từ bài báo gốc của Geometry score. Tác giả thử nghiệm với mô hình DCGAN trên bộ CelebA, so sánh với mô hình DCGAN kích cỡ nhỏ hơn, có latent dimension là , gọi là bad-DCGAN.
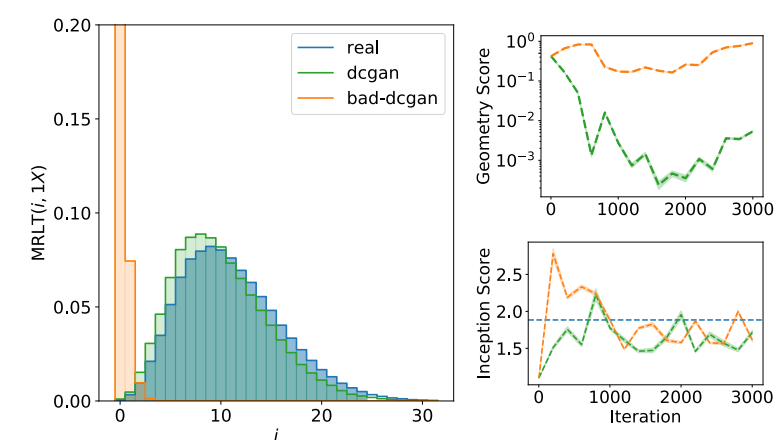
Ta có thể thấy GeomScore của DCGAN giảm nhanh trong quá trình train, trong khi của bad-DCGAN không có dấu hiệu giảm, thể hiện mô hình này không học được đặc trưng tô pô của dữ liệu. Minh họa của phân bố cho thấy mô hình bad-DCGAN lệch hẳn về , tức là gần như không xuất hiện lỗ trên không gian của mô hình này, không gian này gần như một khối đặc. Mặt khác, chỉ số IS của hai mô hình lại tương đồng, thể hiện rằng đây có thể không phải một chỉ số phù hợp để đánh giá mô hình sinh.
Kết
Chúng ta đã tìm hiểu về tô pô của dữ liệu với công cụ là nhóm đồng điều bền vững, cùng với đó là một chỉ số để đánh giá mô hình sinh. Cần lưu ý rằng chỉ số này không nên xem là tối hậu, vì nó chỉ thể hiện đặc trưng tô pô của dữ liệu. Giả sử không gian bị lệch đi một vector, tính chất tô pô của nó không đổi, nhưng hai không gian này đã khác nhau rồi. Tuy nhiên, mình nghĩ chỉ số này có thể dùng để đánh giá self-supervised models khi hầu hết các phương pháp này đều khẳng định vector biểu diễn thể hiện tính chất hình học của dữ liệu, mặc dù việc này yêu cầu vector biểu diễn có cùng số chiều với dữ liệu ban đầu, do đó không dễ để sử dụng.





