Khắc phục và ngăn ngừa các vấn đề về hiệu suất là rất quan trọng đối với sự thành công của bất kỳ ứng dụng nào. Chúng ta sử dụng nhiều công cụ và phương pháp khác nhau để cung cấp một tập hợp các kỹ thuật có thể được sử dụng để phân tích và tăng hiệu suất!
Tối ưu hóa khiến chúng ta giống như một nhà trinh thám vậy. Nhận một cơn ác mộng về hiệu suất và điều chỉnh nó thành một thứ gì đó nhanh chóng và đẹp mắt mang lại cảm giác tuyệt vời và chắc chắn sẽ khiến người khác hài lòng. Amazing! Một điều gì đó khủng khiếp đã xảy ra và chúng ta cần lần theo manh mối để xác định vị trí và bắt được thủ phạm! Loạt bài viết này là sẽ đưa ra những manh mối, cách xác định và sử dụng chúng để tìm ra nguyên nhân gốc rễ của sự cố hiệu suất.
Tìm hiểu về tối ưu truy vấn và vô tình tìm được 1 blog rất hay này, nên mình quyết định làm series này để dịch các bài viết hay về tối ưu truy vấn, giúp mọi người dễ theo dõi và tìm hiểu hơn. Bài viết gốc mình có để trong danh mục tài liệu cuối bài viết, mọi người có thể truy cập để hiểu rõ hơn.
Bài dịch đầu tiên chúng ta sẽ giúp ta nhớ lại những kiến thức nền tảng cơ bản về tối ưu hóa và các vấn đề phổ biến liên quan đến tối ưu hóa truy vấn.
Tối ưu hóa là gì ?
"Tối ưu" là gì? Câu trả lời cho điều này cũng sẽ xác định khi nào chúng ta giải quyết xong một vấn đề và có thể chuyển sang vấn đề tiếp theo. Thông thường, một truy vấn có thể được tăng tốc thông qua nhiều phương tiện khác nhau, mỗi phương tiện đều có thời gian và chi phí tài nguyên liên quan.
Chúng ta thường không thể dành các nguồn lực cần thiết để làm cho một tập lệnh chạy nhanh nhất có thể, và chúng ta cũng không nên làm như vậy. Vì mục đích đơn giản, chúng ta sẽ định nghĩa "tối ưu" là điểm mà tại đó truy vấn thực hiện một cách chấp nhận được và sẽ tiếp tục làm như vậy trong một khoảng thời gian hợp lý trong tương lai. Đây là một định nghĩa kinh doanh giống như một định nghĩa kỹ thuật. Với vô hạn tiền bạc, thời gian và tài nguyên máy tính, mọi thứ đều có thể thực hiện được, nhưng chúng ta không có quyền sở hữu nguồn tài nguyên không giới hạn, và do đó phải xác định những điều chúng ta đã làm là gì bất cứ khi nào chúng ta theo đuổi bất kỳ vấn đề hiệu suất nào.
Điều này cung cấp cho chúng ta một số điểm kiểm tra hữu ích để đánh giá lại tiến trình tối ưu hóa:
- Truy vấn hiện thực hiện đầy đủ.
- Các tài nguyên cần thiết để tối ưu hóa hơn nữa là rất tốn kém.
- Chúng tôi đã đạt đến điểm giảm dần lợi nhuận cho bất kỳ tối ưu hóa nào tiếp theo.
- Một giải pháp hoàn toàn khác được phát hiện làm cho điều này không cần thiết. Tối ưu hóa quá mức có vẻ là không tốt, vì xét trong bối cảnh quản lý tài nguyên nói chung là lãng phí. Một chỉ mục bao trùm khổng lồ (nhưng không cần thiết) sẽ tiêu tốn tài nguyên máy tính của chúng ta bất cứ khi nào chúng ta ghi vào một bảng trong thời gian dài. Một dự án viết lại mã đã được chấp nhận có thể tốn nhiều ngày hoặc nhiều tuần phát triển và thời gian QA. Cố gắng điều chỉnh thêm một truy vấn vốn đã tốt có thể thu được 3% hiệu suất, nhưng phải mất một tuần đổ mồ hôi mới đạt được điều đó.
Do đó, mục tiêu là giải quyết một vấn đề và không giải quyết nó quá mức.
Truy vấn làm gì?
Câu hỏi số 1 mà chúng ta phải luôn trả lời là: Mục đích của truy vấn là gì?
- Mục đích của nó là gì?
- Tập hợp kết quả sẽ như thế nào?
- Thao tác hoặc giao diện người dùng nào đang tạo truy vấn? Bản chất đầu tiên là chúng ta muốn lao vào với một thanh kiếm trên tay và giết con rồng càng nhanh càng tốt. Chúng tôi có trong tay một dấu vết đang chạy, kế hoạch thực hiện và một đống số liệu thống kê về thời gian và IO được thu thập trước khi nhận ra rằng chúng tôi không biết mình đang làm gì 🙂
Bước # 1 là quay lại và hiểu truy vấn. Một số câu hỏi hữu ích có thể hỗ trợ tối ưu hóa:
- Tập kết quả lớn đến mức nào? Có nên gồng mình lên để trả về một triệu hàng, hay chỉ một vài hàng?
- Có bất kỳ tham số nào có giá trị giới hạn không? Nó có thể đơn giản hóa công việc của chúng ta bằng cách loại bỏ các phương pháp nghiên cứu.
- Truy vấn được thực thi bao lâu một lần? Điều gì đó xảy ra một lần một ngày sẽ được xử lý rất khác so với một thứ xảy ra mỗi giây.
- Có giá trị đầu vào nào không hợp lệ hoặc bất thường cho thấy sự cố ứng dụng không? Một input được đặt thành NULL, nhưng không bao giờ nên là NULL? Có bất kỳ input nào khác được đặt thành các giá trị không có ý nghĩa, mâu thuẫn hoặc đi ngược lại trường hợp sử dụng của truy vấn không?
- Có bất kỳ vấn đề logic, cú pháp hoặc tối ưu hóa nào chúng ta đang phải đối mặt? Chúng ta có thấy bất kỳ quả bom hiệu suất tức thời nào sẽ luôn hoạt động kém, bất kể giá trị tham số hoặc các biến nào?
- Hiệu suất truy vấn chấp nhận được là bao nhiêu? Truy vấn phải nhanh đến mức nào để người tiêu dùng hài lòng? Nếu hiệu suất máy chủ kém, cần giảm mức tiêu thụ tài nguyên đến mức nào để có thể chấp nhận được? Cuối cùng, hiệu suất hiện tại của truy vấn là gì? Điều này sẽ cung cấp đường cơ sở để chúng ta biết mức độ cần thiết phải cải thiện. Bằng cách dừng lại và hỏi những câu hỏi này trước khi tối ưu hóa một truy vấn, ta có thể tránh được tình huống khó chịu khi dành hàng giờ để thu thập dữ liệu về một truy vấn chỉ để không hiểu đầy đủ về cách sử dụng nó. Theo nhiều cách, tối ưu hóa truy vấn và thiết kế cơ sở dữ liệu buộc chúng ta phải hỏi nhiều câu hỏi giống nhau.
Kết quả của từ việc trả lời bổ sung các câu hỏi này thường sẽ dẫn chúng ta đến các giải pháp sáng tạo hơn. Có thể không cần chỉ mục mới và chúng ta có thể chia một truy vấn lớn thành một vài truy vấn nhỏ hơn. Có thể một giá trị tham số không chính xác và có sự cố trong mã hoặc giao diện người dùng cần được giải quyết. Có thể báo cáo được chạy mỗi tuần một lần, vì vậy chúng tôi có thể lưu trước bộ dữ liệu vào bộ nhớ cache và gửi kết quả đến email, trang tổng quan hoặc tệp, thay vì buộc người dùng phải đợi 10 phút cho nó tương tác.
Trình Tối ưu hoá Truy vấn làm gì?
Mọi truy vấn đều tuân theo cùng một quy trình cơ bản từ TSQL đến khi hoàn thành việc thực thi trên SQL Server:

Parsing - Phân tích cú pháp là quá trình kiểm tra cú pháp truy vấn. Các từ khóa có hợp lệ không và các quy tắc của ngôn ngữ TSQL có được tuân thủ một cách chính xác hay không. Nếu bạn mắc lỗi chính tả, đặt tên cột bằng từ dành riêng hoặc quên dấu chấm phẩy trước biểu thức bảng thông thường, đây là nơi bạn sẽ nhận được thông báo lỗi thông báo cho bạn về những vấn đề đó.
Binding kiểm tra tất cả các đối tượng được tham chiếu trong TQL của bạn so với danh mục hệ thống và bất kỳ đối tượng tạm thời nào được xác định trong code của bạn để xác định xem chúng có hợp lệ và được tham chiếu chính xác hay không. Thông tin về các đối tượng này được truy xuất, chẳng hạn như kiểu dữ liệu, ràng buộc và liệu một cột có cho phép NULL hay không. Kết quả của bước này là một cây truy vấn bao gồm một danh sách cơ bản của các quy trình cần thiết để thực hiện truy vấn. Điều này cung cấp các hướng dẫn cơ bản, nhưng chưa bao gồm các chi tiết cụ thể, chẳng hạn như lập chỉ mục hoặc kết hợp nào để sử dụng.
Optimization - Tối ưu hóa là quá trình mà chúng ta sẽ tham khảo thường xuyên nhất ở đây. Trình tối ưu hóa hoạt động tương tự như máy tính chơi cờ vua (hoặc bất kỳ trò chơi nào). Nó cần phải xem xét một số lượng lớn các nước đi càng nhanh càng tốt, loại bỏ các lựa chọn kém và kết thúc với nước đi tốt nhất có thể. Tại bất kỳ thời điểm nào, máy tính có thể có hàng triệu tổ hợp các bước di chuyển, trong đó chỉ một số ít các bước di chuyển tốt nhất có thể. Bất cứ ai đã chơi cờ vua với máy tính đều biết rằng máy tính càng ít thời gian thì càng dễ mắc lỗi.
Trong thế giới của SQL Server, chúng ta sẽ nói về các kế hoạch thực thi thay vì các nước cờ. Kế hoạch thực thi là tập hợp các bước cụ thể mà công cụ thực thi sẽ tuân theo để xử lý một truy vấn. Mọi truy vấn đều có nhiều lựa chọn để đạt được kế hoạch thực thi đó và phải thực hiện trong một khoảng thời gian rất ngắn.
Những lựa chọn này bao gồm các câu hỏi như:
- Thứ tự các bảng nên được join?
- Những phép join nào nên được áp dụng cho các bảng?
- Những chỉ mục nào nên được sử dụng?
- Có lợi ích nào trong việc lưu dữ liệu vào bộ nhớ đệm để sử dụng trong tương lai không? Bất kỳ kế hoạch thực thi nào được trình tối ưu hóa xem xét đều phải trả lại kết quả giống nhau, nhưng hiệu suất của mỗi kế hoạch có thể khác nhau do những câu hỏi ở trên (và nhiều hơn nữa!).
Tối ưu hóa truy vấn là một hoạt động sử dụng nhiều CPU. Quá trình sàng lọc các kế hoạch đòi hỏi tài nguyên máy tính đáng kể và để tìm ra kế hoạch tốt nhất có thể cần nhiều thời gian hơn khả năng hiện có. Do đó, phải duy trì sự cân bằng giữa các tài nguyên cần thiết để tối ưu hóa truy vấn, các tài nguyên cần thiết để thực hiện truy vấn và thời gian chúng ta phải đợi toàn bộ quá trình hoàn tất. Do đó, trình tối ưu hóa không được xây dựng để chọn kế hoạch thực thi tốt nhất mà thay vào đó để tìm kiếm và tìm ra kế hoạch tốt nhất có thể sau một khoảng thời gian nhất định trôi qua. Nó có thể không phải là kế hoạch thực thi hoàn hảo, nhưng chúng ta chấp nhận rằng đó là một hạn chế về cách một quy trình có rất nhiều khả năng phải hoạt động.
Chỉ số được sử dụng để đánh giá kế hoạch thực thi và đưa ra quyết định là chi phí truy vấn. Chi phí không có đơn vị và là một thước đo tương đối của các nguồn lực cần thiết để thực hiện từng bước của một kế hoạch thực hiện. Chi phí truy vấn tổng thể là tổng chi phí của mỗi bước trong một truy vấn. Bạn có thể xem các chi phí này trong bất kỳ kế hoạch thực hiện nào:
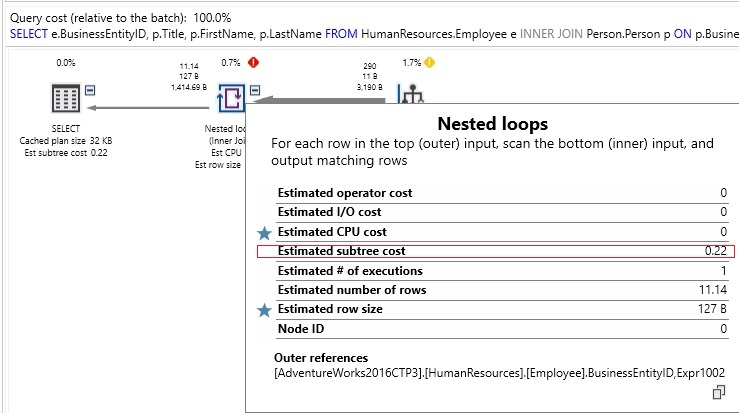
Chi phí cây con cho mỗi thành phần của truy vấn được tính toán và sử dụng để:
- Loại bỏ kế hoạch thực hiện chi phí cao và bất kỳ kế hoạch tương tự nào khỏi nhóm các kế hoạch đã có.
- Xếp hạng các kế hoạch còn lại dựa trên mức độ thấp của chi phí.
Mặc dù chi phí truy vấn là một số liệu hữu ích để hiểu cách SQL Server đã tối ưu hóa một truy vấn cụ thể, điều quan trọng cần nhớ là mục đích chính của nó là hỗ trợ trình tối ưu hóa truy vấn trong việc lựa chọn kế hoạch thực thi tốt. Nó không phải là thước đo trực tiếp của IO, CPU, bộ nhớ, thời lượng hoặc bất kỳ số liệu nào khác mà quan trọng đối với người dùng ứng dụng khi chờ quá trình thực thi truy vấn hoàn tất. Chi phí truy vấn thấp có thể không chỉ ra một truy vấn nhanh hoặc kế hoạch tốt nhất. Ngoài ra, chi phí truy vấn cao đôi khi có thể được chấp nhận. Do đó, tốt nhất là không nên dựa nhiều vào chi phí truy vấn làm thước đo hiệu suất.
Khi trình tối ưu hóa truy vấn lướt qua các kế hoạch thực thi ứng viên, nó sẽ xếp hạng chúng từ chi phí thấp nhất đến chi phí cao nhất. Cuối cùng, trình tối ưu hóa sẽ đạt được một trong các kết luận sau:
- Mọi kế hoạch thực hiện đã được đánh giá và lựa chọn tốt nhất.
- Không có đủ thời gian để đánh giá mọi kế hoạch và kế hoạch tốt nhất cho đến nay đã được chọn. Khi một kế hoạch thực thi được chọn, công việc của trình tối ưu hóa truy vấn đã hoàn tất và chúng ta có thể chuyển sang bước cuối cùng của quá trình xử lý truy vấn.
Execution - Thực hiện là bước cuối cùng. SQL Server nhận kế hoạch thực thi đã được xác định trong bước tối ưu hóa và làm theo các hướng dẫn đó để thực hiện truy vấn.
Lưu ý về việc tái sử dụng kế hoạch thực thi (plan reuse): Bởi vì tối ưu hóa là một quá trình vốn dĩ rất tốn kém, SQL Server duy trì một bộ đệm ẩn kế hoạch thực thi để lưu trữ thông tin chi tiết về từng truy vấn được thực thi trên máy chủ và kế hoạch đã được chọn cho nó. Thông thường, cơ sở dữ liệu trải qua cùng một truy vấn được thực hiện lặp đi lặp lại, chẳng hạn như tìm kiếm trên web, vị trí đặt hàng hoặc bài đăng trên mạng xã hội. Việc sử dụng lại cho phép chúng tôi tránh quá trình tối ưu hóa tốn kém và dựa vào công việc chúng tôi đã thực hiện trước đó để tối ưu hóa một truy vấn.
Khi một truy vấn được thực hiện mà đã có một kế hoạch hợp lệ trong bộ nhớ cache, thì kế hoạch đó sẽ được chọn, thay vì trải qua quá trình xây dựng một kế hoạch mới. Điều này giúp tiết kiệm tài nguyên máy tính và tăng tốc độ thực thi truy vấn.
Các chủ đề phổ biến trong tối ưu hóa truy vấn
Với phần giới thiệu sơ lược, chúng ta hãy đi sâu vào tối ưu hóa! Sau đây là danh sách các số liệu phổ biến nhất sẽ hỗ trợ tối ưu hóa. Khi các khái niệm cơ bản không thực hiện được, chúng ta có thể sử dụng các quy trình cơ bản này để xác định các thủ thuật, mẹo và các mẫu trong cấu trúc truy vấn có thể chỉ ra hiệu suất kém.
Index scan - Quét chỉ mục
Dữ liệu có thể được truy cập từ một chỉ mục thông qua scan hoặc tìm kiếm. Tìm kiếm là một lựa chọn có mục tiêu các hàng từ bảng dựa trên một bộ lọc hẹp (thường). Scan là khi toàn bộ chỉ mục được tìm kiếm để trả về dữ liệu được yêu cầu. Nếu một bảng chứa một triệu hàng, thì quá trình scan sẽ cần phải duyệt qua tất cả triệu hàng để phục vụ truy vấn. Một tìm kiếm của cùng một bảng có thể duyệt nhanh cây nhị phân của chỉ mục để chỉ trả về dữ liệu cần thiết mà không cần phải kiểm tra toàn bộ bảng.
Nếu có nhu cầu chính đáng để trả về một lượng lớn dữ liệu từ một bảng, thì scan chỉ mục có thể là thao tác chính xác. Nếu chúng ta cần trả lại 950.000 hàng từ bảng một triệu hàng, thì việc scan chỉ mục có ý nghĩa. Nếu chúng ta chỉ cần trả về 10 hàng, thì một tìm kiếm sẽ hiệu quả hơn nhiều.
Quét chỉ mục rất dễ phát hiện trong các kế hoạch thực thi:
SELECT
*
FROM Sales.OrderTracking
INNER JOIN Sales.SalesOrderHeader
ON SalesOrderHeader.SalesOrderID = OrderTracking.SalesOrderID
INNER JOIN Sales.SalesOrderDetail
ON SalesOrderDetail.SalesOrderID = SalesOrderHeader.SalesOrderID
WHERE OrderTracking.EventDateTime = '2014-05-29 00:00:00';
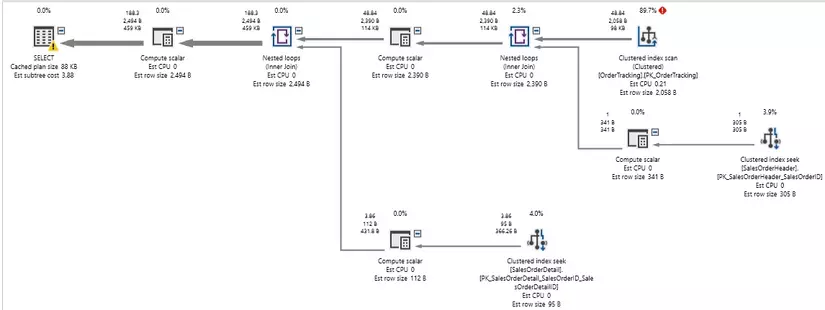
Chúng ta có thể nhanh chóng phát hiện quá trình quét chỉ mục ở góc trên bên phải của kế hoạch thực thi. Việc sử dụng 90% tài nguyên của truy vấn và được gắn nhãn là quét chỉ mục theo cụm nhanh chóng cho chúng tôi biết điều gì đang xảy ra ở đây. THỐNG KÊ IO cũng cho chúng ta thấy một số lượng lớn các lần đọc so với bảng OrderTracking :

Nhiều giải pháp có sẵn khi chúng ta đã xác định được một lần quét chỉ mục không mong muốn. Dưới đây là danh sách nhanh một số suy nghĩ cần xem xét khi giải quyết sự cố quét chỉ mục:
- Có index nào có thể xử lý filter trong truy vấn không?
- Trong ví dụ này, có index trên EventDateTime không?
- Nếu không có index nào, chúng ta có nên tạo một index để cải thiện hiệu suất trên truy vấn không?
- Truy vấn này có được thực thi thường xuyên đủ để đảm bảo thay đổi này không? Các index cải thiện tốc độ đọc trên các truy vấn, nhưng sẽ làm giảm tốc độ ghi, vì vậy chúng ta nên thêm chúng một cách thận trọng.
- Đây có phải là filter hợp lệ không? Cột này có phải là cột mà không ai nên filter không?
- Chúng ta có nên thảo luận vấn đề này với những người chịu trách nhiệm về ứng dụng để xác định cách tốt hơn để tìm kiếm dữ liệu này không?
- Có một số mẫu truy vấn khác đang gây ra quá trình quét chỉ mục mà chúng ta có thể giải quyết không? Chúng ta sẽ cố gắng trả lời cặn kẽ hơn câu hỏi này dưới đây. Nếu có một chỉ mục trên cột filter ( EventDataTime trong ví dụ này), thì có thể có một số trò tai quái khác ở đây cần chúng ta chú ý!
- Có phải truy vấn mà không có cách nào để tránh bị quét không?
- Một số filter truy vấn là bao gồm tất cả và cần phải tìm kiếm toàn bộ bảng. Trong vd trên, nếu EventDateTIme xảy ra bằng “5-29-2014” ở mọi hàng trong Sales.OrderTracking , thì quá trình quét sẽ được mong đợi. Tương tự, nếu chúng ta thực hiện tìm kiếm chuỗi mờ, việc quét chỉ mục sẽ khó tránh khỏi việc triển khai Chỉ mục toàn văn bản hoặc một số tính năng tương tự. Khi xem qua các ví dụ khác, chúng ta sẽ tìm thấy nhiều cách khác nhau để xác định và giải quyết các lần quét chỉ mục không mong muốn.
Các function được bọc trong JOIN và WHERE
Một chủ đề trong tối ưu hóa là tập trung liên tục vào các phép JOIN và mệnh đề WHERE. Vì IO nói chung là chi phí lớn nhất và đây là những thành phần truy vấn có thể hạn chế IO nhiều nhất, chúng ta thường tìm thấy những sai lầm tồi tệ nhất của mình ở đây. Chúng ta có thể chia nhỏ tập dữ liệu của mình xuống chỉ những hàng chúng ta cần càng nhanh, thì việc thực thi truy vấn sẽ càng hiệu quả!
Khi đánh giá mệnh đề WHERE, bất kỳ biểu thức nào liên quan cần phải được giải quyết trước khi trả lại dữ liệu của chúng ta. Nếu một cột chứa các hàm xung quanh nó, chẳng hạn như DATEPART, SUBSTRING hoặc CONVERT, thì các hàm này cũng sẽ cần được giải quyết. Nếu hàm phải được đánh giá trước khi thực thi để xác định tập kết quả, thì toàn bộ tập dữ liệu sẽ cần được quét để hoàn thành đánh giá đó.
Hãy xem xét truy vấn sau:
SELECT
Person.BusinessEntityID,
Person.FirstName,
Person.LastName,
Person.MiddleName
FROM Person.Person
WHERE LEFT(Person.LastName, 3) = 'For';
Điều này sẽ trả về bất kỳ hàng nào từ Person có họ bắt đầu bằng “For”. Đây là cách truy vấn thực hiện:
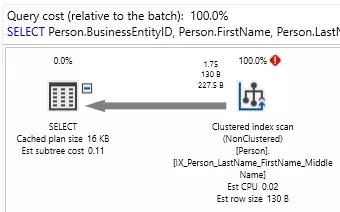

Mặc dù chỉ trả về 4 hàng, toàn bộ chỉ mục đã được quét để trả về dữ liệu. Lý do là việc sử dụng LEFT trên Person.LastName . Mặc dù truy vấn đúng về mặt logic và sẽ trả về dữ liệu chúng ta muốn, nhưng SQL Server sẽ cần đánh giá LEFT so với mọi hàng trong bảng trước khi có thể xác định hàng nào phù hợp với bộ lọc. Điều này buộc phải quét chỉ mục, nhưng may mắn là có thể tránh được một chỉ mục!
Khi đối mặt với các hàm trong mệnh đề WHERE hoặc trong một phép nối, hãy xem xét các cách để chuyển hàm vào biến vô hướng. Ngoài ra, hãy nghĩ cách viết lại truy vấn theo cách mà các cột trong bảng có thể được giữ sạch (nghĩa là: không có chức năng nào được đính kèm với chúng!)
Truy vấn ở trên có thể được viết lại để thực hiện điều này:
SELECT
Person.BusinessEntityID,
Person.FirstName,
Person.LastName,
Person.MiddleName
FROM Person.Person
WHERE Person.LastName LIKE 'For%';
Bằng cách sử dụng LIKE và chuyển logic ký tự đại diện thành chuỗi ký tự, chúng ta đã xóa cột LastName , cột này sẽ cho phép SQL Server toàn quyền truy cập để tìm kiếm. Đây là hiệu suất chúng ta thấy trên phiên bản viết lại:


Điều chỉnh truy vấn tương đối nhỏ mà chúng ta thực hiện đã cho phép trình tối ưu hóa truy vấn sử dụng tìm kiếm chỉ mục và kéo dữ liệu chúng ta muốn chỉ với 2 lần đọc logic, thay vì 117.
Chủ đề của kỹ thuật tối ưu hóa này là đảm bảo rằng các cột được giữ sạch sẽ! Khi viết truy vấn, hãy thoải mái đặt logic string/date/numeric phức tạp vào các biến hoặc tham số vô hướng, nhưng không đặt trên cột. Nếu bạn đang khắc phục sự cố một truy vấn hoạt động kém và các chức năng thông báo (hệ thống hoặc do người dùng xác định) được bao bọc xung quanh tên cột, thì hãy bắt đầu nghĩ cách đẩy các chức năng đó vào các phần vô hướng khác của truy vấn. Điều này sẽ cho phép SQL Server tìm kiếm các chỉ mục, thay vì quét và do đó đưa ra các quyết định hiệu quả nhất có thể khi thực hiện truy vấn!
Implicit Conversions - Chuyển đổi ngầm định
Trước đó, chúng ta đã trình bày cách bọc các hàm xung quanh các cột có thể dẫn đến việc quét bảng ngoài ý muốn, làm giảm hiệu suất truy vấn và tăng độ trễ. Chuyển đổi ngầm hoạt động theo cùng một cách nhưng bị che khuất nhiều hơn.
Khi SQL Server so sánh bất kỳ giá trị nào, nó cần phải điều hòa các kiểu dữ liệu. Tất cả các kiểu dữ liệu được chỉ định một mức độ ưu tiên trong SQL Server và kiểu dữ liệu nào có mức độ ưu tiên thấp hơn sẽ được tự động chuyển đổi thành kiểu dữ liệu có mức độ ưu tiên cao hơn. Để biết thêm thông tin về quyền ưu tiên của toán tử, hãy xem liên kết ở cuối bài viết này chứa danh sách đầy đủ.
Một số chuyển đổi có thể diễn ra liền mạch mà không có bất kỳ tác động nào đến hiệu suất. Ví dụ: VARCHAR (50) và VARCHAR (MAX) có thể được so sánh không có vấn đề gì. Tương tự, một TINYINT và BIGINT, DATE và DATETIME, hoặc TIME và một đại diện VARCHAR của một loại TIME. Tuy nhiên, không phải tất cả các kiểu dữ liệu đều có thể được so sánh tự động.
Hãy xem xét truy vấn SELECT sau đây, được lọc dựa trên một cột được lập chỉ mục:
SELECT
EMP.BusinessEntityID,
EMP.LoginID,
EMP.JobTitle
FROM HumanResources.Employee EMP
WHERE EMP.NationalIDNumber = 658797903;
Nhìn lướt qua và chúng ta giả định rằng truy vấn này sẽ dẫn đến việc tìm kiếm chỉ mục và trả lại dữ liệu cho chúng ta khá hiệu quả. Đây là hiệu suất kết quả:


Mặc dù chỉ tìm kiếm một hàng duy nhất so với một cột được lập chỉ mục, chúng ta đã scan bảng. Chuyện gì đã xảy ra thế? Chúng ta nhận được một gợi ý từ kế hoạch thực thi trong dấu chấm than màu vàng trên câu lệnh SELECT:

Di chuột qua toán tử sẽ hiển thị cảnh báo CONVERT_IMPLICIT. Bất cứ khi nào chúng ta thấy điều này, đó là một dấu hiệu cho thấy rằng chúng ta đang so sánh hai kiểu dữ liệu đủ khác biệt với nhau để chúng không thể được chuyển đổi tự động. Thay vào đó, SQL Server chuyển đổi mọi giá trị đơn lẻ trong bảng trước khi áp dụng bộ lọc.
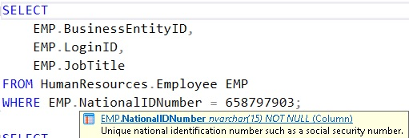
Khi chúng ta di chuột qua cột NationalIDNumber trong SSMS, chúng ta có thể xác nhận rằng thực tế nó là một NVARCHAR (15). Giá trị mà chúng ta đang so sánh với nó là một số. Giải pháp cho vấn đề này rất giống với khi chúng ta có một hàm trên một cột: chuyển đổi sang giá trị vô hướng, thay vì cột. Trong trường hợp này, chúng ta sẽ thay đổi giá trị vô hướng 658797903 thành biểu diễn chuỗi, '658797903':
SELECT
EMP.BusinessEntityID,
EMP.LoginID,
EMP.JobTitle
FROM HumanResources.Employee EMP
WHERE EMP.NationalIDNumber = '658797903'
Thay đổi đơn giản này sẽ thay đổi hoàn toàn cách trình tối ưu hóa truy vấn xử lý truy vấn:
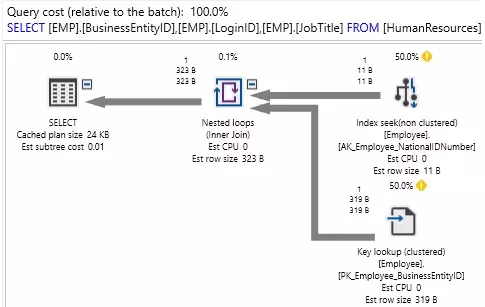

Kết quả là tìm kiếm chỉ mục thay vì quét, ít IO hơn và cảnh báo chuyển đổi ngầm không có trong kế hoạch thực thi.
Chuyển đổi ngầm rất dễ phát hiện vì bạn sẽ nhận được một cảnh báo nổi bật từ SQL Server trong kế hoạch thực thi bất cứ khi nào nó xảy ra. Khi bạn đã giải quyết xong vấn đề này, bạn có thể kiểm tra loại dữ liệu của các cột được chỉ ra trong cảnh báo và giải quyết vấn đề.
Kết luận
Tối ưu hóa truy vấn là một chủ đề lớn có thể dễ dàng trở nên quá tải nếu không có sự tập trung tốt. Cách tốt nhất để tiếp cận vấn đề hiệu suất là tìm các khu vực trọng tâm cụ thể có nhiều khả năng là nguyên nhân gây ra độ trễ. Một thủ tục được lưu trữ có thể dài 10.000 dòng, nhưng chỉ cần một dòng duy nhất cần được giải quyết để giải quyết vấn đề. Trong những tình huống này, việc tìm ra những phần đáng ngờ, tốn kém, tiêu tốn nhiều tài nguyên của tập lệnh có thể nhanh chóng thu hẹp tìm kiếm và cho phép giải quyết một vấn đề hơn là tìm kiếm nó.
Bài viết này đã cung cấp một điểm khởi đầu tốt để giải quyết các vấn đề về độ trễ và hiệu suất. Tối ưu hóa truy vấn đôi khi yêu cầu tài nguyên bổ sung, chẳng hạn như thêm một chỉ mục mới nhưng thường có thể kết thúc như một freebie. Khi có thể cải thiện hiệu suất chỉ bằng cách viết lại một truy vấn, chúng ta giảm tiêu thụ tài nguyên miễn phí (ngoài thời gian của chúng ta). Kết quả là, tối ưu hóa truy vấn có thể là một nguồn tiết kiệm chi phí trực tiếp! Ngoài việc tiết kiệm tiền, tài nguyên và sự tỉnh táo của những người chờ đợi các truy vấn hoàn thành, có rất nhiều sự hài lòng để đạt được bằng cách cải thiện quy trình mà không phải trả thêm bất kỳ chi phí nào cho bất kỳ ai khác.
Cảm ơn bạn đã đọc và chúng ta hãy tiếp tục làm cho mọi thứ diễn ra nhanh hơn!
Tài liệu tham khảo

