Lời mở đầu
Chào các bạn, mấy hôm nay đầu tôi đang tắc tịt nên chả kiếm ra chủ đề nào cả nên mạn phép thông qua bài post của tác giả nước ngoài giới thiệu bài toán nhận diện hành động của người qua video. Link bài viết để ở phần References.
Khái niệm về Human Action Recognition
Human Action Recognition dịch ra là nhận diện hành động con người, có thể chia làm 2 loại: tĩnh và động. Kiểu tĩnh là dạng hành động như đứng, ngồi, nằm, ... , là kiểu hành động không di chuyển trong một khoảng thời gian. Còn kiểu động là mấy hành động như: đi, chạy, nhảy, ... chẳng hạn. Hành động kiểu tĩnh có thể phân loại dễ dàng bằng phân loại ảnh. Trong khi đó kiểu động lại là một chuỗi dịch chuyển của các bộ phận cơ thể người nên dùng phân loại ảnh là không chính xác, mà ta phải xét các frame có chứa hành động đó => phân loại video.
Kiểu động

Kiểu tĩnh

Ngày xưa, nhiều nhà nghiên cứu gắn một cái sensor vào người (điện thoại thông minh, ...) rồi dùng dữ liệu thu được từ sensor đi qua mô hình LSTM để nhận diện như video này chẳng hạn
Dataset cho các bạn muốn vọc: https://archive.ics.uci.edu/ml/datasets/human+activity+recognition+using+smartphones
Kèm theo paper: https://www.researchgate.net/publication/340612128_A_Public_Domain_Dataset_for_Real-Life_Human_Activity_Recognition_Using_Smartphone_Sensors
Ngày nay, thay vì gắn thêm sensor vào người thì các nhà nghiên cứu ứng dụng Computer Vision để nhận diện hành động của người. Ban đầu họ cũng thử Image Classification nhưng lại toang như hình dưới.

Bằng một cách nào đó, cũng với Image Classification, họ đã cải thiện độ chính xác của mô hình trên video. Thay vì lấy kết quả của một frame làm kết quả của video thì giờ họ lấy kết quả của 5, 10, n-frame liên tiếp nhau làm kết quả của video.
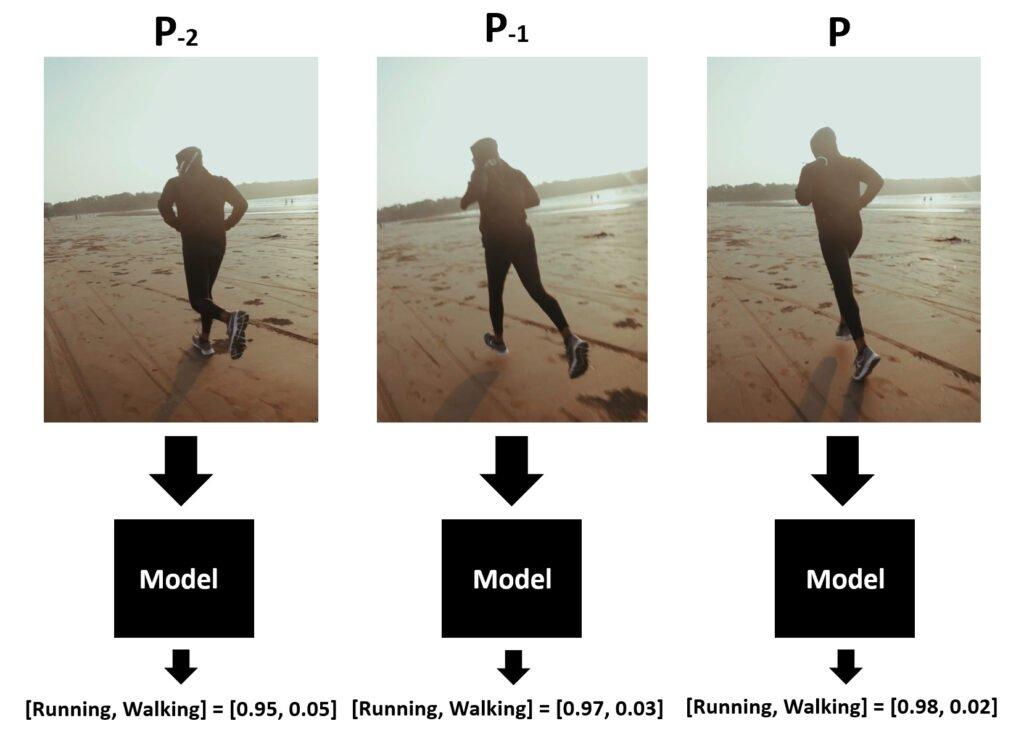
Như trên thì cả 3 frame liền nhau đều predict ra label "Running" với độ chính xác 95%. Vậy ta có thể khẳng định video này là "Running".
P/S: Nếu bạn có đủ nhiều data thì không cần làm trick trên đâu


2 cách này sẽ gây overfit model do chỉ chú trọng context của ảnh mà không chú ý tới hành động của người. Nếu bạn test với một ảnh có màu sắc khác biệt với ảnh train là toang ngay.
Các phương pháp phân loại Video
Single-Frame CNN
Vẫn là Image Classification thôi, dùng model CNN predict từng frame. Rồi lấy trung bình cộng các xác suất độc lập của từng frame để ra xác suất cuối cùng.

Late Fusion
Cũng là dùng CNN predict từng frame nhưng output không còn là xác suất mà là features. Các features này sẽ được merge với nhau ở lớp cuối cùng. Lớp này gọi là lớp fusion, fusion thì có nhiều cách nhưng ở đây tác giả đề xuất dùng max pooling, average pooling hoặc flatten.
Cách này giúp mô hình học thêm các thông tin về không gian, thời gian, chuyển động của người trong từng frame.

Early Fusion
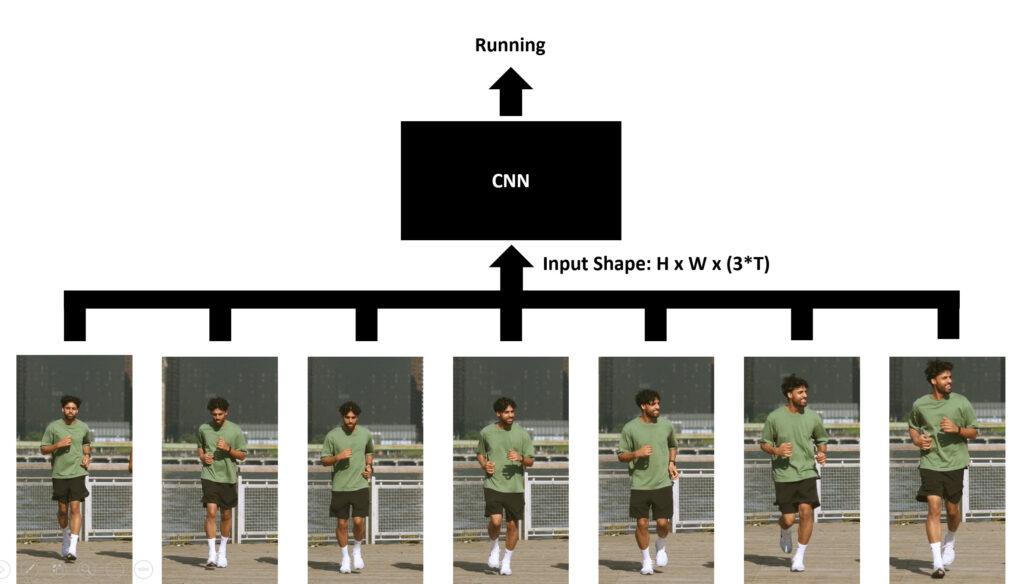
Cách này trái ngược với cách trên, không gian ảnh (một đống pixel) và 3 kênh màu của ảnh (RGB) sẽ được merge vào làm 1 rồi mới đưa vào lớp CNN. Với cách này, thì chỉ cần một layer là đủ bởi kernel của lớp này sẽ sliding window, học di chuyển của từng pixel của các frame liền kề.
Input ban đầu có shape như này: (T x 3 x H x W). Sau khi đi qua fusion thì thành thế này (3T x H x W).
CNN and Bi-directional LSTM
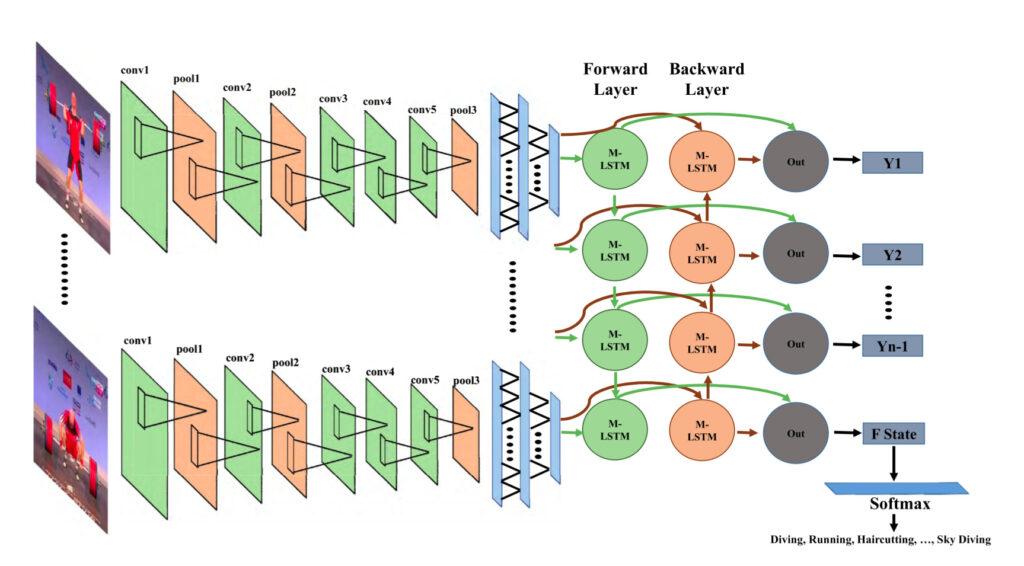
Ý tưởng là cho từng frame đi qua CNN để trích xuất local features. Sau đó đi qua LSTM để học mối quan hệ giữa các features này. Để hiểu sâu thêm thì mời bạn đọc paper này "Action Recognition in Video Sequences using Deep Bi-Directional LSTM With CNN Features " (https://ieeexplore.ieee.org/abstract/document/8121994).
Pose Detection and LSTM
Cách này là dùng keypoints a.k.a các điểm trên cơ thể người mỗi frame cho qua LSTM để xác định hành vi của người trong video. Trước đó thì phát hiện keypoints bằng mô hình hoặc framework (Openpose hoặc MediaPipe).

Optical Flow and CNN
Optical Flow là một khái niệm chỉ chuyển động của các điểm trên bề mặt một đối tượng, khi chiếu lên mặt phẳng 2D thì ta có motion field.

Optical Flow ứng dụng nhiều trong motion tracking. Vì vậy nên được coi là giải pháp trong bài toán này. Paper về ý tưởng này là “A Comprehensive Review on Handcrafted and Learning-Based Action Representation Approaches for Human Activity Recognition” (https://www.researchgate.net/publication/312642887_A_Comprehensive_Review_on_Handcrafted_and_Learning-Based_Action_Representation_Approaches_for_Human_Activity_Recognition).
Ý tưởng là mô hình chia thành 2 luồng: luồng trên đầu vào là một ảnh (frame), đi qua CNN, luồng dưới đầu vào là list các frame liền kề được merge bằng fusion technique, biểu diễn chuyển động của các điểm của người (multi-frame optical flow), đi qua CNN. Kết quả cuối cùng là trung bình cộng của 2 predicted score.
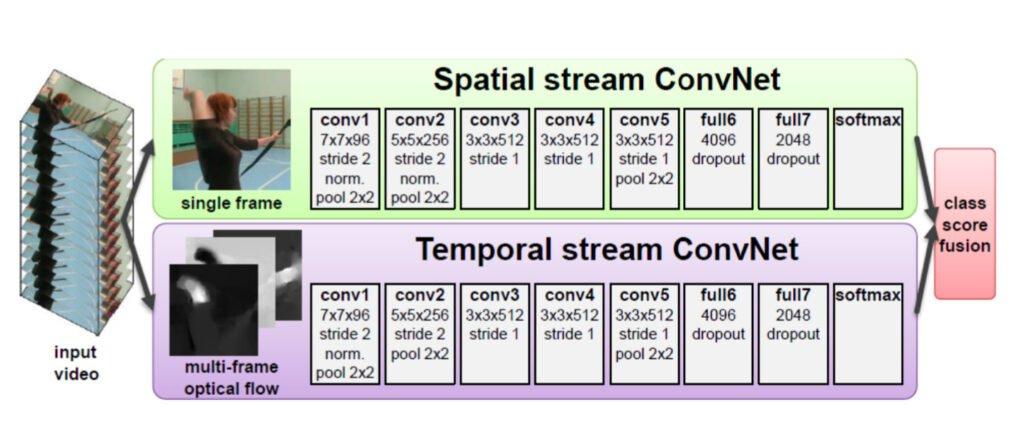
Dựa trên ý tưởng thì ta có thể thấy là vấn đề của giải pháp này phụ thuộc vào thuật toán optical flow, nếu biểu diễn chuyển động của điểm ảnh bị sai thì kết quả toang ngay.
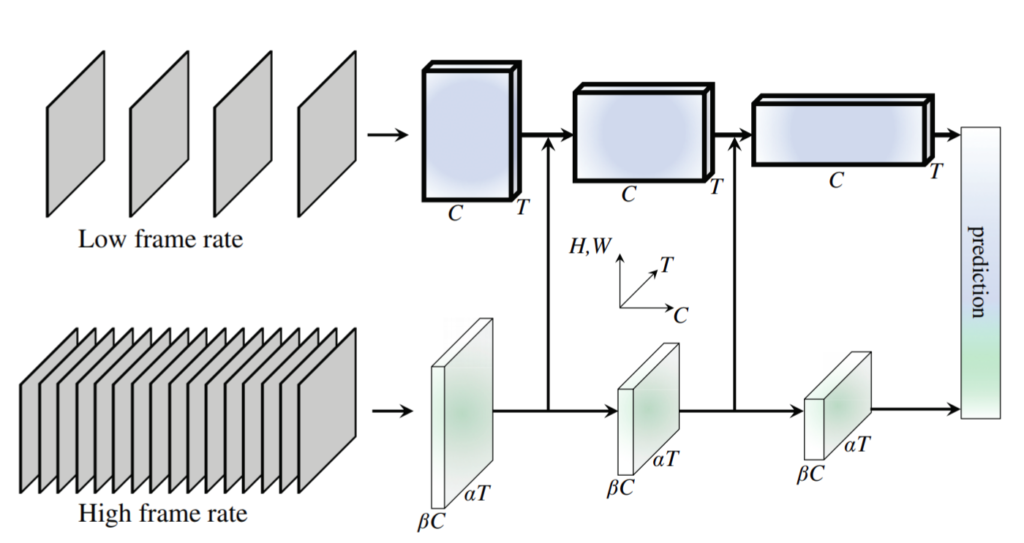
SlowFast Networks
Mình chưa đọc qua nên cũng không có hiểu sâu mạng này cho lắm. Nhìn sơ qua thì mô hình cũng chia làm 2 luồng như cách trên, luồng trên (Slow pathway) đầu vào là low frame rate (tức là cái video cứ giật giật ý, FPS thấp), đi qua các layer, mỗi layer lại có nhiều channel để xử lý chi tiết từng frame. Còn luồng dưới (Fast pathway) đầu vào là high frame rate (FPS cao), các frame liền kề không có quá nhiều thay đổi nên đi qua các layer có ít channel hơn (trong paper họ nhân với hệ số beta = 1/8 channel) => luồng dưới nhẹ hơn luồng trên. Theo trong hình thì ở đây có 3 giai đoạn, thông tin trích xuất ở đường dưới sẽ merge với đường trên ở mỗi giai đoạn.
Để hiểu sâu hơn về ý tưởng mời các bạn đọc thêm paper này “SlowFast Networks for Video Recognition” (https://arxiv.org/pdf/1812.03982.pdf)
3D CNN’s / Slow Fusion
Giống Early Fusion nhưng layer chuyển thành 3D CNN => việc fusion lúc đầu chậm và ngốn tài nguyên cho việc tính toán. Để hiểu rõ mời đọc thêm paper này “3D Convolutional Neural Networks for Human Action Recognition” (https://ieeexplore.ieee.org/document/6165309).

Lời kết
Bài viết này mang đến cho bạn đọc một vài giải pháp trong bài toán nhận diện hành động của con người trong video. Phần code các bạn có thể tham khảo thêm trong link ở mục References. Cám ơn đã đọc hết bài viết này 
References
https://learnopencv.com/introduction-to-video-classification-and-human-activity-recognition/


