1, Tacotron
Ra đời: Tacotron được ra mắt bởi Google năm 2017 qua bài báo TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS
Kiến trúc: Tacotron là một end-to-end Text-To-Speech(TTS) model dựa trên kiến trúc seq2seq và attention. Đầu vào của model là các chuỗi ký tự, đầu ra là các waveform được biến đổi từ Linear Spectrogram bằng giải thuật Griffin-Lim. Về giá trị chi tiết của các hyperparameter thì bạn có thể xem ở TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS
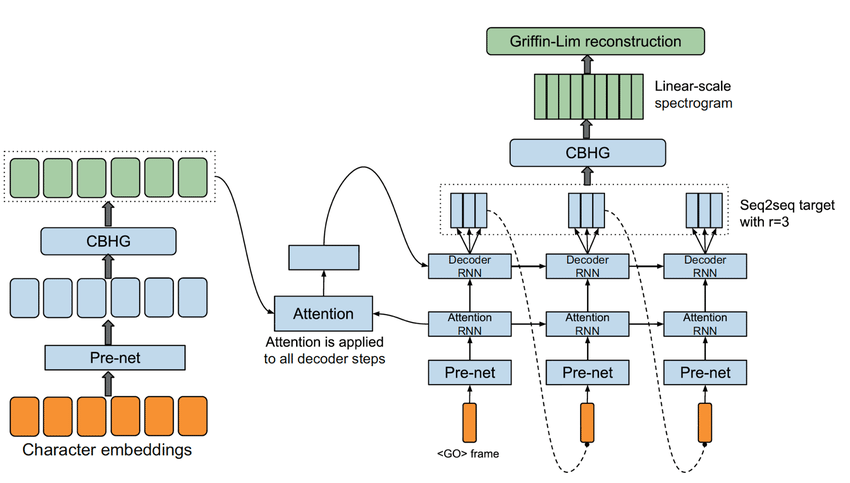
Về tổng thể, kiến trúc Tacotron chia làm 3 phần:
- Encoder
- Attention-based Decoder
- Post-processing net
a) CBHG module
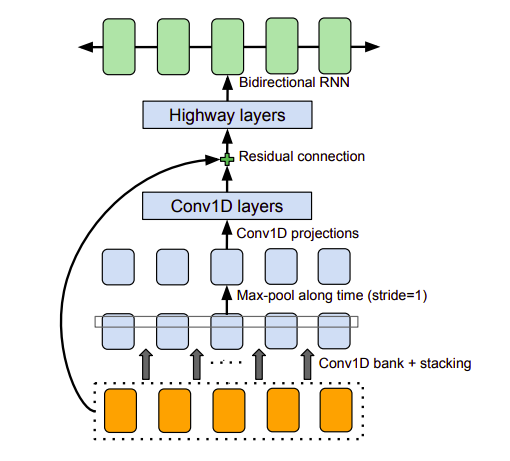
Trước khi phân tích kiến trúc model thì ta nói qua về building block là CBHG. CBHG có nhiệm vụ trích xuất các biểu diễn từ chuỗi, với cấu tạo gồm lớp 1-D convolution bank (gồm k tập hợp các 1-D convolution với độ dài filter từ 1 đến k), highway network và một GRU 2 chiều. Batch normalization được sử dụng cho mọi convolutional layers
b) Encoder
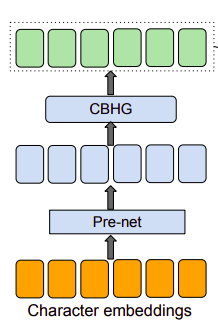
- Mục đích của phần Encoder là trích xuất biểu diễn tuần tự của văn bản. Đầu vào của Encoder là một chuỗi ký tự, với mỗi ký tự được biểu diễn bằng one-hot vector rồi embeded về dạng continous vector. Sau đó, với mỗi embedding, tác giả sử dụng một tập hợp các biến đổi phi tuyến - gọi là pre-net - gồm 1 bottleneck layer và dropout.
- Việc sử dụng pre-net giúp model hội tụ nhanh hơn cũng như tăng tính tổng quát. Theo paper thì các kiến trúc encoder với CBHG vừa giảm overfitting, vừa giảm mispronunciation so với các encoder chỉ sử dụng nhiều lớp RNN
c) Attention-based Decoder
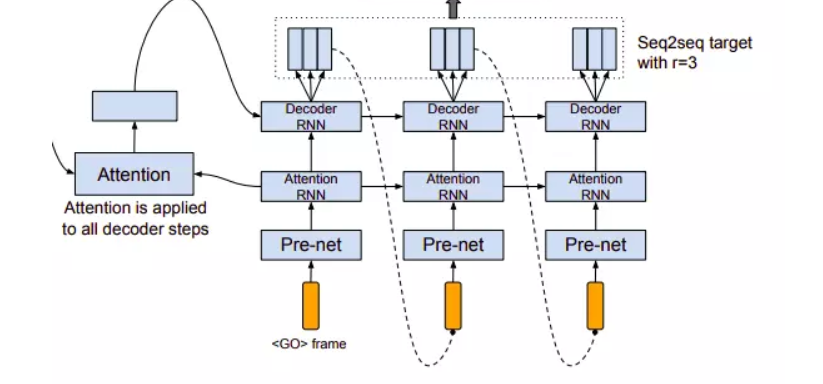
Nhóm tác giả sử dụng content-based tanh attention decoder, nơi mà stateful recurrent layer sinh ra truy vấn attention ở mỗi decoder time step. Truy vấn đó kết hợp với context vector rồi đưa vào decoder RNN gồm các GRU cell với kết nối residual - các kết nối này giúp tăng tốc độ hội tụ của mô hình. Đầu ra của decoder là 80-band mel-scale spectrogram
d) Post-processing net và waveform synthesis
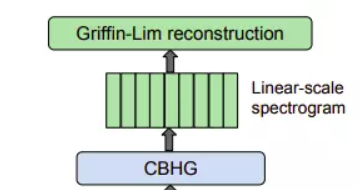
Spectrogram tạo ra từ decoder được chuyển đổi thành waveform thông qua post-processing network, gồm CBHG module với Griffin-Lim synthesizer.
e) Kết quả
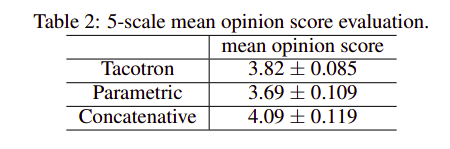
Tacotron đạt MOS 3.82, trở thành mô hình TTS đạt hiệu quả tốt nhất ở thời điểm ra mắt
f) Ưu, nhược điểm
Ưu điểm:
- Đạt hiệu quả rất tốt so với các model thời bấy giờ
- Không cần thực hiện linguistic feature engineering thủ công
- Có thể sinh waveform chất lượng khá tốt
Nhược điểm:
- Chi phí tính toán cao, quá trình train lâu do là mô hình end-to-end và sử dụng nhiều RNN
- Khả năng sinh âm thanh chậm, hay bị mất, lặp từ
- Vocoder Griffin-Lim kém hơn các vocoder sau này
2. Tacotron 2
Ra đời: qua bài báo NATURAL TTS SYNTHESIS BY CONDITIONING WAVENET ON MEL SPECTROGRAM PREDICTIONS, được cải tiến từ kiến trúc Tacotron
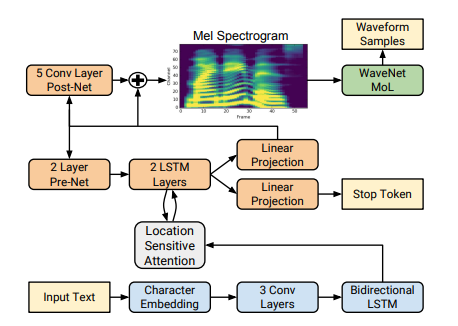
Tacotron2 khác gì Tacotron?
- Encoder sử dụng 3 convolutional layers + LSTM 2 chiều thay vì pre-net + CBHG module
- Sử dụng Local sensitive attention giúp model tiến về phía trước một cách nhất quán thông qua đầu vào (mình cũng thấy hơi khó hiểu)
- Decoder là 1 autoregressive RNN được tạo bởi prenet, 2 lớp LSTM, 5 lớp convolution được gọi là post-net.
- Sử dụng Mel Spectrogram đưa vào Vocoder sinh âm thanh thay vì Linear Spectrogram
- Sử dụng Wavenet làm Vocoder thay vì giải thuật Griffin-Lim => Chất lượng âm thanh cao hơn
Kết quả: Đạt MOS ấn tượng - 4.53, vượt trội so với Tacotron
Ưu điểm:
- Đạt được các ưu điểm như Tacotron, thậm chí nổi bật hơn
- Chi phí và thời gian tính toán được cải thiện đáng kể vo sới Tacotron
Nhược điểm:
- Khả năng sinh âm thanh chậm, hay bị mất, lặp từ như Tacotron
- Chi phí tính toán vẫn cao dù thấp hơn Tacotron





