Trong bất kỳ hệ thống nào thì một bộ giới hạn truy cập cũng là một yêu cầu cần thiết đế đáp ứng các yêu cầu về bảo mật cũng như tính an toàn hệ thống.
Về lý do cho sự có mặt của một bộ giới hạn truy cập với bất kỳ hệ thống nào thì có vài lý do tiêu biểu như sau:
- Ngăn chặn cạn kiệt tài nguyên bởi tấn công DoS(Denial of Service) . Hầu hết API công khai bởi các công ty lớn đều thực thi các kiểu giới hạn truy cập. Ví dụ, Twitter giới hạn số lượng tweet là 300 trong 3 giờ . Google Docs giới hạn 300 người dùng trên 60 giây cho một lần yêu cầu đọc. Một bộ giới hạn truy cập sẽ ngăn chặn các cuộc tấn công DoS, dù vô tình hay cố ý, bằng cách chặn các lệnh gọi vượt ngưỡng.
- Giảm chí phí. Việc giới hạn các yêu cầu vượt ngưỡng đồng nghĩa với ít server hơn và ít cấp phát tài nguyên hơn. Giới hạn truy cập là rất quan trọng với các công ty sử dụng API trả phí bên thứ 3. Ví dụ bạn bị tính phí cơ sở cho mỗi lần gọi cho các API bên ngoài như: kiểm tra tín dụng, thanh toán, truy xuất hồ sơ sức khỏe, ... Hạn chế số lượng yêu cầu là điều cần thiết để giảm chi phí.
- Ngăn chặn server bị sập. Để giảm tải cho server, bộ giới hạn được dùng để lọc các yêu cầu vượt ngưỡng gây ra bởi bot hoặc hành vi phá hoại từ người dùng.
Trong bài viết hôm nay mình sẽ trình bày một vài thuật toán tiêu biểu và hữu ích khi chúng ta thiết kế một bộ giới hạn truy cập:
- Token bucket
- Leaking bucket
- Fixed window counter
- Sliding window log
- Sliding window counter
Token Bucket
Token bucket hiểu nôm na sẽ là một thùng (bucket) đựng các đồng tiền (token). Ý tưởng của thuật toán này như sau: Một bucket là một thùng chứa có dung lượng đã xác định trước. Các token là các đồng tiền được đặt vào theo định kỳ. Khi mà bucket đã đầy thì không có token nào được thêm vào. Như hình bên dưới, dung lượng bucket là 4. Mỗi giây, bộ nạp sẽ đặt 2 token vào. Khi bucket đầy các token tiếp theo sẽ bị tràn ra ngoài.
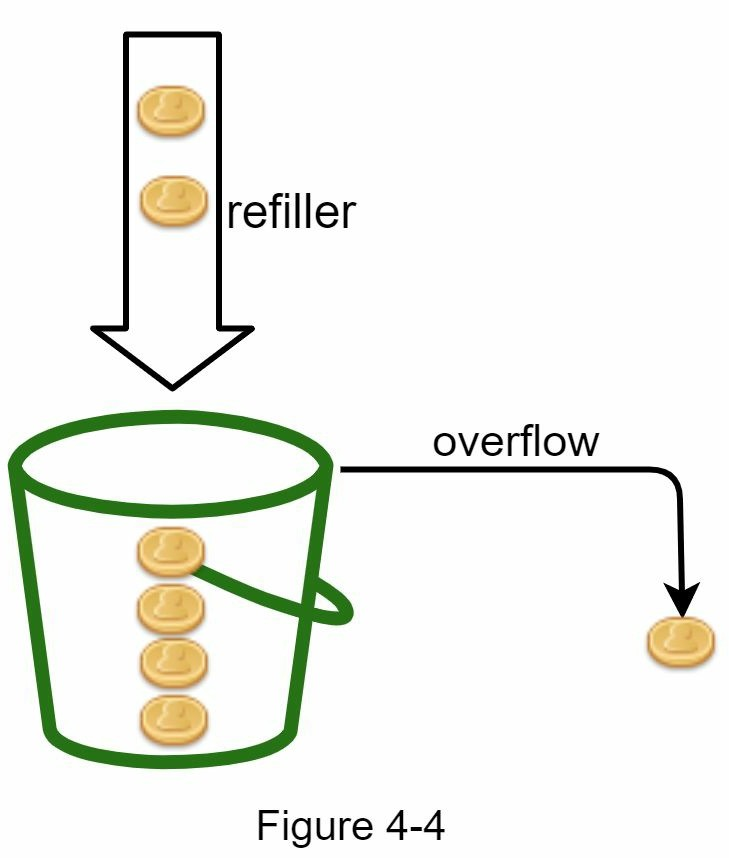
Các yêu cầu đến hệ thống sẽ tương ứng với một token, khi một yêu cầu nào đó được gửi đến hệ thống, ta sẽ thực hiện kiểm tra bucket xem nó có đủ token không. Nếu bucket vẫn còn token, ta sẽ thực hiện xử lý yêu cầu, trong trường hợp bucket không còn token thì yêu cầu sẽ không được xử lý.
Thuật toán này đòi hỏi hai tham số, một là kích cỡ của bucket (số lượng token tối đa trong bucket) cái còn lại là chu kỳ cho cấp phát token (số lượng token được cấp phát trong mỗi giây).
Ưu điểm của thuật toán này là dễ dàng triển khai và lưu trữ hiệu quả, có khả năng cho phép hàng loạt truy cập trong thời gian ngắn, miễn là còn token.
Tuy nhiên nhược điểm của nó là việc thiết lập hai tham số kích cỡ bucket và chu kỳ cấp phát không đơn giản.
Leaking Bucket
Thuật toán này tương tự với token bucket với một khác biệt là sử dụng hàng đợi FIFO, thuật toán có luồng hoạt động tương tự như token bucket song vì nó sử dụng hàng đợi nên các yêu cầu nào đến hàng đợi trước sẽ được xử lý trước, trong trường hợp hàng đợi đầy thì các yêu cầu gửi đến sẽ không được xử lý.
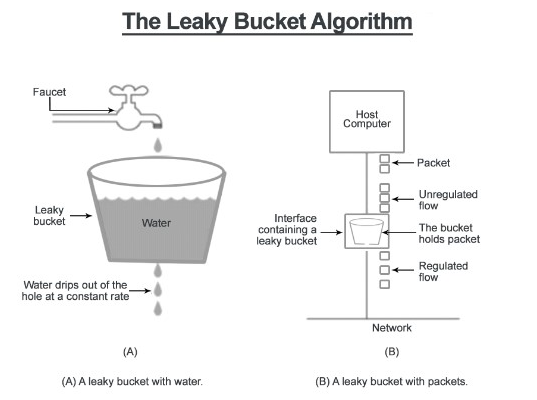
Giống như token bucket nó cũng nhận về hai tham số là kích cỡ hàng đợi và tần suất thoát ra.
Về phần ưu điểm nó tương tự như token bucket là dễ triển khai và lưu trữ hiệu quả, và nó có hạn chế tương tự như token bucket là không dễ để thiết lập hai tham số, đồng thời việc sử dụng hàng đợi sẽ khiến các yêu cầu gần nhất không thể thực hiện.
Fixed window counter
Khác với hai thuật toán trên, thuật toán này chia một khoảng thời gian thành các dạng window (cửa sổ) cố định và nó sẽ gán cho mỗi window một bộ đếm.
Với mỗi yêu cầu thì bộ đếm sẽ tăng lên là 1.
Khi bộ đếm đạt đến ngưỡng (đã thiết lập từ trước) thì các yêu cầu mới sẽ không được xử lý.
Lấy một ví dụ đơn giản. Nếu ta lấy đơn vị thời gian là 1s, hệ thống cho phép tối đa 3 yêu cầu trên 1s. Từ window thứ hai nếu có hơn 3 yêu cầu, các yêu cầu sau đó sẽ bị loại bỏ.

Ưu điểm của thuật toán này là nó có khả năng đặt lại định mức khả dụng với mỗi trường hợp nhất định, đồng thời vẫn đảm bảo khả năng lưu trữ hiệu quả và tính dễ triển khai.
Song nó lại có một hạn chế lớn, ví dụ một hệ thống cho phép tối đa 5 yêu cầu mỗi phút, định mức khả dụng đặt lại gần bằng phút. Và có 5 yêu cầu trong khoảng thời gian từ 2:00:00 đến 2:01:00 và 5 yêu cầu khác trong khoảng 2:01:00 đến 2:02:00. Đối với khoảng thời gian một phút từ 2:00:30 đến 2:01:30, thì lại có 10 yêu cầu. Gấp đôi với số yêu cầu được cho phép. Việc lưu lượng truy cập tăng vọt ở cạnh của window có khả năng gây ra nhiều yêu cầu hơn định mức cho phép
Sliding window log
Thuật toán này được dùng để khắc phục hạn chế của thuật toán fixed window counter. Để khắc phục thuật toán theo dõi các timestamp của yêu cầu và lưu nó vào cache (ở đây có thể dùng Redis hay Memcached), khi có yêu cầu mới nó xoá tất cả timestamp cũ, và thêm các timestamp của yêu cầu mới vào log.
Nếu kích thước của log bằng hoặc nhỏ hơn kích cỡ được cho phép thì nó sẽ chấp nhận yêu cầu trong trường hợp ngược lại thì yêu cầu sẽ bị xoá
Với thuật toán này giới hạn truy cập là chính xác, trong bất kỳ window nào thì các yêu cầu cũng sẽ không thể vượt quá mức cho phép.
Song hạn chế của nó sẽ là tiêu thụ nhiều bộ nhớ hơn vì ngay cả trong trường hợp yêu cầu bị từ chối thì timestamp của nó vẫn sẽ được lưu lại.
Sliding window counter
Thuật toán này là kết hợp của cả hai fixed window counter và sliding window log. Để hiểu triển khai thuật toán ta có ví dụ sau:
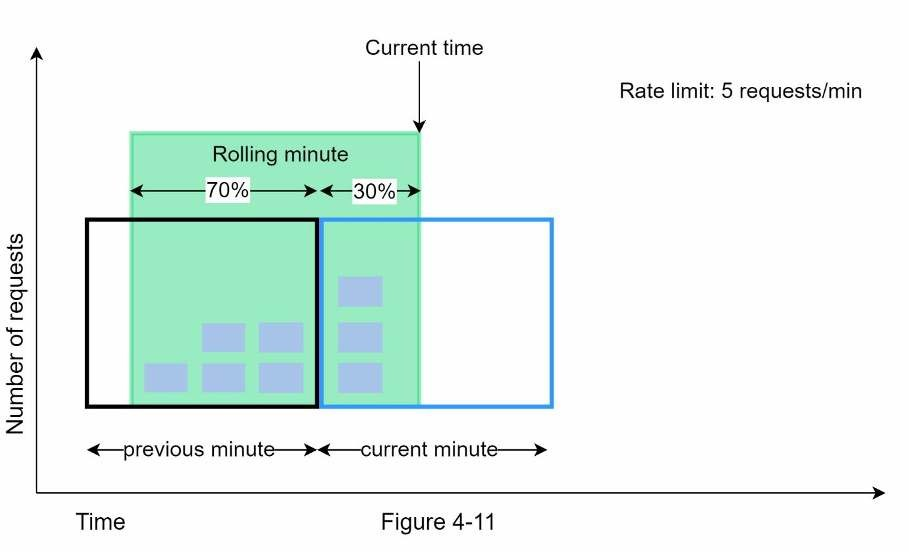
Giả sử bộ giới hạn truy cập cho phép tối đa 7 yêu cầu mỗi phút và có 5 yêu cầu trong phút trước và 3 yêu cầu trong phút hiện tại. Đối với một yêu cầu mới đến vị trí 30% trong phút hiện tại, số lượng yêu cầu trong vùng chồng chéo giữa hai window được tính bằng công thức sau: Số yêu cầu ở cửa sổ hiện tại + số yêu cầu ở cửa số trước * phần trăm chồng chéo giữa hai cửa sổ. Sử dụng công thức trên ta có 3 + 5 * 0.7% = 6.5 yêu cầu. Tuỳ vào trường hợp mà con số có thể được làm tròn lên hoặc xuống. Ở đây ta làm tròn xuống còn 6. Vì bộ giới hạn truy cập cho phép tối đa 7 yêu cầu mỗi phút, nên yêu cầu hiện tại có thể được thực hiện. Tuy nhiên, giới hạn sẽ đạt được khi nhận được thêm một yêu cầu mới.
Ưu điểm của thuật toán này là vẫn đảm bảo tính chính xác khi giới hạn truy cập song nhược điểm của nó là chỉ hoạt động với giá trị gần đúng do các yêu cầu trên từng window có thể phân bố không đồng đều. Song các nghiên cứu thực tế cho thấy sai số này là rất nhỏ và không đáng kể với các hệ thống lớn.
Bài viết đến đây là hết, hy vọng nó sẽ có ích cho những ai đang cần nó :3.
Tham khảo
- System Design Interview - An Insider's Guide


