Trong hệ thống phân tán, lỗi có thể xảy ra ở bất cứ thành phần nào, là lỗi máy chủ hay lỗi mạng đều làm giảm hiệu năng và có thể làm gián đoạn dịch của hệ thống. Một yêu cầu quan trọng khi xây dựng hệ thống phân tán là phải lường trước được các lỗi có thể xảy ra và chuẩn bị phương án xử lý sao cho tối thiểu hóa ảnh hưởng của nó đến hệ thống. Hay nói cách khác, khi có lỗi xảy ra thì hệ thống vẫn vận hành theo cách có thể chấp nhận được, tức là hệ thống phải có khả năng chịu được lỗi. Hôm nay mình sẽ nói về tính chịu lỗi trong HPT và đây cũng là phần cuối trong serise dài về HPT này. Cùng tìm hiểu nhé!
Mục lục
- Giới thiệu tính chịu lỗi
- Khả năng phục hồi tiến trình
- Truyền thông client-server đáng tin cậy
- Truyền thông nhóm đáng tin cậy
- Cam kết phân tán
- Phục hồi
1. Giới thiệu tính chịu lỗi
1.1. Khái niệm
Một hệ thống được coi là có khả năng chịu lỗi nếu đáp ứng được các điều kiện sau:
- Khả năng sẵn sàng phục vụ: thể hiện ở thời gian đáp ứng yêu cầu của mỗi dịch vụ, trong trường hợp lý tưởng nó phải được thực hiện theo thời gian thực.
- Độ tin cậy: liên quan tới tính chính xác của thông tin mà không phụ thuộc vào yếu tố thời gian.
- Độ an toàn: thể hiện ở khả năng bảo đảm an toàn cho dữ liệu ngay cả khi có những sự cố lớn.
- Khả năng bảo trì: thể hiện ở khả năng phục hồi hệ thống sau khi xảy ra lỗi, nó phải được thực hiện một cách đơn giản và trong thời gian nhanh nhất và tổn thất thông tin ở mức thấp nhất.
1.2. Phân loại lỗi
-
Một hệ thống bị coi là lỗi nếu không cung cấp chính xác các dịch vụ như đã thiết kế.
-
Nếu coi hệ thống phân tán là tập hợp máy chủ trao đổi thông tin với nhau và với các máy khách thì lỗi có thể xảy ra ở trên các máy chủ hoặc trên hạ tầng mạng.
-
Việc vận hành sai cũng có thể gây ra lỗi, nếu một máy chủ hoạt động phụ thuộc vào máy chủ khác nó cũng sẽ bị ảnh hưởng nếu lỗi xảy ra trên máy chủ khác.
-
Về tần suất, lỗi chia thành 3 loại:
- Lỗi nhất thời: lỗi xảy ra một lần sau đó không xuất hiện lại.
- Lỗi lặp: lỗi xuất hiện nhiều lần, có thể theo chu kỳ hoặc không. Lỗi này thường gây ra các hậu quả nghiêm trọng vì chúng rất khó xác định được.
- Lỗi lâu dài: lỗi vẫn tồn tại ngay cả khi thành phần gây lỗi đó đã được sửa chữa.
-
Về mức độ ảnh hưởng, lỗi chia thành 5 loại:
- Server bị lỗi nghiêm trọng : Server có thể bị treo và dừng mọi hoạt động cung cấp dịch vụ, cách duy nhất để giải quyết vấn đề này là khởi động lại server.
- Server xử lý lỗi: Server không nhận được yêu cầu từ client hoặc nhận được yêu cầu nhưng không thể trả lời hoặc không thể trả về kết quả xử lý cho client. Trong trường hợp này cần phải kiểm tra kết nối giữa client và server.
- Lỗi thời gian: Server không đáp ứng được thời gian xử lý yêu cầu của client.
- Lỗi kết quả xử lý: Thông tin trả về của server không chính xác.
- Lỗi không xác định: Server trả về các giá trị không mong muốn và những giá trị đó chưa từng xảy ra. Việc xác định nguyên nhân và biện pháp xử lý các lỗi này rất khó.
2. Khả năng phục hồi tiến trình
2.1. Che giấu lỗi bằng phương pháp dư thừa
- Dư thừa thông tin: bổ sung thêm các bit kiểm tra chẵn lẻ, mã Haming, CRC… dư thừa để phát hiện lỗi và phục hồi lỗi.
- Dư thừa thời gian: khi một hoạt động đã được thực hiện, nếu dư thừa thời gian nó có thể được thực hiện lại.
- Kĩ thuật này phù hợp khi lỗi là nhất thời và lỗi chập chờn.
- Có thể sửa lỗi bằng cách thực hiện lại các giao tác bị lỗi.
- Tuy nhiên phải chú ý tính đúng đắn đối với các thao tác thực hiện theo thời gian thực.
- Dư thừa vật lý: thay vì sử dụng một thiết bị thì bổ sung thêm tài nguyên vật lý để dự phòng.
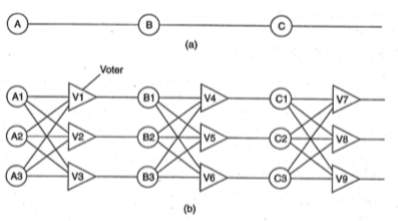
- Vi dụ: Hệ thống dư thừa theo kiểu chuyển mạch
- Hệ thống ban đầu gồm 3 thành phần chính A, B, C.
- Để đảm bảo khả năng chịu lỗi, ta sẽ thêm các thành phần Ai, Bi, Ci tương ứng với A, B, C và duy trì ở trạng thái dự phòng.
- Khi có lỗi xảy ra, hệ thống sẽ tự động chuyển đến một trong các thành phần dư thừa tương ứng.
- Sau khi khắc phục xong lỗi, hệ thống sẽ chuyển về xử lý trên các thành phần chính của hệ thống.
2.2. Tiến trình bền bỉ
Có thể xây dựng hệ thống chịu lỗi bằng phương pháp dư thừa vật lý. Tuy nhiên phương pháp này khá tốn kém, cần một số phương pháp mềm khác để giải quyết vấn đề lỗi trong các hệ thống phân tán.
2.2.1. Lựa chọn mô hình cài đặt
- Giải pháp chính trong tính chịu lỗi là tổ chức một số tiến trình giống nhau thành các nhóm xử lý.
- Khi có thông điệp được gửi tới, tất cả các thành viên trong nhóm đều nhận được thông điệp đó.
- Mỗi nhóm có thể được tổ chức theo mô hình ngang hàng hoặc mô hình phân cấp, một tiến trình có thể là thành viên của một số nhóm khác nhau.
Vấn đề nảy sinh đối với thiết kế này là việc quản lý và phối hợp hoạt động giữa các tiến trình.
=> Giải pháp: tổ chức nhóm tiến trình trong các hệ thống phân tán. Việc tổ chức này hoàn toàn phụ thuộc vào các thuật toán xử lý bên trong mỗi tiến trình.
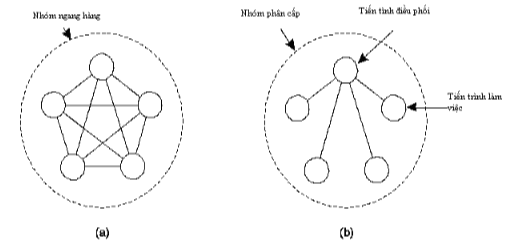
- Với mô hình ngang hàng (a): tất cả các thành viên đều nhận được yêu cầu gửi đến nhưng chỉ có một thành viên được phép xử lý => các thành viên trong nhóm phải thực hiện quá trình bầu chọn.
- Với mô hình phân cấp (b): thành viên điều phối sẽ quyết định tiến trình nào được phép thực hiệu yêu cầu. Tuy nhiên mô hình này lại quay trở lại mô hình xử lý tập trung nhưng đảm bảo tính mềm dẻo hơn.
2.2.2. Che giấu lỗi và sao lưu
Che giấu lỗi trong hệ thống phân tán tập trung trong trường hợp có tiến trình bị lỗi. Tuy nhiên cần xem xét các trường hợp lỗi truyền tin trước.
Một trong các phương pháp che giấu lỗi đó là sử dụng nhóm tiến trình.
- Nhóm các tiến trình giống nhau sẽ che giấu một tiến trình nào đó bị lỗi.
- Sao lưu một tiến trình sau đó gộp chúng thành một nhóm.
- Có hai phương pháp sao chép:
- Giao thức dựa trên thành phần chính (primary-based protocol):
- Các tiến trình trong nhóm tổ chức theo mô hình phân cấp.
- Một tiến trình đóng vai trò tiến trình chính có nhiệm vụ điều phối tất cả các thao tác ghi.
- Nếu tiến trình chính của nhóm dừng hoạt động thì các tiến trình sao lưu sẽ thực hiện giải thuật bầu chọn để lựa chọn tiến trình chính mới
- Giao thức dựa trên ghi sao lưu (replicated-write protocol):
- Các tiến trình trong nhóm tổ chức theo mô hình nhóm ngang hàng.
- Vấn đề đặt ra là cần sao lưu với số lượng là bao nhiêu.
- Giao thức dựa trên thành phần chính (primary-based protocol):
2.2.3. Đồng thuận trong các hệ thống lỗi
- Tổ chức các tiến trình sao lưu thành nhóm làm tăng khả năng chịu lỗi.
- Nếu client có thể dựa trên quyết định của nó thông qua cơ chế bầu chọn thì có thể chấp nhận kết quả sai lệch của k trong số 2k+1 tiến trình.
- Vấn đề trở nên phức tạp nếu các tiến trình trong nhóm muốn đạt được sự đồng thuận trong một số trường hợp như bầu chọn thành viên điều phối, ra quyết định khẳng định trong các giao tác phân tán, phân chia công việc cho các tiến trình thực thi, thực hiện đồng bộ…
- Nếu các tiến trình và truyền thông đều ở trạng thái hoạt động tốt sẽ không có vấn đề gì xảy ra nhưng ngược lại sẽ xảy ra vấn đề đạt được sự đồng thuận giữa các tiến trình.
- Mục đích của thuật toán đồng thuận phân tán: để tất cả các tiến trình không lỗi đạt được sự đồng thuận về một vấn đề nào đó và đạt được sự đồng thuận sau một số bước hữu hạn.
- Vấn đề trở nên phức tạp hơn khi thực tế các giả định khác nhau về hệ thống nền tảng đòi hỏi các giải pháp khác nhau:
- Hệ thống đồng bộ và không đồng bộ: một hệ thống được coi là đồng bộ khi và chỉ khi các tiến trình vận hành trong chế độ theo sát nhau. Hằng số s >= 1, nếu bất kỳ tiến trình nào thực hiện s+1 bước thì tiến trình khác cũng phải thực hiện ít nhất một bước. Ngược lại sẽ là không đồng bộ.
- Trễ truyền thông bị giới hạn hay không giới hạn: độ trễ bị giới hạn khi và chỉ khi bất kỳ một thông điệp nào cũng sẽ được phân phát trong một khoảng thời gian nhất định.
- Phân phát thông điệp theo thứ tự hay không theo thứ tự: phân phát thông điệp theo thứ tự nghĩa là bên nhận phải nhận được các thông điệp đúng theo thứ tự bên gửi đã phát đi. Thậm chí còn phải tính đến sự nhất quán thứ tự các thông điệp trên mỗi tiến trình của hệ thống phân tán.
- Truyền thông điệp theo phương pháp điểm – điểm hay theo nhóm.
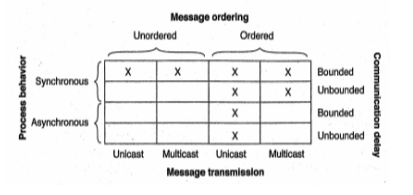
- Hình trên là các trường hợp có thể đạt được sự đồng thuận và được đánh dấu X. Những trường hợp khác đều không có giải pháp thực hiện.
- Trong thực tế hầu hết các tiến trình của hệ thống phân tán đều vận hành theo phương thức không đồng bộ, truyền thông điểm điểm và có ràng buộc thời gian khi truyền thông điệp => từ hình trên cho thấy hệ thống cần sử dụng phân phát thông điệp theo thứ tự và tin cậy như giao thức TCP đã cung cấp.
=> Để giải quyết vấn đề trên bài toán đồng thuận phức tạp (Byzantine) đã ra đời.
Bài toán Byzantine
Bài toán đề cập đến nhiều cuộc chiến mà một số đội quân cần phải đạt được sự đồng thuận, ví dụ về quân số trong khi phải đối mặt với những thông tin sai lệch.
- Coi các tiến trình vận hành theo phương thức đồng bộ, thông điệp truyền theo phương pháp điểm-điểm, có thứ tự và giới hạn thời gian truyền thông.
- Giả sử hệ thống gồm N tiến trình, mỗi tiến trình i cung cấp giá trị Vi cho các tiến trình khác.
- Mục tiêu cần đạt trong đồng thuận lỗi sẽ được thực hiện bằng cách cho phép mỗi tiến trình xây dựng vector V gồm N phần tử với V[i]=Vi nếu tiến trình i không lỗi và V[i] không xác định nếu tiến trình i bị lỗi.
- Quá trình tiến tới sự đồng thuận được thực hiện theo 4 bước sau:
- B1: Mỗi tiến trình i không lỗi gửi giá trị Vi cho các tiến trình khác sử dụng phương pháp truyền thông điểm-điểm tin cậy, tiến trình lỗi gửi giá trị bất kỳ.
- B2: Kết quả nhận được từ B1 sẽ tập hợp lại thành vector V.
- B3: Mỗi tiến trình gửi vector V của B2 cho các tiến trình khác.
- B4: Mỗi tiến trình kiểm tra phần tử thứ i trong các Vector nhận được ở B3.
- Nếu kết quả kiểm tra chiếm đa số thì đặt giá trị vào Vector kết quả đồng thuận.
- Nếu không thì đặt giá trị không xác định UNKNOWN.

Ví dụ, hệ thống gồm bốn thành viên như hình trên:
- Hình (a):
- Các tiến trình 1, 2, 4 đều gửi giá trị tương ứng 1, 2 và 4 cho các tiến trình khác.
- Tiến trình 3 bị lỗi nên gửi các giá trị bất kỳ x, y và z cho các tiến trình 1, 2 và 4.
- Các thành viên khác trong hệ thống cần phải đảm bảo sự đồng thuận về việc tiến trình 3 có thực sự bị lỗi hay không.
- Hình (b): Kết quả thực hiện ở B2, mỗi tiến trình sẽ lưu giữ giá trị vector lần lượt là (1,2,x,4), (1,2,y,4), (1,2,3,4), (1,2,z,4).
- Hình (c): Kết quả của các tiến trình 1, 2 và 4 sau khi thực hiện B3.
- Các tiến trình 1, 2 và 4 gửi giá trị vector đã nhận được ở B2 cho các tiến trình khác, trong khi tiến trình 3 tiếp tục gửi những giá trị không xác định.
- Ở B4, mỗi tiến trình sẽ tự tổng hợp và đưa ra kết quả cuối cùng cho mỗi phần tử thứ i của các vector nhận được ở B3.
- Nếu giá trị nào chiếm đa số thì sẽ đánh dấu giá trị đó trong phần tử tương ứng, ngược lại sẽ điền giá trị không xác định.
- Giá trị cuối cùng trong các tiến trình 1, 2 và 4 đều có giá trị là (1,2,Unknow,4) => các tiến trình 1, 2 và 4 có thể đảm bảo chắc chắn các tiến trình 1, 2, 4 không bị lỗi nhưng không thể đảm bảo tiến trình 3 có bị lỗi hay không.
- Kết quả của ví dụ trên: sau khi hoàn B3 không có bất kỳ phần tử nào chiếm đa số. Do đó các tiến trình không lỗi 1 và 2 đều không đạt được sự đồng thuận.
 => Lamport đã chứng minh rằng, một hệ thống có k tiến trình lỗi thì phải có 2k+1 tiến trình không lỗi, như vậy tổng số tiến trình phải có trên 2/3 tiến trình không lỗi.
=> Lamport đã chứng minh rằng, một hệ thống có k tiến trình lỗi thì phải có 2k+1 tiến trình không lỗi, như vậy tổng số tiến trình phải có trên 2/3 tiến trình không lỗi.
Để tìm hiểu thêm về bài toán Byzantine mọi người có thể tham khảo ở bài này Bài toán các vị tướng Byzantine và ứng dụng trong Blockchain
2.2.4. Phát hiện lỗi
- Để đảm bảo khả năng chịu lỗi trong các hệ thống phân tán, các tiến trình trong nhóm phải có khả năng phát hiện kịp thời những tiến trình đang bị lỗi hoặc có khả năng gây ra lỗi. Từ đó thông báo đến các thành phần khác có liên quan hoặc thông báo cho người quản trị hệ thống.
- Việc phát hiện lỗi có thể dựa trên các thông tin trạng thái, ngưỡng tới hạn hoặc các tiến trình sử dụng kỹ thuật trí tuệ nhân tạo
- Để phát hiện lỗi của các tiến trình, cần sử dụng hai cơ chế đó là chủ động (thường được dùng hơn) hoặc thụ động.
- Cơ chế chủ động: các tiến trình trong nhóm gửi cho nhau thông điệp “IS ALIVE” và tất nhiên sẽ chờ đợi phản hồi từ các tiến trình khác.
- Cơ chế thụ động: mỗi tiến trình sẽ chờ nhận thông điệp từ các tiến tình khác.
3. Truyền thông client-server đáng tin cậy
- Lỗi truyền thông xảy ra có thể do mất kênh truyền, thất lạc thông tin, quá thời gian, lặp thông điệp…,
- Trong thực tế các kênh truyền thông tin cậy được xây dựng tập trung vào việc che giấu lỗi mất kênh truyền và thất lạc thông tin.
- Để khắc phục lỗi truyền thông, người ta thường sử dụng phương pháp truyền thông tin điểm-điểm hoặc truyền thông theo nhóm hoặc truyền thông tin cậy điểm-điểm dựa trên các giao thức truyền tin cậy (ví dụ sử dụng giao thức TCP).
3.1. Truyền thông điểm – điểm
- Trong hệ phân tán, truyền thông điểm - điểm tin cậy được thiết lập bằng cách sử dụng các giao thức truyền thông tầng vận tải tin cậy, ví dụ giao thức TCP.
- Giao thức TCP che giấu được lỗi bỏ sót bằng cơ chế số tuần tự của đoạn tin và thực hiện truyền lại. Đây là những lỗi hoàn toàn trong suốt đối với máy khách.
- Tuy nhiên, giao thức này lại không khắc phục được lỗi sụp đổ - lỗi xuất hiện khi liên kết TCP đột ngột bị ngắt và các thông điệp không thể tiếp tục gửi qua kênh truyền. Thông thường máy khách sẽ nhận được thông báo lỗi kênh truyền.
- Khi hệ thống gặp lỗi sụp đổ thì liên kết TCP sẽ bị hủy bỏ, lúc này hệ thống tự động tạo một liên kết mới bằng cách gửi yêu cầu thiết lập lại liên kết.
3.2. Các trường hợp lỗi khi gọi thủ tục từ xa (RPC)
- Client không thể xác định được server:
- Nguyên nhân: có thể do client và server dùng các phiên bản khác nhau hoặc do server bị lỗi.
- Cách khắc phục: sử dụng tính năng phát hiện lỗi trong ngôn ngữ lập trình ứng dụng. Tuy nhiên không phải ngôn ngữ nào cũng hỗ trợ phát hiện lỗi, nếu tự viết một ngoại lệ hay điều khiển tín hiệu thì sẽ phá hủy tính trong suốt.
- Mất thông điệp yêu cầu từ client gửi đến server:
- Đây là lỗi dễ xử lý nhất.
- Hệ điều hành hay Stub của client kích hoạt một bộ đếm thời gian khi gửi đi yêu cầu. n
- Nếu bộ đếm thời gian trở về giá trị 0 mà vẫn không nhận được thông điệp phản hồi từ server thì nó sẽ gửi lại yêu cầu đó.
- Nếu client nhận thấy có quá nhiều yêu cầu phải gửi lại nó sẽ xác nhận rằng server không hoạt động => quay lại thành kiểu lỗi "không xác định được server".
- Server bị lỗi: sau khi nhận được yêu cầu từ client, server thực hiện yêu cầu và trả kết quả thực hiện cho client. Khi đó có thể xảy ra 3 trường hợp sau:
- Server đã nhận được yêu cầu nhưng chưa thực hiện thì gặp lỗi.
- Server đang thực hiện yêu cầu thì gặp lỗi.
- Server thực hiện xong yêu cầu nhưng chưa gửi kết quả về cho máy khách thì gặp lỗi.
Khi gặp lỗi như trên, đối với server sẽ thực hiện theo 3 cách sau:
- C1: Đợi đến khi nào server hoạt động trở lại, nó sẽ cố thực hiện yêu cầu đã nhận được trước khi lỗi đó => RPC thực hiện ít nhất một lần.
- C2: server sau khi được khôi phục nó sẽ không thực hiện yêu cầu nhận được trước khi bị lỗi mà sẽ gửi lại thông báo lỗi cho client => RPC thực hiện nhiều nhất một lần.
- C3: không thực hiện gì. Nếu server bị lỗi thì client không hề hay biết => RPC có thể được thực hiện nhiều lần cũng có thể không thực hiện lần nào.
Đối với client có thể thực hiện theo 4 cách sau:
- C1: Client không thực hiện gửi lại các yêu cầu do đó sẽ không biết khi nào yêu cầu đó mới thực hiện được hoặc có thể không bao giờ được thực hiện.
- C2: Client liên tục gửi lại yêu cầu => có thể dẫn tới trường hợp một yêu cầu được thực hiện nhiều lần.
- C3: Client chỉ gửi lại yêu cầu nào đó khi không nhận được thông điệp xác nhận phản hồi từ server thông báo đã nhận thành công. Trường hợp này client dùng bộ đếm thời gian, sau một khoảng thời gian xác định trước mà không nhận được xác nhận thì sẽ gửi lại yêu cầu đó.
- C4: Client gửi lại yêu cầu nếu nhận được thông báo lỗi từ server.
Như vậy với 3 cách trên server và 4 cách của client sẽ cho 12 khả năng xảy ra. Trong đó không có một cách riêng lẻ client và server cho kết quả tốt => cần phối hợp các cách giữa client và server.
Giả sử:
- M là sự kiện gửi thông điệp trả về cho client.
- P là sự kiện thực thi công việc trong gọi thủ tục từ xa.
- C là sự kiện lỗi xảy ra trên server.
- Khi nhận được yêu cầu từ client, phía server sẽ xảy ra 2 trường hợp:
- P -> M: server thực hiện y/c trước sau đó mới thông báo cho client.
- M -> P: server thông báo trước kết quả sau đó mới thực thiện y/c.
- Với 3 sự kiện trên sẽ có 6 trường hợp xảy ra như sau:
- MPC, PMC: Lỗi xảy ra sau khi đã hoàn thành gửi thông điệp cho client và đã hoàn thành công việc xử lý.
- MC(P): Lỗi xảy ra sau khi đã hoàn thành gửi thông điệp cho client nhưng chưa hoàn thành công việc xử lý.
- PC(M): Lỗi xảy ra khi đã hoàn thành công việc xử lý nhưng chưa kịp gửi thông điệp cho client.
- C(MP), C(PM): Lỗi xảy ra khi chưa thực hiện xử lý và cũng chưa gửi thông điệp cho client.
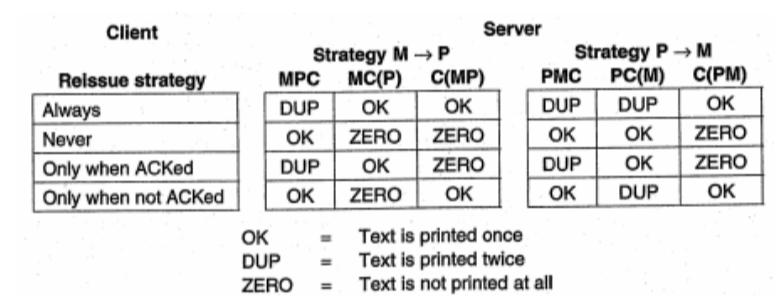
- Mất thông điệp phản hồi:
- Client đánh số tuần tự cho các yêu cầu, server sẽ nhận ra được đâu là yêu cầu đã được gửi lại nhờ các số tuần tự này. Do đó server sẽ không thực hiện lặp lại các yêu cầu.
- Tuy nhiên server vẫn phải gửi trả về thông điệp thông báo yêu cầu nào bị thất lạc hoặc có thể sử dụng một bit ở phần thông tin điều khiển của yêu cầu để phân biệt yêu cầu nào là yêu cầu đã được gửi lại.
- Client bị lỗi ngay sau khi gửi yêu cầu tới server:
- Client gửi yêu cầu tới server và bị lỗi trước khi nhận được trả lời từ server gửi về.
- Server thực hiện nhiệm vụ nhưng không có đích nào đợi để nhận kết quả => gây lãng phí thời gian xử lý của CPU. Ttrường hợp này có thể giải quyết bằng 4 cách sau:
- C1: Trước khi gửi đi yêu cầu nào đó, client stub sẽ tạo ra một bản ghi xác định công việc cần thực hiện này và lưu nhật ký. Sau khi phục hồi client sẽ lấy lại bản ghi đó và và việc thực hiện công việc đã bị tạm dừng => nhược điểm về chi phí trong việc lưu lại mỗi bản ghi cho mỗi lời gọi thủ tục từ xa.
- C2: Chia thời gian hoạt động liên tục của máy trạm thành các số liên tục gọi là các thời kì. Mỗi khi client được phục hồi thì tham số đó được tăng thêm một đơn vị, máy trạm sẽ gửi thông báo đến tất cả các client khác thông báo số thời kì mới của mình.
- C3: Khi nhận được thông điệp thông báo thời kì mới, mỗi server sẽ kiểm tra xem mình có đang thực hiện một tính toán từ xa nào hay không. Nếu có sẽ xác định xem client nào đã gửi yêu cầu này, nếu không xác định được thì quá trình tính toán này sẽ bị hủy bỏ.
- C4: quy định mỗi RPC chỉ có một khoảng thời gian xác định T để thực hiện. Sau khi gặp lỗi, client sẽ đợi thêm một khoảng thời gian T trước khi thực hiện lại => vấn đề đó là phải lựa chọn giá trị khoảng thời gian T như thế nào cho hợp lý.
Bài cũng đã dài, mình xin khép lại part 1 của phần Tính chịu lỗi trong HPT tại đây. Ở bài tiếp theo mình sẽ nói tiếp phần còn lại là mục 4, 5 và 6 của bài.
Thanks for reading
Tài liệu tham khảo: Bài giảng Hệ phân tán - ĐHBKHN