Chào mọi người, để tiếp tục với chuỗi các bài viết về self-supervised leaning, bài viết lần này mình sẽ tiến hành triển khai áp dụng self-supervised để cải thiện hiệu suất của bài toán phân lớp. Cụ thể hơn mình sẽ tiến hành implement lại bài báo SimCLR (a framework for contrastive learning of visual representations) cho bộ cifar10 qua đó đánh giá tính hiệu quả của phương pháp. Bài viết sẽ tập chung giải thích các thuật toán của bài báo bằng lập trình, nên bạn nào chưa nắm rõ thì có thể xem lại các bài viết trước của mình nhé. Được rồi đi thôi, chúng ta vào việc nào.
1 Tổng quan
Đầu tiên chắc chúng ta điểm lại một số lý thuyết về self-supervised contrastive learning
1.1 Self-supervised và contrastive learning
Tư tưởng của self-supervised Hiểu đơn giản thì self-supervised learning định nghĩa một pretext task và huấn luyện task đấy trở thành một mô hình pretrained trên tập dữ liệu không nhãn. Ở đây chúng ta chỉ sử dụng tham số của một số phần trong mô hình pretrained (thường sẽ là backbone) để finetune cho mô hình của tác vụ chính (Downstream task).

Constrastive learning Mục tiêu của constrastive learning là học được một không gian nhúng (embedded space) trong đó sẽ tối ưu khoảng cách giữa các cặp mẫu. Ví dụ các cặp mẫu giống nhau sẽ gần nhau và các cặp mẫu khác nhau sẽ xa nhau trong cùng một không gian vector. Các sample đi qua mạng tạo thành representation sau đó đi qua mạng để tạo thành các vector đặc trưng. Ham loss được xây dựng dựa trên các vector đặc trưng để tối ưu hóa
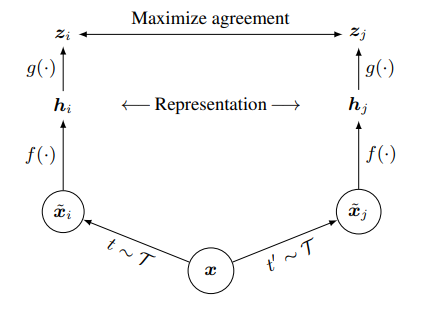
1.2 Pipeline
Trong bài viết lần này mình sẽ thử nghiệm cải thiện performance trên tập dữ liệu cifar10 (một bộ dữ liệu rất nổi tiếng trên các bài toán phân lớp) bằng cách ứng dụng tư tưởng của self-supervised leanring . Thực ra việc triển khai self-supervised trên một số tập public dataset (như imageNet, cifar) đã có khá nhiều repo, tuy nhiên mình sẽ implemetnt theo hướng cơ bản nhất và làm rõ hơn ở một số điểm cần lưu ý.
Để so sánh tính hiệu quả của self-supervised leanring mình sẽ tiến hành huấn luyện và đánh giá 2 mô hình.
- Mô hình cho bài toán supervised learning: Mô hình bài toán phân lớp mình sử backbone resnet18
- Mô hình ứng dụng self-supervised leaning: Đầu tiên mình sử dụng contrastive leanring để huấn luyện mô hình self-supervised với backbone resnet 18. Sau đó sử dụng weight của backbone resnet 18 để finetune cho mô hình của bài toán phân lớp.
2 Phương pháp tiếp cận
Contrastive loss
Tổng quan về hàm loss
 Trong 2N sample (mỗi N sample ứng với một phép tăng cường hình ảnh). Chúng ta sẽ phải chọn ra các cặp mẫu positive và cặp mẫu negative và tính ma trận cosine similarity giữa chúng. Hàm loss sẽ tối ưu các vector đặc trưng của các cặp mẫu, sao cho cặp mẫu positive sẽ gần nhau và các cặp mẫu negative sẽ xa nhau hơn trong cùng một không gian biểu diễn.
Trong 2N sample (mỗi N sample ứng với một phép tăng cường hình ảnh). Chúng ta sẽ phải chọn ra các cặp mẫu positive và cặp mẫu negative và tính ma trận cosine similarity giữa chúng. Hàm loss sẽ tối ưu các vector đặc trưng của các cặp mẫu, sao cho cặp mẫu positive sẽ gần nhau và các cặp mẫu negative sẽ xa nhau hơn trong cùng một không gian biểu diễn.
Data augmentation
Dữ liệu được đi qua 2 phép biến đổi và tướng ứng là các phép augmentation khác nhau, trong source code các bạn sẽ thấy ảnh đều đi qua hàm transform, tuy nhiên trong hàm transform sử dụng các hàm random khác nhau nên mỗi lần các sample ảnh đi qua sẽ tạo ra các view khác nhau.
class CIFAR10Pair(CIFAR10):
"""Generate mini-batche pairs on CIFAR10 training set."""
def __getitem__(self, idx):
img, target = self.data[idx], self.targets[idx]
img = Image.fromarray(img) # .convert('RGB')
imgs = [self.transform(img), self.transform(img)]
return torch.stack(imgs), target # stack a positive pair
Mình định nghĩa 2 phép biến đổi và là các phướng pháp agumentation dựa trên kích thước ảnh, màu sắc, horizontal ... Các phép biến đổi này được để random để tạo ra các phép biến đổi khác nhau cho cùng một hình ảnh
# Trainforms images
train_transforms = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomApply([transforms.ColorJitter(0.4, 0.4, 0.4, 0.1)], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
Để trực quan hơn, mình tiến hành visualize một số ảnh trong cùng một class của bộ dữ liệu cifar10. Các ảnh phía trên và phía dưới tương ứng đại diện cho phép augmentation và , của cùng một hình ảnh.
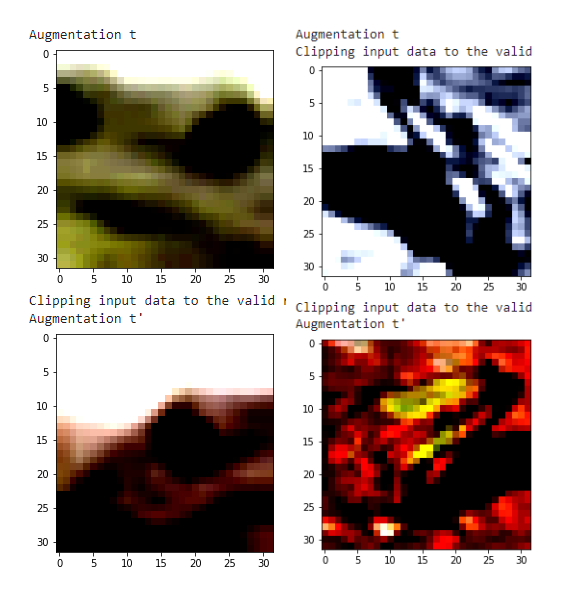
Các phép augmentation được sử dụng trong quá trình huấn luyện mô hình self-supervised learning là cực kỳ quan trọng, vì các representation được lấy trực tiếp từ các ảnh sau khi đi quan phép biến đổi (phép augment). Trong bài báo SimCLR họ có thí nghiệm và báo cáo một bảng kết quả về tác động của các phép augmentation tới hiệu suất của mô hình.

Thường thì từng bài toán cụ thể, chúng ta phải có một chiến lược lược chọn các phương pháp augmentation cho phù hợp, như mình đã đề cập phía trên việc lựa chọn chiến lực augmentation có thể tác động khá lớn tới kết quả cuối cùng mà chúng ta muốn hướng tới. Vậy nên đây cũng là một trong những điểm hạn chế của các mô hình self-supervised hiện tại đang vướng mắc.
3 Xây dựng mô hình
Sau khi có dữ liệu, hàm loss thì mình tiến hành tìm kiếm một backbone để thử nghiệm. Có khá nhiều backbone đã được triển khai trên tập cifar10 nên việc tìm kiếm 1 backbone để thử nghiệm thì mình không quá phức tạp, ở đây mình dùng resnet18 cho quen thuộc, các bạn có thể thử nghiệm thêm với nhiều backbone khác nhau nhé.
3.1 Supervised learning
Mô hình huấn luyện cho bài toán phân lớp mình sử dụng backbone resnet 18 và một lớp FC (fully connected)
import torch.nn as nn
from torchvision.models import resnet18, resnet34
class SL(nn.Module):
def __init__(self, projection_dim=128):
super().__init__()
self.enc = resnet18(pretrained=False) # load model from torchvision.models without pretrained weights.
self.feature_dim = self.enc.fc.in_features
# Customize for CIFAR10. Replace conv 7x7 with conv 3x3, and remove first max pooling.
# See Section B.9 of SimCLR paper.
self.enc.conv1 = nn.Conv2d(3, 64, 3, 1, 1, bias=False)
self.enc.maxpool = nn.Identity()
self.enc.fc = nn.Identity() # remove final fully connected layer.
# FC
self.linear = nn.Linear(self.feature_dim, 10) # 10 number of class
def forward(self, x):
# Representaion
feature = self.enc(x)
# FC
output = self.linear(feature)
return output
3.2 Self-supervised learning
Mô hình huấn luyện pretext task khá đơn giản, mình chỉ sử dụng khối backbone resnet18 sau đó xóa đi khối fully connected cuối cùng và thay vào đó và một mạng MLP projection được thiết kế với 2 khối linear cơ bản. Đầu ra thu được các vector 128 chiều tương .
import torch.nn as nn
from torchvision.models import resnet18, resnet34
class SSL(nn.Module):
def __init__(self, projection_dim=128):
super().__init__()
self.enc = resnet18(pretrained=False) # load model from torchvision.models without pretrained weights.
self.feature_dim = self.enc.fc.in_features
# Customize for CIFAR10. Replace conv 7x7 with conv 3x3, and remove first max pooling.
# See Section B.9 of SimCLR paper.
self.enc.conv1 = nn.Conv2d(3, 64, 3, 1, 1, bias=False)
self.enc.maxpool = nn.Identity()
self.enc.fc = nn.Identity() # remove final fully connected layer.
# Add MLP projection.
self.projection_dim = projection_dim
self.projector = nn.Sequential(nn.Linear(self.feature_dim, 2048),
nn.ReLU(),
nn.Linear(2048, projection_dim))
def forward(self, x):
# Representaion
feature = self.enc(x)
# Projection head
projection = self.projector(feature)
4 Đào tạo mô hình self-supervised
Để trực quan hơn các bạn có thể thấy mỗi ảnh sẽ được đi qua 2 phép augmentation khác nhau hay mình hay gọi là 2 view khác nhau, sẽ đi qua mạng CNN để tạo thành các representation. Các representation này sẽ tiếp tục qua mạng MLP tạo thành đầu vào cho contrastive loss.

Triển khai giải thuật này cũng khá đơn giản, phần phía trên mình có viết lại hàm dataset một chút, mỗi sample đi vào mô hình sẽ được kết hợp từ 2 ảnh ứng với 2 view khác nhau.
imgs = [self.transform(img), self.transform(img)]
return torch.stack(imgs), target # stack a positive pair
Ouputs của mô hình sẽ được tính loss như thế nào?
Chúng ta đến với phần mà mình nghĩ là cần lưu ý nhất của các bài toán sefl-supervised. Để hiểu hơn về phần này thì các bạn cần đọc kỹ lại công thức hàm loss của contrastive learning và một số khái niệm mà mình trình bày ở các bài trước nhé. Bây giờ chúng ta đi sâu hơn về lập trình để triển khai hàm loss. Mục tiêu của hàm loss là để tối ưu sao cho các vector đặc trưng của cắp cặp mẫu positve lại gần nhau và các cặp mẫu negative cách xa nhau.
Hàm loss
def nt_xent(x, t=0.5):
x = F.normalize(x, dim=1)
x_scores = (x @ x.t()).clamp(min=1e-7) # normalized cosine similarity scores
x_scale = x_scores / t # scale with temperature
# (2N-1)-way softmax without the score of i-th entry itself.
# Set the diagonals to be large negative values, which become zeros after softmax.
x_scale = x_scale - torch.eye(x_scale.size(0)).to(x_scale.device) * 1e5
# targets 2N elements.
targets = torch.arange(x.size()[0])
targets[::2] += 1 # target of 2k element is 2k+1
targets[1::2] -= 1 # target of 2k+1 element is 2k
return F.cross_entropy(x_scale, targets.long().to(x_scale.device))
Nếu theo pipeline của mình thì giá trị nhận vào sẽ có dạng x (do đầu vào mình góp 2 hình ảnh của 2 phép biến đổi khác nhau vào cùng một sample, nên x đầu tiên là feature của ảnh qua phép biến đổi và x sau là feature của ảnh qua phép biến đổi ) trong đó N là giá trị batch-size và 128 là chiều của vector đặc trưng.
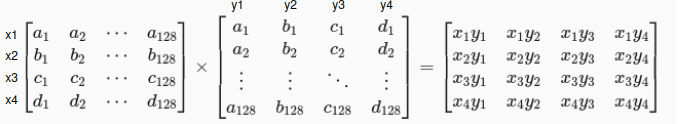
Mình sẽ tính ma trận cosine similarity bằng phép matrix multiplication giữa ma trận và ma trận chuyển vị của nó , kết quả thu được sẽ được chuẩn hóa và sacle với biến temperature thu được ma trận x_scale có dạng x . Các giá trị đường chéo trong ma trận chính là phép nhân 2 ma trận x và x (chuyển vị của nó) của cùng một feature (để trực quan hơn thì các bạn đặt bút và tính ma trận cosine similarity với N =4 chẳng hạn sẽ dể hình dung hơn) nên chúng ta cần lược bỏ các giá trị này khi tính loss. Ở đây mình khởi tạo một ma trận đơn vị sau đó nhân ma trận đơn vị này với một số dương lớn tạo thành một ma trận , mình lấy giá trị của ma trận x_sacle - ma trận thì các giá trị đường chéo trong ma trận x_scale sẽ trở thành số âm rất lớn, ma trận này khi đi qua sofmax trong hàm cross entropy thì các giá trị trong đường chéo sẽ về 0. Tiếp theo mình sẽ tiến hành tạo class cho chúng, có nhiều các tạo class cho 1 batch dữ liệu, mình thì tham khảo một repo thì họ có cách label khá hay khi đảo các vị trí chẵn lẻ cho nhau như trên code.
5 Kết quả thử nghiệm
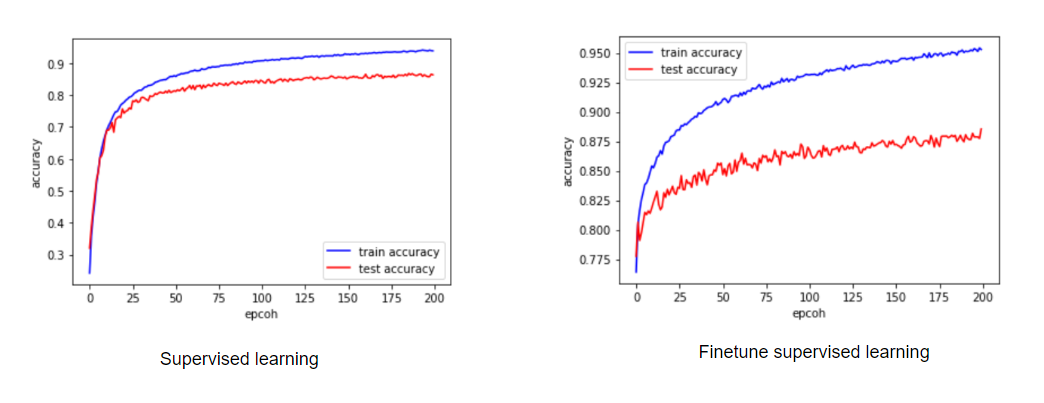
Mình có tiến hành visualize biểu đồ accuracy tính trên tập trainning và tập test của bộ cifar10 trong quá trình huấn luyện. Kết quả cho thấy rằng mô hình phân lớp có hiệu quả tốt hơn khi sử dụng trọng số backbone của mô hình self-supervised để fineturn cho toàn bộ mô hình. Cụ thể ở đây accuracy khi huấn luyện bình thường là 86% trong khi đó khi áp dụng self-supervised thì accuracy trên tập test tăng lên 88,1%. Thí nghiệm của mình ở đây chỉ để chứng tỏ tác động của self-supervised tới performance của mô hình trên cùng một kiến trúc, hơn thế nữa trong bài báo thì kết quả sẽ tốt hơn nếu mình huấn luyện với batchsize lớn (do cơ chế chọn cặp mẫu negative nên các bạn đọc thêm trong bài báo nhé). Do resource hạn chế nên trong thí nghiệm thì mình chỉ dùng batch-size=256 để training self-supervised trong khi report trong bài báo họ dùng batch-size=4096. Các bạn có thể thử thêm với nhiều option khác nữa nhé.
6 Kết luận
Self-supervised learning đã thực sự chứng minh được tính hiệu qủa trong việc cải thiện hiệu quả của mô hình, hơn thế nữa tư tưởng của self-supervised còn có thể áp dụng cho rất nhiều bài toán khác trong nhiều lĩnh vực như ảnh y tế, bài toán dạng chuỗi (NLP), video, âm thanh ... nếu chúng ta có thể định nghĩa được một pretext task hợp lý. Chủ đề về self-supervised còn rất nhiều nghiên cứu hay ho liên quan, bài báo mình implement lần này chỉ là một trong những phương pháp tiếp cận khá cơ bản và còn nhiều hạn chế. Nên mọi người có thể tìm kiếm và đọc thêm nhiều bài báo khác nữa nhé, mình sẽ cố gắng triển khai thêm một số thí nghiệm về chủ đề self-supervised cho một số bài toán khác cũng như là tìm một số cách tiếp cận mới. Có gì thú vị mình sẽ viết bài để tham khảo thêm ý kiến mọi người. Đừng quên upvote và chia sẽ cho mình nhé :v
Tài liệu tham khảo
- A Simple Framework for Contrastive Learning of Visual Representations (SimCLR)




