Redis server và tại sao lại tăng perfomance cho server
Tổng quan về Redis Server
-
Khi nói đến Resdis Server chúng ta cần nhớ:
-
Lưu trữ dữ liệu trên RAM
-
NoSql key/value store
-
Các key có thể chứa các cấu trúc dữ liệu như strings, hashes, list, sets and sorted sets
-
Hỗ trợ 1 tập hợp các atomic toán tử với các loại cậu trúc dữ liệu trên
-
Là máy chủ đơn luồng, nó không được thiết kế để hưởng lợi ích từ việc nhiều lõi CPU
-
Reddis thường được dùng làm:
- Database (Có thể persist data bên trong disk Redis)
- Caching layer (Nhanh hơn)
- Message broker (Không chỉ lưu trữ key - value)
-
-
Hãy đảm bảo chúng ta hiểu đúng về Redis:
- Redis không thể nào thay thế cho Relational Databases
- Được sinh ra để hỗ trợ cho SQL relational store, NoSQL document store
- Được sử dụng tốt nhất để thay đổi dữ liệu nhanh chóng với kích thướt cơ sỡ dữ liệu được thấy trước
-
Tiếp tục, hãy trả lời câu hỏi:
-
TẠI SAO chúng ta nên sử dụng nó - hay chính là lợi ích khi sử dụng Redis server
- Linh hoạt và nhanh chóng nhưng rất ổn định
- Lưu trữ data trong bộ nhớ đệm và ổ đĩa
- Không tồn tại khái niệm schemas và columns
- Hỗ trợ nhiều tính năng như sự sao chếp, tính bền bĩ, phân cụm hay độn khả dụng cao
-
KHI NÀO chúng ta lựa chọn sử dụng Redis
- Cần sử dụng cach database làm kết quả truy vấn cơ sở dữ liệu
- Sử dụng cho http session store
- Lưu trữ login/cookie vào bộ nhớ cache
- Lưu vào bộ nhớ cache toàn bộ các trang web
-
Như thế này bạn đã gần như nắm được khái niệm về Redis Server. Tiếp tục chính là Redis hỗ trợ đa dạng các loại dữ liệu là các loại gì?
Datatype trong Redis Server
- Cấu trúc Data model của Redis Sever:
-
Key: Printable ASCII
-
Value:
- Kiểu nguyên thủy: Strings
- Kiểu Colletion: Hashes - Lists - Sets - Sorted Sets
-
(*) Các dữ liệu không thể được lồng vào nhau
-
Chi tiết:
-
Value: Strings
-
Kích thước tối đa: 512 Mb
-
Byte sace, có thể lưu trữ các tệp nhị phân
-
Các trường hợp sử dụng: lưu trữ đối tượng được tuần tự hóa của JPGE & Store
-
Có thể thiết lập thời gian hết hạn cho kiến đó
SET greeting "Hello" EXPIRE greeting 10 TTL greeting GET greeting GET greeting SETEX greeting 10 "Hello" TTL greeting PERSIST greeting TTL greeting
-
-
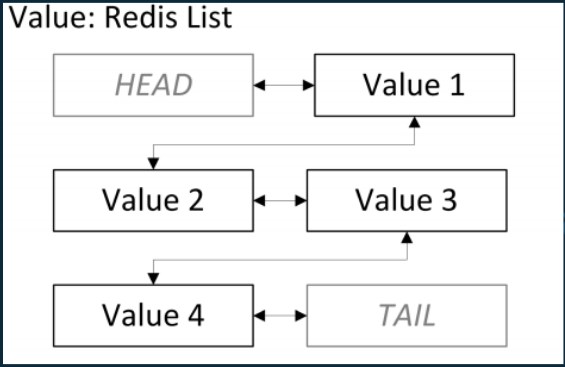
Value: Lists
- Là danh sách các chuỗi
- Thường được sử dụng để làm timelines của các mạng xã hội
- Redis hỗ trợ thao tác push/pop từ cả 2 phía của list, trim dựa theo offser; đọc 1 đến nhiều item trong list cũng như tìm kiếm và xóa giá trị trong list
- Tốc độ: Các thao tác ở đầu hoặc cuối danh sách rất nhanh, ở giữa thì sẽ chậm hơn
![]()
-
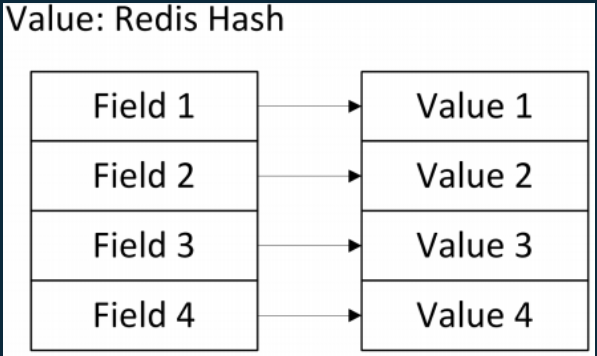
Value: Hashes
- Mapping key và value
- key field thì được sắp xếp ngẫu nhiên
- Redis có hỗ trợ các thao tác thêm, đọc, xóa từng phần từ trong tập hợp, cũng như đọc tất cả giá trị
![]()
-
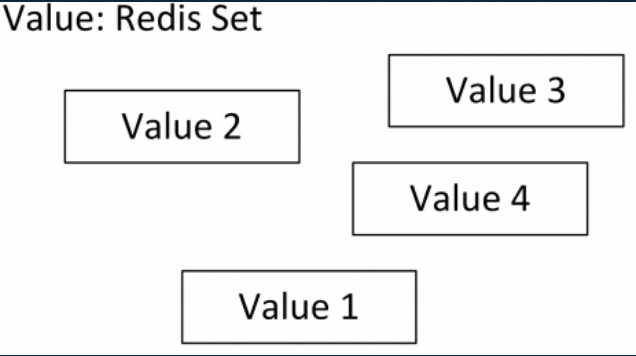
Value: Sets
- collection Strings nhưng KHÔNG có thứ tự
- Không tồn tại các phần tử lặp lại
- Thường được dùng để theo dõi các mặt dàng ko trùng lặp
- Redis hỗ trợ các thao tác cơ bản như thêm, đọc, xóa cũng như kiểm tra sự tồn tại giá trị phần tử trong tập hợp
- Ngoài ra, redis còn hỗ trợ các pháp toán tập hợp là intersect/union/difference
![]()
-
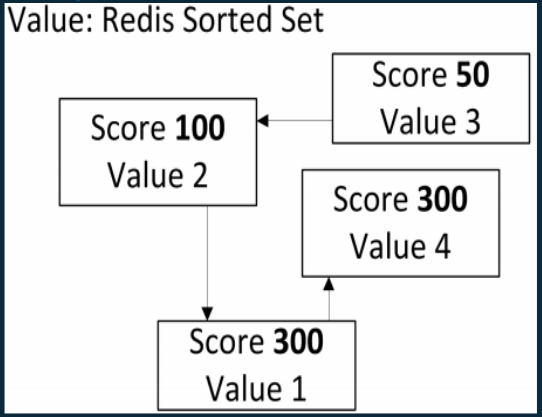
Values: Sorted Sets
- Là 1 danh sách, trong đó mỗi phần tử là 1 map của string (member) và 1 floadting-point scỏe (điểm), và danh sách sẽ được sắp xếp theo điểm này
- Thứ tự sắp xếp là các điểm nhỏ đến lớn
- Các member trong danh sách thì không trùng lặp, giống sets
- Thường được dùng để sắp xếp thứ tự các mặt hàng có cùng số điểm và sắp xếp theo bảng chữ cái
- Redis hỗ trợ các thao tác thêm đọc, xóa các phần tử cũng như lấy các phần tử dựa theo range của điểm hoặc của value
-
Transaction trong Redis Server
- Trong Redis server thì không có transaction như ở hệ quản trị cơ sở dữ liệu quan hệ.
- Theo định nghĩa thì 1 tập lệnh Redis là 1 transaction, vì vậy, mọi thứ bạn có thể làm với transaction của redis thì bạn cũng có thể làm với tập lệnh và thường thì tập lệnh sẽ đơn giản và nhanh hơn.
- Tất cả các tập lệnh được định nghĩa transaction trong redis thì được định nghĩa và thực thi tuần tự. Tức là nếu 1 câu lệnh không thành công, thì những cái khác vẫn sẽ được thực thi, đây là điểm khác biệt so với RDBMS
- Lý giải tại sao redis lại ko hỗ trợ rollback data khi có lỗi thì bên phía Redis giải thích như sau: Lệnh Redis chỉ có thể không thành công nếu được gọi sai cú pháp (và vấn đề không thể phát hiện được trong quá trình xếp hàng lệnh) hoặc đối với các phím giữ kiểu dữ liệu sai: điều này có nghĩa là trong điều kiện thực tế, lệnh không thành công là kết quả của lỗi lập trình, và một loại lỗi rất có thể được phát hiện trong quá trình phát triển chứ không phải trong quá trình sản xuất. Redis được đơn giản hóa bên trong và nhanh hơn vì nó không cần khả năng quay lại. Một lập luận chống lại quan điểm của Redis là lỗi xảy ra, tuy nhiên cần lưu ý rằng nói chung việc quay lại không giúp bạn tránh khỏi các lỗi lập trình. Ví dụ: nếu một truy vấn tăng một khóa lên 2 thay vì 1 hoặc tăng khóa sai, thì không có cách nào để cơ chế khôi phục lại trợ giúp. Do không ai có thể cứu lập trình viên khỏi lỗi của họ và loại lỗi bắt buộc để lệnh Redis không thành công khó có thể đưa vào sản xuất, chúng tôi đã chọn cách tiếp cận đơn giản và nhanh hơn là không hỗ trợ khôi phục lỗi.
Persistent data
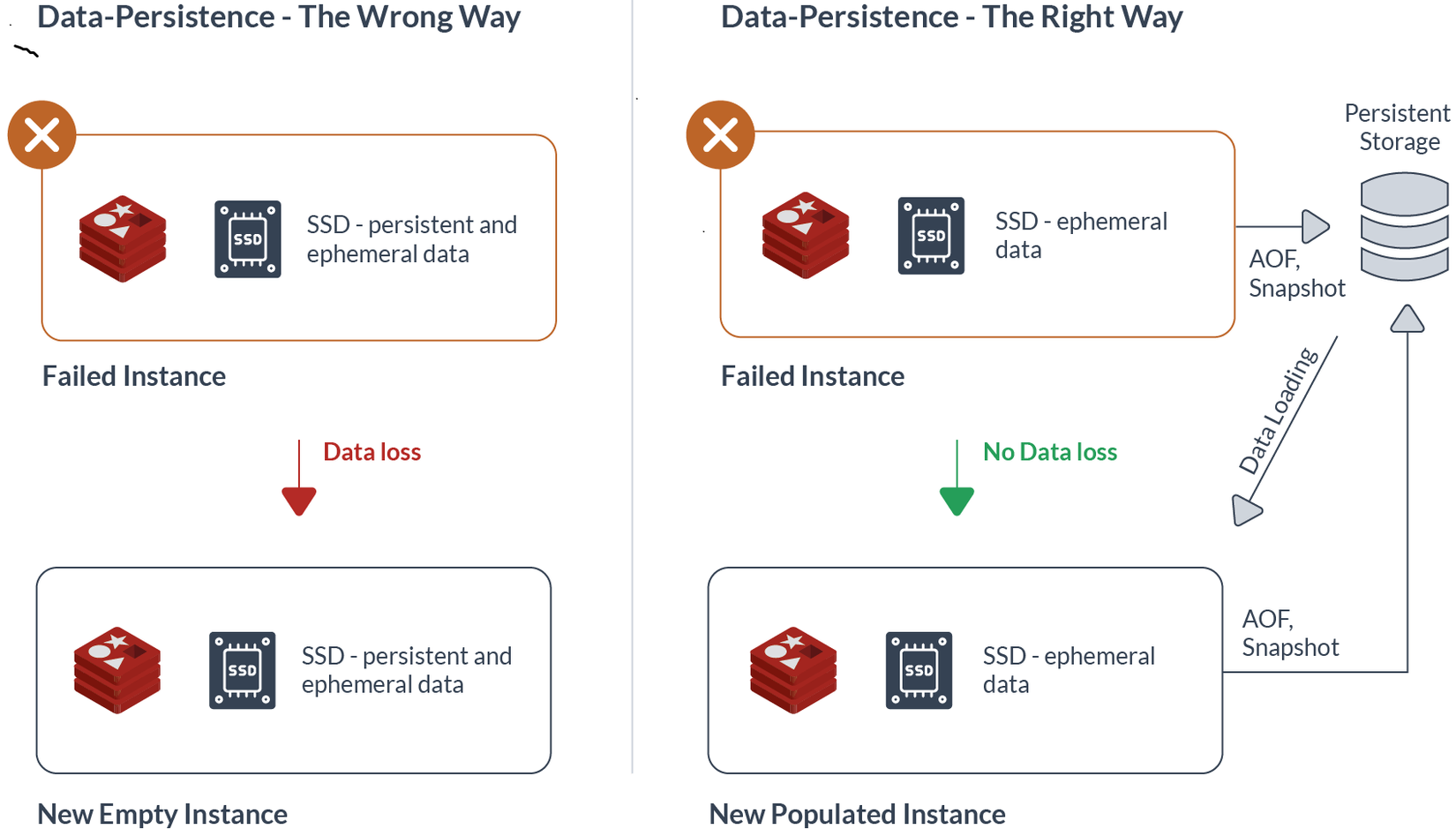
Hiện tại, mình chỉ bàn đến sự bền bỉ của data chứ không bàn đến chiều sâu là sự bền bỉ của memory nhé.
Mỗi lập trình viên đều biết là việc thao tác trên RAM sẽ nhanh hơn nhiều so với trên ổ cứng nhưng nếu server bị tắt đột ngột thì toàn bộ dữ liệu trên RAM sẽ mất. Vậy làm sao để Redis không bị mất dữ liệu.
Thật ra, trong Redis có hỗ trợ cơ chế lưu trữ dữ liệu lên ổ cứng sau 1 khoảng thời gian nhất định. Đây cũng chính là cơ chế giúp Redis server không lo lắng việc mất mát dữ liệu dù lưu trữ trên RAM, hay phục vụ cho việc tái tạo lại dataset khi restart rserver
Cơ chế lưu dữ liệu gồm:
-
RDB
- Cho phép người dùng tạo và lưu các version khác nhau của DB vào ổ cững sau 1 khoảng thời gian nhất định, có thể dễ dàng backup lại dữ liệu khi có sự cố xảy ra.
- Bằng việc lưu trữ data vào 1 file cố định, người dùng có thể dễ dàng chuyển data đến các data centers khác nhau, hoặc chuyển đến lưu trữ trên Amazon S3.
- RDB giúp tối ưu hóa hiệu năng của Redis. Tiến trình Redis chính sẽ làm các công việc trên RAM, bao gồm các thao tác cơ bản được yêu cầu từ phía client, trong khi đó 1 tiến trình con sẽ đảm nhiệm các thao tác disk I/O. Cách tổ chức này giúp tối đa hiệu năng của Redis. Khi restart server, dùng RDB làm việc với lượng data lớn sẽ có tốc độ cao hơn là dùng AOF.
- Tuy nhiên RDB không phải là lựa chọn tốt nếu bạn muốn giảm thiểu tối đa nguy cơ mất mát dữ liệu. vì khi chúng ta setup 5p ghi dữ liệu vào đĩa thì sẽ xảy ra tình trạng mất mát dữ liệu.
- Ngoài ra, mặc hạn chế nữa là RDB cần dùng fork() để tạo tiến trình con phục vụ cho thao tác disk I/O. Trường hợp dữ liệu quá lớn thì quá trình fork cũng tốn nhiều thời gian và đòi hỏi server phải mạnh để có thể đáp ứng được
![]()
-
AOF
- Lưu lại tất cả các thao tác write mà server nhận được, các thao tác này sẽ được chạy lại khi restart server hoặc tái thiết lập dataset.
- AOF sẽ an toàn hơn RDB. không xảy ra mất mát dữ liệu. Người dùng có thể config để Redis ghi log theo từng câu query hoặc mỗi giây 1 lần.
- Redis ghi log AOF theo kiểu thêm vào cuối file sẵn có, kể cả khi chỉ 1 nửa câu lệnh được ghi trong file log, Redis vẫn có cơ chế quản lý và sửa chữa lỗi
- Redis cung cấp tiến trình chạy nền, cho phép ghi lại file AOF khi dung lượng file quá lớn.
- Tuy nhiên, với các ưu điểm trên thì các file ÀO thường lớn hơn file RDB
- AOF có thể chậm hơn RDB tùy theo cách thức thiết lập khoảng thời gian cho việc sao lưu vào ổ cứng.
-
Redis cho phép không sử dụng tính năng lưu trữ thông tin trong ổ cứng (không RDB, không AOF), đồng thời cũng cho phép dùng cả 2 tính năng này trên cùng 1 instance. Tuy nhiên khi restart server, Redis sẽ dùng AOF cho việc tái tạo dataset ban đầu, bới AOF sẽ đảm bảo không bị mất mát dữ liệu tốt hơn là RDB.
Bài viết được tham khảo tại:





