Introduction
English version can be read at Eng-ver
Blog này giới thiệu về cách thiết lập phân tích realtime mã nguồn mở. Chúng tôi sẽ sử dụng Kafka và Apache {Airflow, Superset, Druid}.
Việc có số liệu phân tích của bạn theo kiểu truyền trực tuyến cho phép bạn liên tục phân tích hành vi của khách hàng và hành động theo hành vi đó. Chung quy là mình cũng muốn test thử khả năng realtime của Druid mình đang nghiên cứu một vài solution realtime analytic chi tiết code có thể tham khảo tại repo Github
Trong bài viết này sử dụng Aiflow như một producer có nhiệm vụ gửi data đến kafka topic, dữ liệu phân tích được lưu trữ trong Druid và được hiển thị trực quan bằng Superset.
Kafka
Kafka là một hệ thống message theo cơ chế Pub-Sub. Nó cho phép các nhà sản xuất (gọi là producer) viết các message vào Kafka mà một, hoặc nhiều người tiêu dùng (gọi là consumer) có thể đọc, xử lý được những message đó. Các message được gửi tới Kafka theo Topic, các Topic giống như là các kênh lưu trữ message từ Producer gửi đến Kafka, người tiêu dùng (Consumer) đăng kí một hoặc nhiều Topic để tiêu thụ những message đó.
Kafka có thời gian lưu giữ, vì vậy nó sẽ lưu trữ message của bạn theo thời gian hoặc kích thước bạn cấu hình và có thể được chỉ định gửi theo Topic.Kafka hoạt động tốt khi kết hợp với Apache Flink và Apache Spark để phân tích và hiển thị dữ liệu truyền trực tuyến theo thời gian thực. Trong bài viết này kafka được sử dụng để thu thập dữ liệu và load vào trong Druid.
Druid
Druid cung cấp khả năng nhập dữ liệu thời gian thực có độ trễ thấp từ Kafka, thăm dò dữ liệu linh hoạt và tổng hợp dữ liệu nhanh chóng. Druid không được coi là một hồ dữ liệu (data lake) mà thay vào đó là một dòng sông dữ liệu. Vì dữ liệu đang được tạo ra bởi người dùng, cảm biến hoặc bất cứ thứ gì, nó sẽ chảy trong bối cảnh ứng dụng. Như với thiết lập Hive / Presto, dữ liệu thường thực hiện hàng giờ hoặc hàng ngày, nhưng với Druid, dữ liệu có sẵn để truy vấn khi truy cập vào cơ sở dữ liệu. Druid đươc đánh giá là cải thiện 90% -98% tốc độ so với Apache Hive (chưa kiểm chứng).
Superset
Apache SuperSet là một công cụ trực quan hóa dữ liệu Nguồn mở có thể được sử dụng để biểu diễn dữ liệu bằng đồ họa. Superset ban đầu được tạo ra bởi AirBnB và sau đó được phát hành cho cộng đồng Apache. Apache Superset được phát triển bằng ngôn ngữ Python và sử dụng Flask Framework cho tất cả các tương tác web. Superset hỗ trợ phần lớn RDMBS thông qua SQL Alchemy.
Bắt đầu thôi!
Sử dụng Docker, thật dễ dàng để thiết lập một phiên bản cục bộ và có thể thử và khám phá các ý tưởng của bạn một cách dễ dàng hơn.
Để thiết lập hệ thống, bắt đầu bằng cách sao chép kho lưu trữ git:
git clone https://github.com/apot-group/real-time-analytic.git
cd real-time-analytic
Tiếp theo, chúng ta cần xây dựng các hình ảnh cục bộ:
docker-compose rm -f && docker-compose build && docker-compose up
Vì xây dựng hình ảnh từ đầu, nên việc này có thể mất một lúc. Sau khi thực hiện lệnh docker-compile up, các dịch vụ sẽ khởi động. Có thể mất một khoảng thời gian trước khi mọi thứ bắt đầu và chạy.
| Service | URL | User/Password |
|---|---|---|
| Druid Unified | http://localhost:8888/ | None |
| Druid Legacy | http://localhost:8081/ | None |
| Superset | http://localhost:8088/ | docker exec -it superset bash superset-init |
| Airflow | http://localhost:3000/ | admin - app/standalone_admin_password.txt |
Lưu ý là với airflow user "admin" và password sẽ tự tạo tại folder a-airflow đường dẩn /app/standalone_admin_password.txt sau khi server chạy dùng thông tin này để đăng nhập nhé. Còn với Superset thì cần đi đến container đang chạy và thực hiện lệnh init để tạo user với pass:
$ docker exec -it superset superset-init
Username [admin]: admin
User first name [admin]: Admin
User last name [user]: User
Email [admin@fab.org]: admin@superset.com
Password:
Repeat for confirmation:
Airflow dags tại app_airflow/app/dags/demo.py được cấu hình chạy mỗi phút một lần thực hiện gửi tin nhắn đến topic 'demo' kafka với dữ liệu về danh sách coin và giá theo thời gian bao gồm ['BTC', 'ETH', 'BTT', 'DOT'] cấu trúc của thông báo dữ liệu như bên dưới mình chỉ random về giá cho đơn giản nhé. để bật start streaming thì login vào airflow và bật dags demo lên nhé.
{
"data_id" : 454,
"name": 'BTC',
"timestamp": '2021-02-05T10:10:01'
}

Note: Nếu bạn không muốn sử dụng airflow thì đơn giản hơn với một python file producer.py đã được viết sẵn với tương tự như demo dag trong airflow chỉ việc chạy nó từ thư mục repo.
$ python3 producer.py
Producing message @ 2022-10-22 12:29:20.479806 | Message = {'data_id': 100, 'name': 'BTC', 'timestamp': 1666391360}
Producing message @ 2022-10-22 12:29:20.482750 | Message = {'data_id': 23, 'name': 'ETH', 'timestamp': 1666391360}
Producing message @ 2022-10-22 12:29:20.482898 | Message = {'data_id': 32, 'name': 'BTT', 'timestamp': 1666391360}
Producing message @ 2022-10-22 12:29:20.482991 | Message = {'data_id': 158, 'name': 'DOT', 'timestamp': 1666391360}
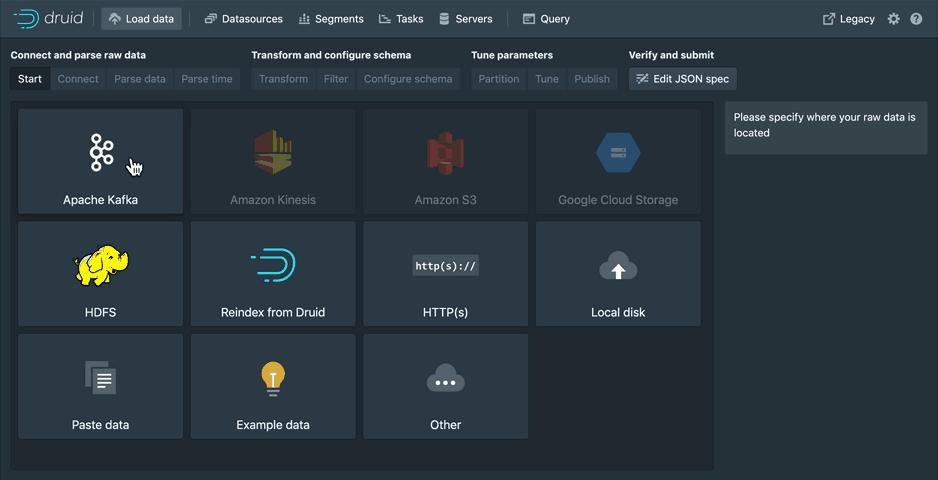
Tiếp theo là cấu hình để Druid nhận dữ liệu từ topic demo trong kafka. Từ Druid Service http://localhost:8888/ chọn load data > kafka điền thông tin kafka server kakfa:9092 và topic demo và config output.
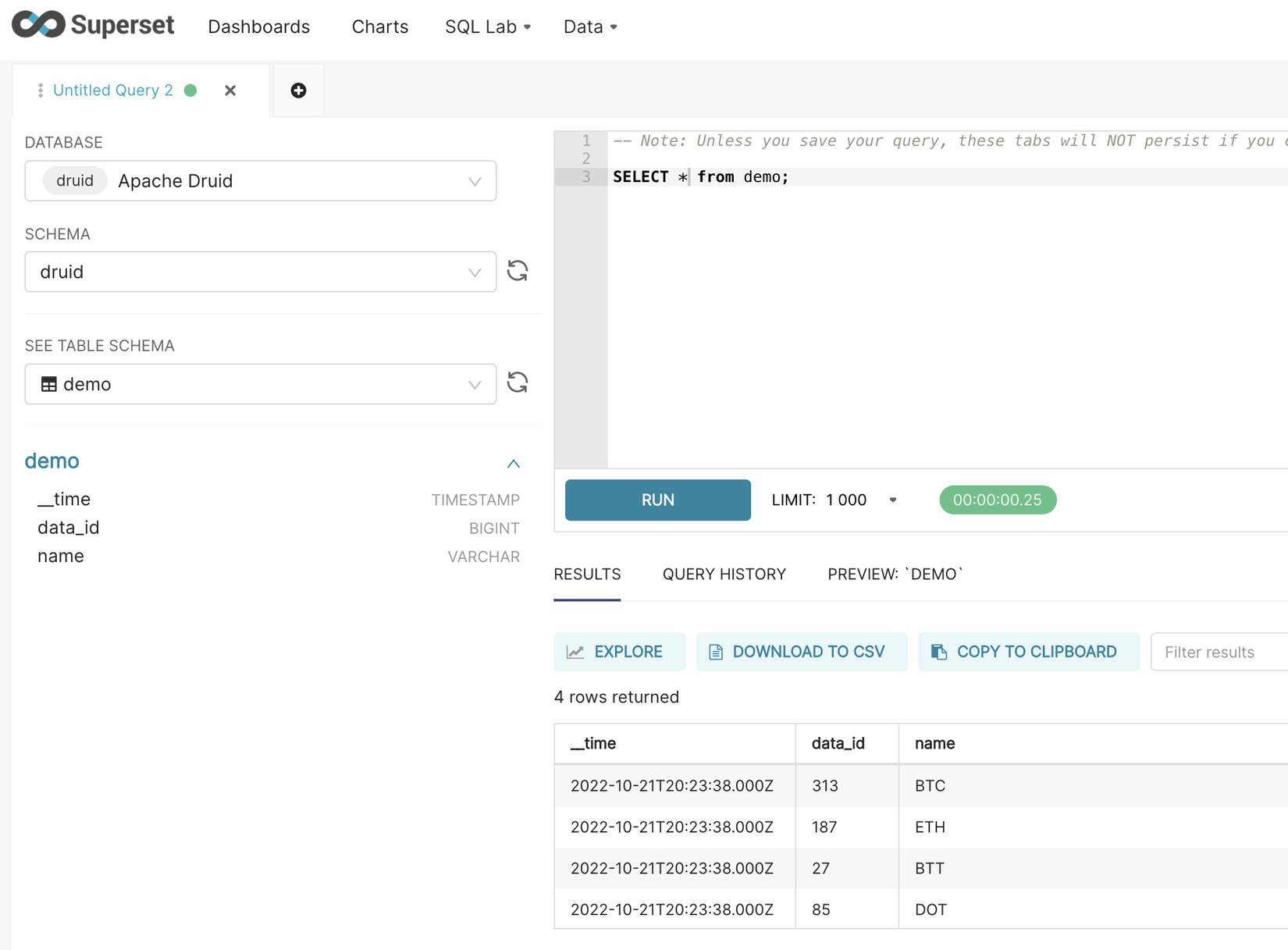
Login vào Superset http://localhost:8088/ tạo kết nối với với druid Data > Databases > +Database như một database với sqlalchemy uri: druid://broker:8082/druid/v2/sql/ chi tiết các kết nối hơn có thể tham khảo Superset-Database-Connect
Để tạo dashboard với superset. Để tạo chart bạn cần vào SQL Lab > SQL Editor chọn database là druid , schema druid , table demo và thực hiện query theo ý mình. Sau khi hoàn tất thì explore > đặt tên cho dataset và Save & Explore chọn chart và public thành dashboard.
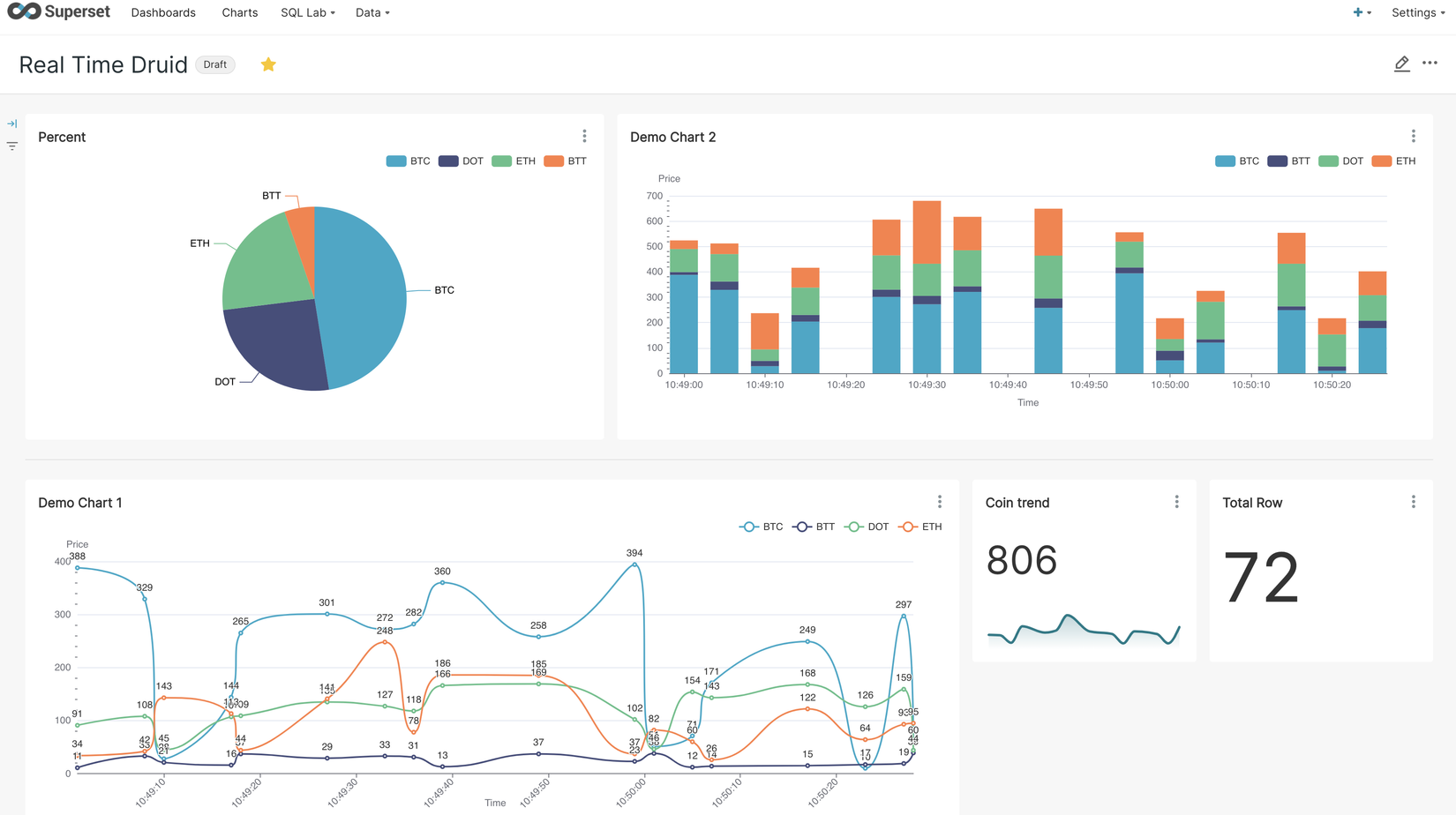
Cuối cùng là enjoy cái moment thoi! 


