Bạn nào chưa xem phần 1 có thể xem tại đây
Đĩ: Anh Nghiện ơi, hôm nọ anh bảo em vẫn có vấn đề.
Nghiện: Vấn đề gì thế?
Đĩ: Theo mô hình hôm trước của anh thì nếu nhiều request thì vẫn có cổ chai là database.
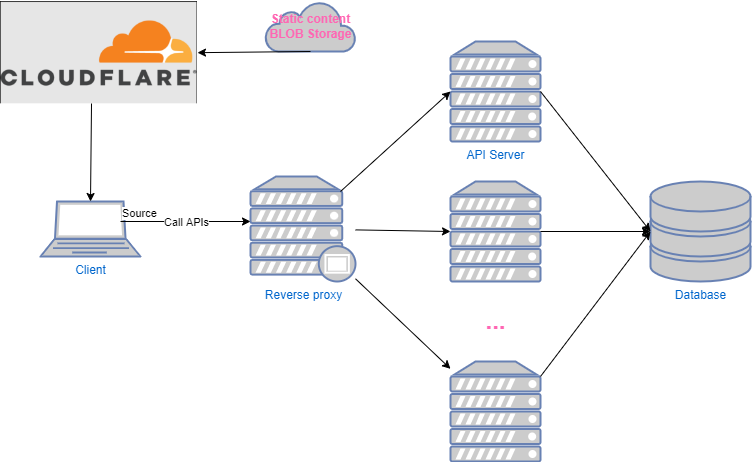 Nghiện: Em làm gì mà có nhiều request vào db thế, có nhiều giữ liệu ít thay đổi mà hay được truy vấn không?
Nghiện: Em làm gì mà có nhiều request vào db thế, có nhiều giữ liệu ít thay đổi mà hay được truy vấn không?
Đĩ: Có nhiều chứ anh như danh sách sân golf, danh sách xe sang với danh sách các cuộc thi hoa hậu thì cũng không đổi nhiều lắm, mà lại cần lấy ra nhiều.
Nghiện: Có lẽ chúng ta cần một hệ thống cache.
Đĩ: Cache nghe quen quen, giống bộ nhớ cache trong máy tính à?
Nghiện: Đúng rồi nhưng bộ nhớ cache kia nhỏ để phục vụ cho CPU, còn hệ thống cache này lớn hơn dành cho cả hệ thống của em.
Đĩ: Rốt cuộc cái cache đấy nó làm cái gì?
Nghiện: Thay vì đọc vào database để lấy dữ liệu, hệ thống sẽ đọc từ cache, do vậy giảm request tới database để database chịu tải tốt hơn, với đọc dữ liệu ra từ cache cũng nhanh hơn nữa.
- Đọc 1MB từ RAM mất 0.25ms
- Đọc 1M từ SSD mất 1ms
- Đọc 1M từ mạng mất 10ms
- Đọc 1M từ HDD mất 20ms
- Đọc 1M từ Đông Lào qua Mỹ mất 150ms
Đĩ: Vậy mình triển khai thôi, có những loại cache nào anh?
Nghiện: Có hai kiểu cơ bản In-Memory Cache và Distribution Cache ngoài ra có thể cache trên Client hoặc tạo bảng cache trên DB nữa, nhưng anh tập trung vào hai loại đầu thôi.
Đĩ: Bắt đầu thôi anh
Nghiện: Đầu tiên để tránh phức tạp chúng ta bắt đầu với In-Memory Cache trước, nó là việc cache dữ liệu ngay trên Ram của các API Server. Ví dụ những dữ liệu sân golf, xe sang, hay cuộc thi hoa hậu kia sẽ được em lưu trong một danh sách, hoặc hash table ngay trong RAM để lúc cầu em đọc ra luôn.
Đĩ: Thế này cũng hay nhưng mà nếu cache nhiều thì có thể gây hết RAM.
Nghiện: Đúng rồi, nên phải có một số giải pháp để xóa cache lâu không dùng, hoặc vào cache lâu rồi có nhiều thuật toán để làm điều này, thông thường là LRU (Least Recent Use) hoặc FIFO(First in First out) hoặc LFU(Least Frequently Use) em tham khảo Wiki nhé!
Đĩ: Còn một chỗ này nữa, không phải người dùng nào em cũng cần cache giống nhau, có thể cache theo kiểu request cần gì em sẽ đọc theo ưu tiên cache->DB -> Lưu lại vào cache. Kiểu nếu không có trong cache em đọc trong DB, lấy kết quả đó lưu lại vào cache để lần sau gọi thì không trỏ vào DB nữa được không?
Nghiện: Cơ bản là được, lúc em tìm thấy dữ liệu trong cache được gọi là cache HIT, nếu không thấy thì được gọi là cache MISS
Đĩ: Vậy em có gặp vấn đề thế này, do mỗi người dùng ở vị trí khác nhau sẽ có nhu cầu cache khác nhau, ví dụ đội chị em ở Công Viên Hòa Bình, khác đội chị em ở Trần Duy Hưng, hoặc đội chị em ở sân golf.
Nghiện: Ừ sao?
Đĩ: Nhưng mà khi chị em ở công viên Hòa Bình gọi lên request em cache ở server A rồi được cache ở server A, rồi sau chị ấy lại gọi lên con Reverse Proxy lại trỏ sang server B, mà server B không có cache (bị MISS) dẫn tới bị chậm, mất khách chị em kêu lắm.
Nghiện: Con Reverse Proxy em đang để măc định là Round Robin đúng không?
Đĩ: Đúng rồi!
Nghiện: Thế nó cứ tuần tự hết con này sang con khác, để tránh điều này em nên dùng một thuật toán Hash để từ một người dùng sẽ được điều vào một máy chủ duy nhất.
Đĩ: Ok nhưng em thấy một vấn đề, nếu máy chủ server A bị chết thì chị em công viên Hòa Bình sẽ không có ai được nhận, và nếu em muốn nâng server để tăng tải thì server đó cũng không bao giờ được trỏ đến đúng không?
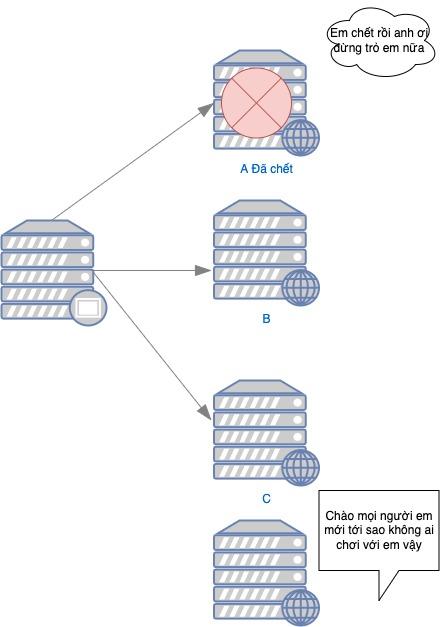
Nghiện: Code nhiều rồi thông mình lên nhanh thế nhỉ, đúng là có vấn đề này và người ta khắc phục nó bằng một số thuật toán khác như consistent hashing hoặc rendezvous, nó vẫn đảm bảo được việc mỗi client trỏ đến đúng server và không bị ảnh hưởng bởi việc thêm hay xóa một server.
Đĩ: Ok ngầu rồi đó. Đi tiếp đi anh em nóng hết người lên rồi.
Nghiện: OK giờ tới Distribution Cache nó đơn giản là lưu cache ở server khác không lưu ở trên server API của mình.
Đĩ: Như vậy có vẻ sẽ tốn đường truyền mạng nên chậm hơn In-Memory Cache và nếu cái server đó sập thì hệ thống cache đi tong luôn đúng không?
Nghiện: Đúng rồi, nhưng có thể replicate để tránh trường hợp cổ chai để tăng tính HA (high availability) của hệ thống cache. Nó cũng có ưu điểm khi cache tập trung thì việc cập nhật cache cũng dễ dàng hơn, không bị cảnh mỗi server cache một kiểu như In-Memory Cache và nó cũng có tác dụng nếu em khởi động lại cách server API thì cache cũng không bị ảnh hưởng.
Đĩ: Vậy em chơi kết hợp cả In-Memory và Distribution Cache đi, vẫn ngon đúng không anh.
Nghiện: Ngon bình thường, thậm chí em có thể làm một hệ thống cache nhiều tầng, nếu memory MISS, em truy vấn trong distribution, nếu distribution MISS em truy vấn trong database. Tất nhiên phải tùy theo nghiệp vụ chứ không được nhắm mắt đưa chim à nhâm đưa chân là khổ đấy!
Đĩ: OK rồi vậy em cài thử xem, cái distribution cache hay dùng là cái gì nhỉ?
Nghiện: Thường được dùng là Redis
Đĩ: Ok vậy hệ thống của em như thế này đúng không?
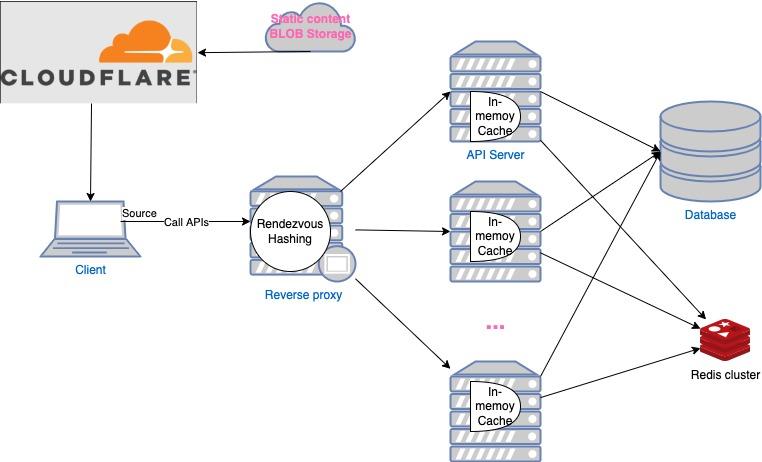
Nghiện: Đúng vậy, khi nào xong đi tua gọi anh nhé!
Đĩ: OK sắp ngon rồi, thơm cho cái này.
Một số khái niệm cần nhớ: Cache, In-Memory Cache, Distribution Cache, Cache MISS, Cache HIT, Round Robin,consistent hashing,LRU (Least Recent Use) , FIFO(First in First out) LFU(Least Frequently Use), Redis,HA
Link bài sau


