Một số kiến thức cần biết
Mình khuyến khích mọi người trước khi đọc bài này thì nên đọc về Generalized Focal Loss hoặc bài phân tích về Generalized Focal Loss (GFL) mà mình đã viết ở đây để có thể hiểu rõ được bài này. Tuy nhiên, mình vẫn sẽ tóm tắt lại các ý chính của GFL ở đây.
Trong cấu trúc của các Dense Object Detector thường có 3 đầu ra: đầu ra cho Classification, Localization và một đầu ra cho chất lượng của localization (Localization Quality). Các tác giả của GFL nhận thấy 2 vấn đề:
- Nhánh Classification và Localization Quality trong quá trình training và testing không đồng bộ với nhau
- Các sự biểu diễn của Bounding Box chưa cân nhắc đến tính không rõ ràng của vật thể
Do vậy, GFL đã thay đổi cấu trúc 3 đầu ra của các Dense Object Detector thông thường thành kiến trúc 2 đầu ra, với đầu ra Classification là sự kết hợp giữa Classification và Localization Quality, đồng thời thiết kế một hàm loss mới gọi là Quality Focal Loss (QFL) cho sự kết hợp này. Và GFL cũng thay đổi sự biểu diễn của Bounding Box, từ phân phối Delta Dirac thành phân phối tự do, và tạo ra hàm loss mới gọi là Distribution Focal Loss (DFL) cho sự biểu diễn này.
Đặt vấn đề
GFLv2 nhận thấy rằng, các Dense Object Detector khác dự đoán Localization Quality sử dụng các feature từ các lớp Convolution trước đó. GFLv2 đề ra một hướng tiếp cận khác đến việc dự đoán Localization Quality, sử dụng thống kê từ sự biểu diễn của Bounding Box thay vì feature từ Convolution. Ở đây, sự biểu diễn của Bounding Box được kế thừa từ GFL, sử dụng General Distribtion (phân phối tự do).
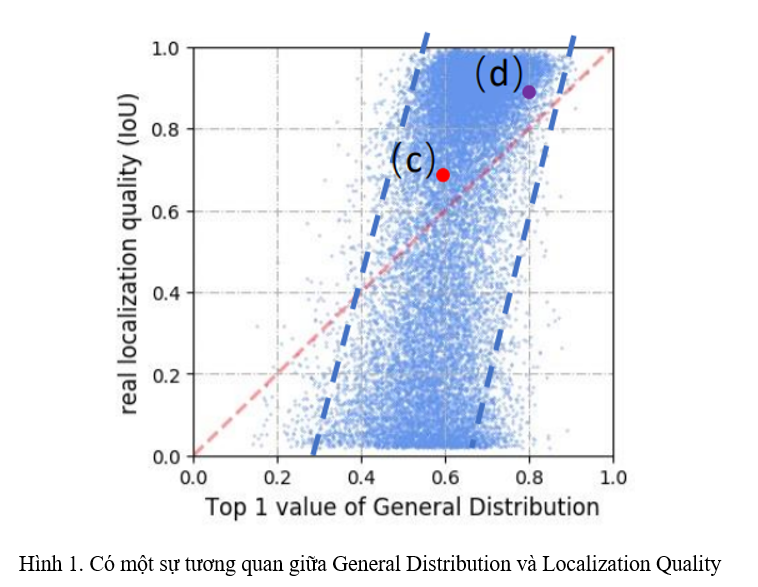
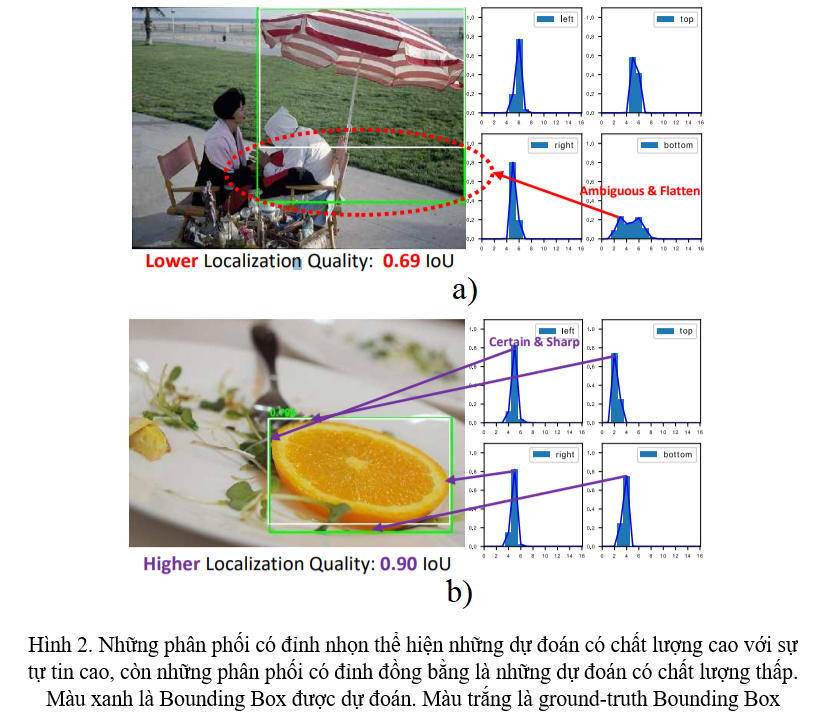
Ý tưởng của hướng tiếp cận này là do nhóm tác giả quan sát được rằng, thống kê thu được từ General Distribution có một sự tương quan mạnh với Localization Quality (Hình 1).
Cụ thể hơn, ở Hình 2a và 2b, hình dạng của General Distribution cho Bounding Box phản ánh rõ ràng chất lượng của sự dự đoán: Phân phối càng sắc nhọn thì độ tự tin cho dự đoán về Bounding Box càng cao, và ngược lại. Từ đó, nhóm tác giả có ý tưởng rằng Localization Quality có thể được tính toán thông qua thông tin về phân phối của Bounding Box.
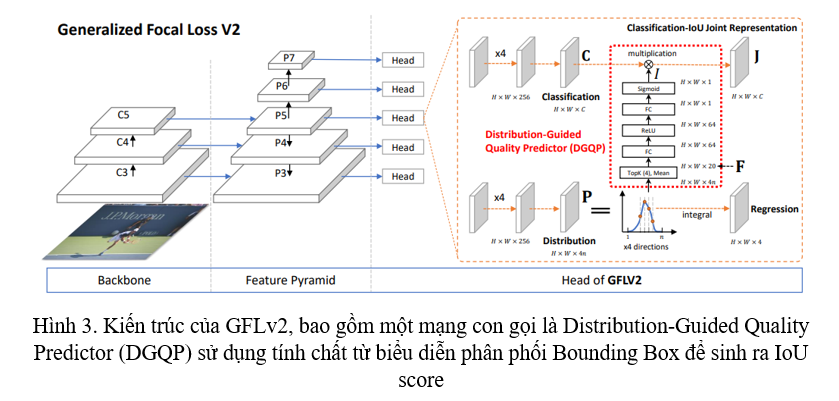
Nhóm tác giả tạo ra một mạng nơ-ron nhỏ gồm một vài (cụ thể là 64) hidden units để sinh ra Localization Quality từ thống kê của phân phối Bounding Box và gọi nó là Distribution-Guided Quality Predictor (DGQP), tạm dịch là dự đoán chất lượng dựa trên phân phối.
Phương pháp cụ thể
Trong phần này, ta sẽ nhắc lại một chút về Generalized Focal Loss rồi sau đó triển khai Generalized Focal Loss v2 dựa trên đó.
Generalized Focal Loss V1
Sự biểu diễn kết hợp giữa Classification và IoU. Sự biểu diễn kết hợp giữa Classification và Localization Quality này là thành phần chính trong GFLv1, được thiết kế để giảm đi sự bất đồng bộ giữa Classification và Localization Quality trong training và testing. Tóm gọn lại, cho một object với label với là tổng số loại object (category), ở nhánh Classification của GFLv1 sẽ sinh ra sự biểu diễn kết hợp giữa Classification và IoU có dạng thỏa mãn:
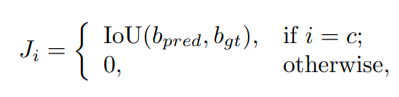
với là IoU giữa Bounding Box đự đoán và ground truth Bounding Box .
Phân phối tự do để biểu diễn Bounding Box. Các Object Detector thường biểu diễn Bounding Box dưới dạng phân phối Delta Dirac . Nhưng GFLv1 sử dụng một General Distribution (phân phối tự do) để biểu diễn Bounding Box, với mỗi cạnh có thể được biểu diễn theo công thức với khoảng cho trước. Để tương thích với mạng nơ-ron tích chập, tích phân trên miền liên tục sẽ được chuyển sang miền rời rạc, với khoảng sẽ được rời rạc hóa thành với khoảng đều nhau . Do vậy, với tính chất của phân phối rời rạc , giá trị dự đoán có thể được biểu diễn dưới dạng:
Khác với phân phối Delta Dirac, General Distribution được tin rằng là có khả năng phản ánh Localization Quality, đó cũng là ý chính của paper này.
Generalized Focal Loss V2
Tách rời sự biểu diễn kết hợp của Classification và IoU. Mặc dù sự biểu diễn kết hợp giữa Classification và Localization Quality giải quyết được vấn đề bất đồng bộ giữa Classification và Localization Quality trong training và testing, song vẫn còn một số hạn chế trong việc chỉ sử dụng nhánh Classification để dự đoán sự biểu diễn kết hợp này. Trong paper này, nhóm tác giả phân tách sự biểu diễn kết hợp này bằng việc kết hợp thông tin từ 2 nhánh là nhánh Classification và nhánh Regression :
![]()
với , là sự biểu diễn của Classification của tổng categories, và là một giá trị vô hướng, là sự biểu diễn của IoU.
Mặc dù được phân tách làm 2 thành phần, nó vẫn là sự biểu diễn kết hợp được dùng trong cả training và testing, như vậy ta vẫn tránh được vấn đề bất đồng bộ được nhắc tới trong GFLv1. Cụ thể hơn, ta sẽ kết hợp từ nhánh Classification và từ Distribution-Guided Quality Predictor (DGQP) từ nhánh Regression thành sự kết hợp . Sau đó, được sử dụng trong Quality Focal Loss (QFL) như trong GFLv1 lúc training, và dùng trong NMS lúc testing.
Distribution-Guided Quality Predictor. DGQP là thành phần chính của GFLv2, nó có nhiệm vụ nhận các thông tin từ General Distribution để sinh ra IoU Score , sau đó dùng để tạo ra sự biểu diễn kết hợp của Classification và IoU. Theo chân GFLv1, nhóm tác giả sử dụng khoảng cách từ tâm tới 4 cạnh của Bounding Box làm giá trị để regression. Ta kí hiệu trái, phải, trên, dưới là , và xác suất rời rạc của cạnh là với .
Như biểu diễn trong hình 2, độ bằng phẳng của phân phối sẽ tương quan với chất lượng của Bounding Box được dự đoán. Những thông tin về thống kê của phân phối Bounding Box có tương quan mạnh với Localization Quality, từ đó sẽ khiến việc training dễ hơn và đưa ra những dự đoán chất lượng hơn. Nhóm tác giả sử dụng top- giá trị cùng với giá trị trung bình của chúng ở trong mỗi phân phối , kết hợp chúng lại thành statistical feature (feature về mặt thống kê) :
![]()
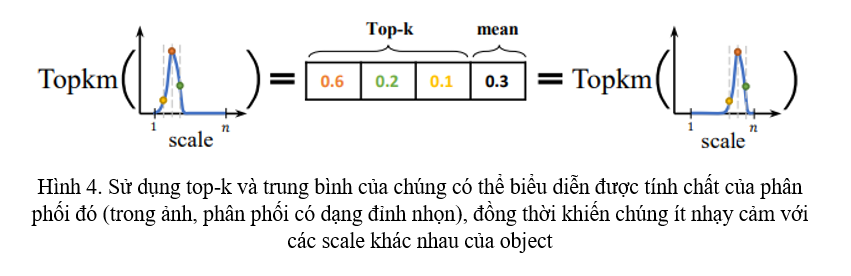
với là top- giá trị được lựa chọn và trung bình của chúng. là channel concatenation. Việc lựa chọn top- giá trị và trung bình làm thông tin của phân phối Bounding Box có ý nghĩa sau:
- Vì tổng của là một giá trị không đổi , top- cùng với trung bình của chúng có thể phản ánh tính chất của phân phối đó: giá trị lớn, giá trị còn lại nhỏ, và trung bình của chúng lớn thì phân phối đó khá sắc nhọn, còn các giá trị ngang nhau và trung bình của chúng nhỏ thì phân phối có dạng đồng bằng (Hình 4)
- Top- và giá trị trung bình của chúng sẽ làm cho statistical feature ít nhạy cảm với sự dịch chuyển ở trên miền phân phối (Hình 4), khiến cho sự biểu diễn của Bounding Box ít bị ảnh hưởng bởi độ lớn của object
Với statistical feature thu được từ General Distribution, nhóm tác giả thiết kế một mạng nơ-ron nhỏ để dự đoán chỉ số IoU. Mạng nơ-ron nhỏ này chỉ bao gồm 2 lớp Fully-Connected (Hình 3). Giá trị vô hướng IoU được tính theo công thức sau:
![]()
với và là ReLU và Sigmoid. và . là trị số trong top- và là số channel trong hidden layer. Trong paper này, qua một số các thử nghiệm, nhóm tác giả chọn ra và .
Kết quả
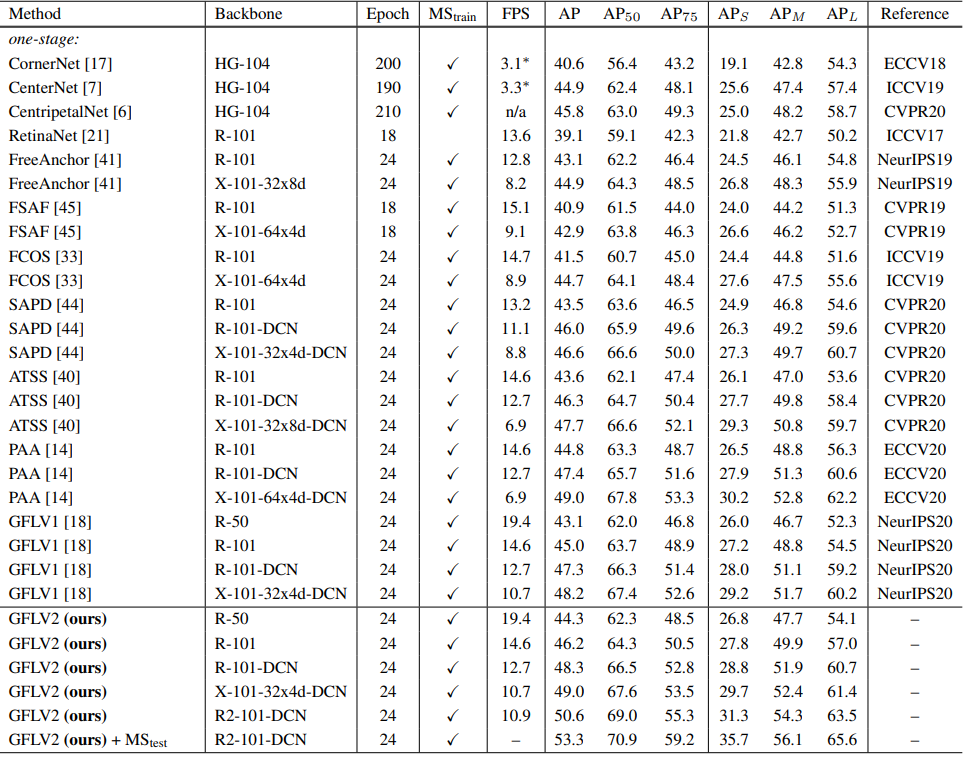
TL;DR
Mình sẽ tóm tắt lại paper cho những ai cảm thấy quá sức với những công thức toán học ở bên trên, để có thể nắm được ý tưởng của paper này theo phong cách 3W.
[W]hat
- Một Head mới cho các Object Detector dựa trên GFLv1
[W]hy
- Nhóm tác giả quan sát thấy có sự tương quan giữa sự biểu diễn của Bounding Box (General Distribution) và ground-truth Localization Quality, cụ thể là IoU Score (Hình 1).
Ho[W]
- Sử dụng các thông tin từ sự biểu diễn của Bounding Box (General Distribution), cụ thể là top- giá trị và trung bình của chúng, tạo ra Statistical Feature.
- Tạo ra một mạng nơ-ron nhỏ, biến đổi Statistical Feature thành Predict IoU Score để kết hợp với Classification Score trong nhánh Classification.
Các thử nghiệm và phân tích
Lựa chọn thông tin từ General Distribution?
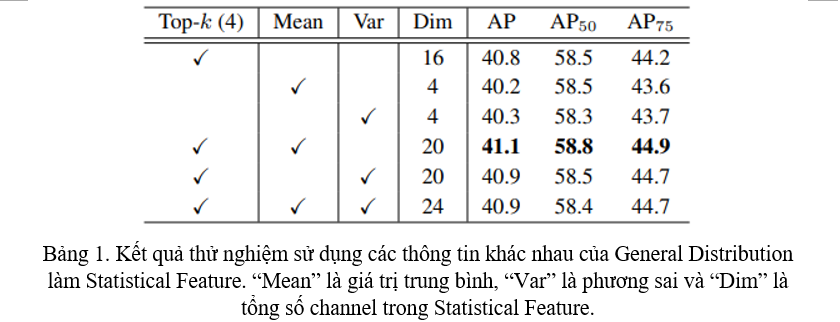
Ngoài top- giá trị, một phân phối còn có thể cho ta thông tin về trung bình và phương sai. Vì vậy, tác giả đã thực hiện thử nghiệm với các thông tin nói trên, từ riêng lẻ đến kết hợp và nhận thấy sử dụng thông tin kết hợp của top- và trung bình đạt kết quả tốt nhất (Bảng 1).
Kiến trúc của DGQP
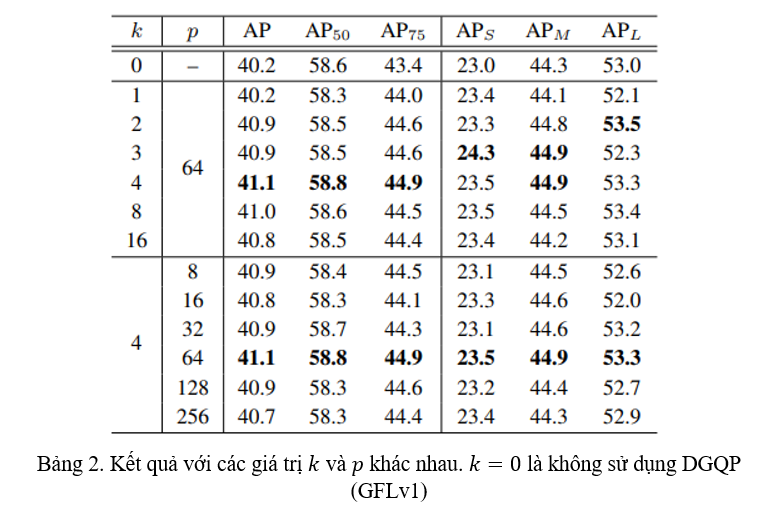
Nhóm tác giả thử nghiệm các tham số khác nhau cho mạng nơ-ron con như tham số trong top- và số hidden units trong hidden layer. Thử nghiệm cho thấy với và ta thu được kết quả tốt nhất (Bảng 2).
Loại thông tin đưa vào DGQP
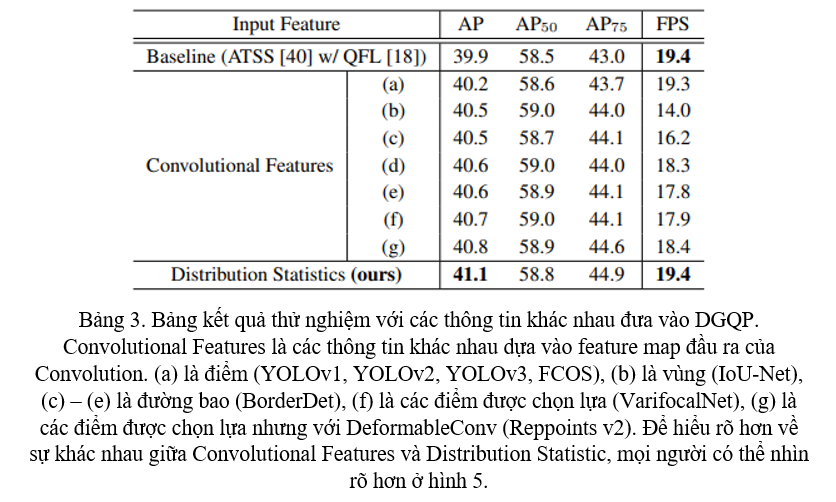
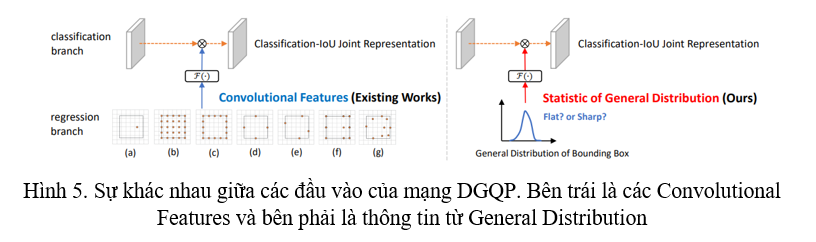
Nhóm tác giả muốn chứng minh rằng việc sử dụng thông tin từ phân phối của sự biểu diễn Bounding Box tốt hơn so với Convolution feature. Nhóm tác giả giữ nguyên kiến trúc DGQP và lựa chọn các loại thông tin khác nhau đưa vào DGQP, kết quả thử nghiệm cho thấy việc sử dụng thông tin từ phân phối biểu diễn Bounding Box không chỉ tốt hơn mà còn nhanh hơn (Bảng 3).
Phân tích DGQP
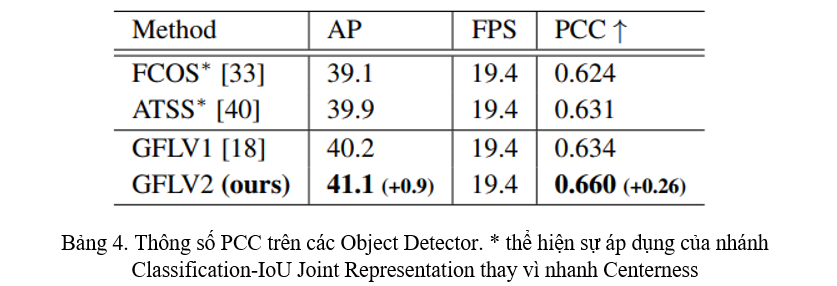
- Để chứng minh DGQP giúp ích trong quá trình tính toán Localization Quality, nhóm tác giả tính Pearson Correlation Coefficient (PCC) của IoU dự đoán và ground-truth IoU. Kết quả cho thấy rằng DGQP làm tăng sự tương quan giữa IoU dự đoán và ground-truth IoU (Bảng 4).
![image.png]()
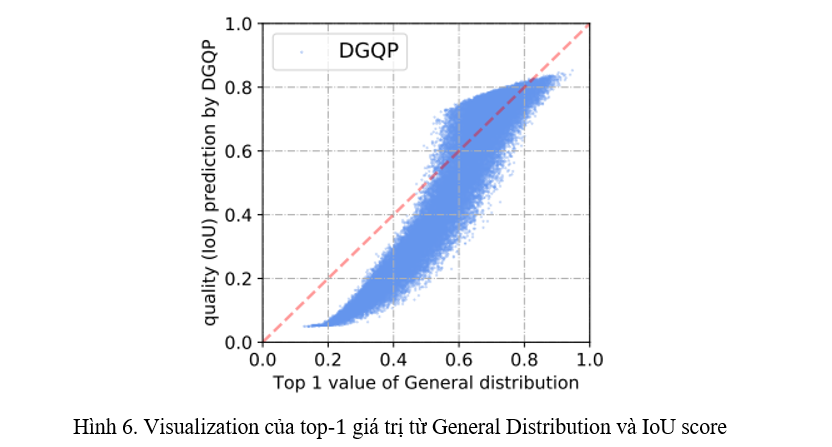
- GFLv2 được hình thành từ ý tưởng thông tin từ General Distribution có tương quan với IoU (Hình 1). DGQP còn cho ra kết quả có tính tương quan cao hơn nữa (Hình 6).
![image.png]()