Đặt vấn đề
Pretraining trên các tập dữ liệu cho bài toán phân loại (e.g ImageNet) để khởi tạo model cho Object detection là hướng đi khá thông dụng bởi model có thể học được các đặc trưng có lợi từ tập dữ liệu lớn giúp hội tụ tốt hơn trong quá trình fine-tuning. Mặc dù vậy, gánh nặng tạo ra từ độ lớn của dataset là không thể bỏ qua, nó khiến cho quá trình training từ đầu trở nên chậm hơn và có thể sẽ cần nhiều vòng lặp hơn để đạt được kết quả mang tính đột phá. Từ đó các tác giả đề xuất phương pháp pretrain mới - Montage pretraining và chỉ dựa trên các tập dữ liệu của bài toán detection. Khi so sánh với hướng ImageNet pre-training, Montage pre-training chỉ tốn chi phí tính toán để đạt được kết quả tương tự thậm chí là tốt hơn cho bài toán object detection.
Montage pre-training được xây dựng dựa trên ý tưởng: thông thường một lượng lớn pixel đưa qua model trong quá trình training không mang nhiều thông tin hữu ích, hầu hết pixel/neuron ở vùng background thường không mang lại gradient trong quá trình học, hơn thế nữa chúng còn dẫn đến lãng phí tài nguyên tính toán. Để giải quyết vấn đề này, tác giả trích các mẫu positive và negative từ ảnh gốc của detection dataset để pre-train. Trước khi đưa vào mạng backbone, các mẫu nói trên sẽ được gộp thành một ảnh mới theo phương pháp montage với tỷ lệ đã cho trước để đảm bảo tính đặc thù về không gian. Đồng thời các tác giả cũng đề xuất chiến lược training ERF - adaptive dense classification sử dụng Effective Receptive field để gán nhãn soft label nhằm cải thiện đặc trưng ở cấp độ pixel.
Montage pretrain
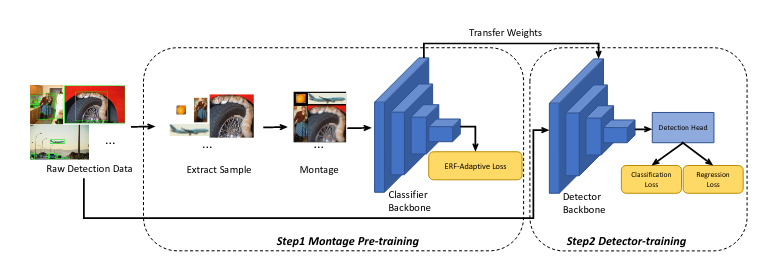
Đầu tiên, , nhóm tác giả trích xuất ra các mẫu positive và negative từ bộ dataset detection để dựng dataset classification cho task pre-training. Quá trình training được thực hiện theo chiến lược Montage, 4 đối tượng sẽ được gộp chung vào 1 ảnh để đưa vào backbone và tối ưu hóa qua ERF - adaptive loss. Cuối cùng backbone sẽ được fine-tune cho detection task.
Sample Selection
Các mẫu positive là những vùng thuộc một trong những class có trong detection dataset, trong khi đó mẫu negative thường là vùng chỉ chứa background. Để lấy mẫu đa dạng và hiệu quả, người ta đưa ra một số quy luật cho quá trình trích xuất mẫu:
- Positive : trích xuất những vùng của ảnh gốc dựa theo ground-truth bounding boxes. Bounding box sẽ được mở rộng một cách ngẫu nhiên để lấy được nhiều thông tin ngữ cảnh hơn với giả thuyết rằng những thông tin mang tính ngữ cảnh là quan trọng để mô hình học được các đặc trưng biểu diễn tốt hơn.
- Negative: được lấy mẫu ngẫu nhiên từ các vùng background với , trong đó Iou là độ đo Intersection-over-Union
Montage Assembly
Quá trình lấy mẫu nói trên có vẻ khá hợp lý nhưng việc ép tất cả mẫu về một kích thước sẽ phá hủy thông tin về kết cấu và làm sai lệch hình dạng ban đầu, trong khi padding để giữ tỷ lệ kích thước thì tạo nhiều khoảng không có giá trị cũng như lãng phí tài nguyên tính toán.

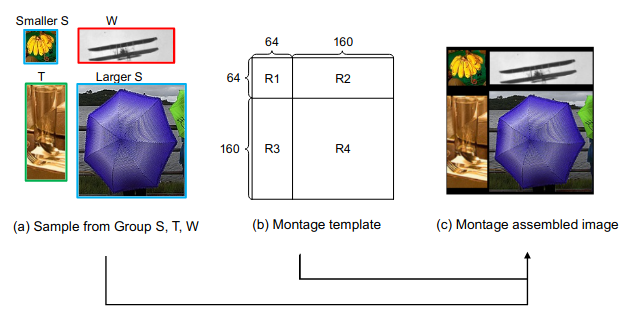
Các đối tượng thường khác nhau về tỷ lệ kích thước, do đó Montage assembly xem xét đặc tính này để các mẫu có thể được ghép lại với nhau một cách tự nhiên hơn theo tỷ lệ khung hình của chúng. Vì vậy, trước tiên, các mẫu sẽ được chia thành ba Nhóm theo tỷ lệ khung hình của chúng, tức là Nhóm S (hình vuông), T (cao) và W (rộng). Các mẫu trong Nhóm S phải có tỷ lệ khung hình từ 0,5 đến 1,5, trong khi các mẫu trong Nhóm T và W tương ứng phải có tỷ lệ khung hình nhỏ hơn 0,5 và lớn hơn 1,5. Để đơn giản, các mẫu thuộc Nhóm S, T và W được gọi là mẫu S, mẫu T và mẫu W.
Effective Receptive Fields
Một trong những khái niệm cơ bản trong mạng CNN là vùng tiếp nhận của một đơn vị trong một lớp của mạng. Không giống như các lớp fully connected để tính toán một đơn vị cần toàn bộ đầu vào, một đơn vị của lớp tích chập chỉ phụ thuộc vào một vùng nhỏ. Các tác giả đã khám phá ra rằng không phải toàn bộ pixel trong vùng tiếp nhận đều đóng góp như nhau cho đầu ra của một đơn vị, dễ nhận thấy rằng những pixel ở trung tâm của vùng tiếp nhận có ảnh hưởng lớn hơn đến đầu ra so với số khác ở vùng rìa. Trong quá trình forward, các pixel ở trung tâm có thể lan truyền thông tin đến đầu ra qua nhiều hướng khác nhau, trong khi pixel ở vùng rìa thì ít hơn. Với backward, gradients từ một đơn vị đầu ra được lan truyền đến toàn bộ các hướng và do đó thì những pixel ở trung tâm cũng có cường độ ảnh hướng lớn hơn cho gradient từ đầu ra đấy.
Trong bài , các tác giả muốn mô tả toán học về mức độ mà mỗi pixel đầu vào trong một trường tiếp nhận có thể tác động đến kết quả đầu ra của một mạng lớp, với . Giả sử các pixel ở mỗi lớp được đánh số với tâm ở . Nếu coi một pixel ở lớp thứ là thì là đầu vào của mạng, và là đầu ra ở lớp thứ , điều chúng ta cần tìm là mỗi đóng góp bao nhiêu vào . Effective receptive field của một đơn vị đầu ra có thể coi là vùng chứa các pixel đầu vào với ảnh hưởng không đáng kể tới nó. Người ta dùng đạo hàm riêng để tính toán sự ảnh hưởng đó thông qua quá trình lan truyền ngược trong mạng. Giả sử là hàm loss bất kỳ, với quy tắc đạo hàm của hàm hợp ta có thể viết . Nếu and và , thì .
ERF-adaptive Dense Classification
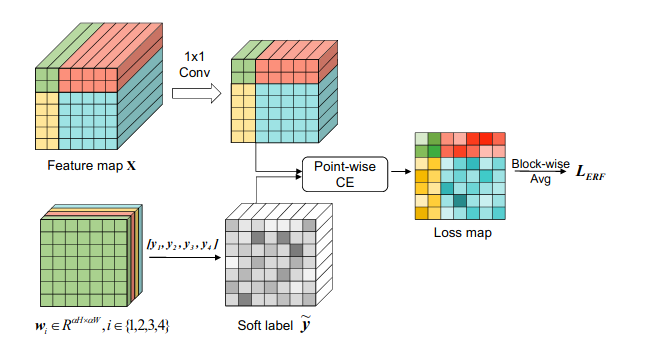
Pipeline cơ bản : Feature map được nhân tích chập x để giảm số chiều xuống chiều. Nhân trọng số với nhãn , chúng ta sẽ có soft label cho mỗi điểm. Sau đó áp dụng hàm mất mát cross-entropy cho mỗi điểm tại feature map ta sẽ được loss map như trong hình. Cùng lúc đó, mất mát theo trọng số tại 1 vị trí cũng sẽ được tính toán dựa vào tại vị trí đó. Sau đó, ta tính average theo từng vị trí block xanh lá - đỏ - vàng - xanh lam để lấy average loss cho từng vùng. Hàm loss -adaptive cuối cùng chính là trung bình của loss ở cả 4 vùng.
Với 4 vùng trong đầu vào Montage như hình 3b, ta gọi là nhãn gốc cho vùng ,
Tại vị trí () của feature map , , soft label chính là tổng trọng số của 4 nhãn:
Trong đó trọng số phụ thuộc vào của nó. Tại vị trí của feature map , , ta sẽ tính toán tương ứng tại đầu vào. Nếu vị trí nằm trong vùng , ta sẽ phải đặt ngưỡng để đảm bảo rằng là chủ đạo tại đấy. Do đó tại vị trí tại vùng , ta sẽ tính được trọng số của nhãn như sau :
Trong đó là phần tử tại vị trí của ma trận tương ứng, là giá trị tại vị trí của binary mask , binary mask sẽ được dùng để lựa chọn vùng trong .
Gọi là đặc trưng tại vị trí của feature map , , sau khi tính toán được trọng số , tác giả tiến hành bước dense classification trên đặc trưng để có soft label .
Kết quả thí nghiệm
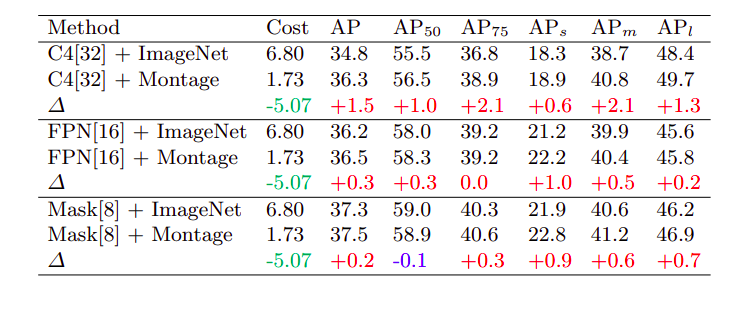
Kết quả cho thấy việc áp dụng montage đã giúp cho các mô hình cũ cải thiện được đáng kể độ chính xác. Vì đây là phương pháp Data Augmentation kết hợp chiến lược training nên việc áp dụng có thể đối với bất kì kiến trúc mạng nào. Chúng ta có thể xem xét kết quả thí nghiệm trong hình sau khi so sánh giữa ImageNet pretraining và Montage pretraining:
Kết luận
Montage là phương pháp đơn giản nhưng khá hiệu quả với object detection khi giảm hao phí xuống khi so sánh với ImageNet pretraining nhưng vẫn đạt được kết quả ngang bằng thậm chí cao hơn. Phương pháp làm giảm chi phí tính toán giúp tạo điều kiện cho việc training from scratch dễ dàng hơn. mình đánh giá bài báo này đã có những khám phá mới giúp chúng ta có những hướng đi mới trong việc pretraining model và hiểu hơn về các yếu tố xung quanh việc huấn luyện mạng.