Kết thúc chuỗi sersie về hệ phân tán là phần 7: Tính chịu lỗi (part 2). Mọi người có thể xem lại part 1 tại đây. Phần này mình sẽ nói tiếp về 3 mục cuối của bài
Mục lục
- Giới thiệu tính chịu lỗi
- Khả năng phục hồi tiến trình
- Truyền thông client-server đáng tin cậy
- Truyền thông nhóm đáng tin cậy
- Cam kết phân tán
- Phục hồi
4. Truyền thông nhóm đáng tin cậy
- Truyền thông nhóm tin cậy phải có cơ chế để đảm bảo thông điệp đó đến được tất cả các thành viên trong nhóm.
- Nếu xảy ra lỗi thì sử dụng số tuần tự các thông điệp để khắc phục.
- Các thông điệp được lưu tại một vùng đệm của bên gửi cho đến khi nhận được bản tin xác nhận từ tất cả các thành viên trong nhóm.
- Nếu bên nhận xác định bị mất một thông điệp nào đó, nó sẽ yêu cầu gửi lại.
- Note: Thông thường, bên gửi sẽ tự động gửi lại thông điệp sau trong khoảng thời gian xác định trước nếu không nhận được thông điệp xác nhận.
4.1. Truyền thông nhóm đáng tin cậy cơ bản
- Bên gửi sẽ chuyển thông điệp đến tất cả các thành viên trong nhóm và từng thành viên có trách nhiệm phản hồi kết quả đã nhận được thành công hay không.
- Nếu có lỗi xảy ra thì áp dụng cơ chế sửa lỗi như truyền thông điểm – điểm.
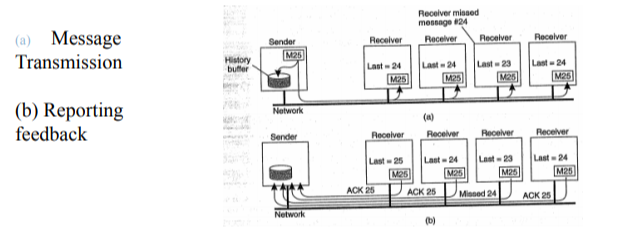
Như vậy, nếu một tiến trình nào đó trong nhóm yêu cầu gửi lại thì tất cả các thành viên khác đều nhận lại thông điệp mặc dù trước đó đã nhận thành công và bên gửi phải tiếp nhận phản hồi của tất cả các tiến trình trong nhóm.
4.2. Truyền thông nhóm đáng tin cậy trong các hệ thống lớn
Mô hình này hoạt động tương tự như nguyên lý của giao thức SRM (Scalable Reliable Multicasting) để tăng hiệu năng khi làm việc với nhóm có số lượng lớn các tiến trình
- Không trả về thông điệp xác nhận thành công mà chỉ trả về thông điệp NACK thông báo khi có lỗi truyền.
- Để thực hiện truyền thông nhóm đáng tin cậy cho số lượng lớn các tiến trình cần tổ chức nhóm theo cấu trúc dạng cây.
- Gốc là nhóm chứa tiến trình gửi.
- Các nút là nhóm chứa tiến trình nhận.
- Việc chia thành các nhóm nhỏ hơn cho phép sử dụng các kịch bản truyền thông nhóm đáng tin cậy cho từng nhóm, mỗi nhóm nhỏ sẽ đề cử một tiến trình đóng vai trò điều phối.
- Tiến trình điều phối có khả năng điều khiển việc truyền lại khi nhận được thông báo truyền lỗi.
- Tiến trình điều phối của mỗi nhóm sẽ có bộ đệm riêng, nếu không nhận được thông điệp thì nó sẽ gửi yêu cầu truyền lại tới tiến trình điều phối cấp cao hơn.
- Nếu tiến trình điều phối của một nhóm nhận được thông điệp xác nhận thành công việc chuyển thông điệp của tất cả các tiến trình trong nhóm gửi về thì nó sẽ xóa thông điệp khỏi bộ đệm của nó.
- Phương pháp phân cấp nảy sinh vấn đề xây dựng cấu trúc cây, có trường hợp yêu cầu cây phải có cấu trúc động do đó cần có một cơ chế tìm đường cho cây.
- Khi một tiến trình muốn gửi thông điệp cho một tập các tiến trình khác theo dạng nhóm, nó sẽ không gửi thông điệp tới tất cả các tiến trình của nhóm mà chỉ gửi đến một nhóm nhỏ các tiến trình cần nhận thông điệp đó.
- Vấn đề đặt ra là phải đảm bảo gửi được thông điệp tới tất cả các tiến trình trong nhóm hoặc không được gửi tới bất kì tiến trình nào nếu một tiến trình trong nhóm bị lỗi.
Truyền tin nhóm đáng tin cậy cơ bản có hiệu năng thấp đối với các hệ thống lớn.
- Giả sử phải gửi thông điệp đến N thành viên, khi đó bên gửi sẽ nhận ít nhất N phản hồi từ các thành viên trong nhóm.
- Giải pháp cải tiến: bên nhận không cần phải gửi phản hồi cho tất cả các thông điệp mà chỉ thông báo những thông điệp còn thiếu. Do đó bên gửi phải lưu toàn bộ các thông điệp đã gửi.
- Để giảm thiểu số lượng phản hồi từ bên nhận người ta áp dụng hai giải pháp: phản hồi không phân cấp và phản hồi có phân cấp.
Phản hồi không phân cấp
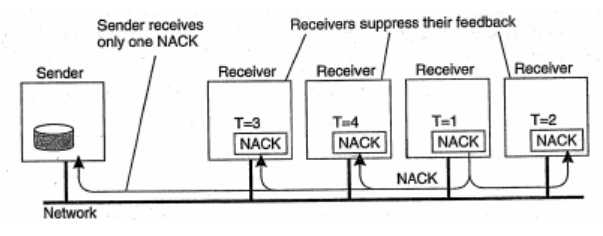
- Giảm số lượng phản hồi đến bên gửi bằng cách sử dụng giao thức SRM (Scalable Reliable Multicasting).
- Bên nhận không phản hồi thông điệp ACK để xác nhận đã nhận thành công.
- Nếu phát hiện thiếu thông điệp phản hồi cho bên gửi và toàn bộ thành viên trong nhóm thông điệp NACK (chưa nhận được thông điệp hoặc thông điệp bị lỗi).
- Để giảm số lượng phản hồi NACK, giao thức dùng phương pháp tự triệt tiêu thông điệp NACK.
- Ví dụ: nếu một thành viên định phản hồi NACK, nó sẽ chờ một thời gian nhất định. Nếu không nhận được NACK tương ứng với thông điệp đó thì mới gửi các thành viên khác trong nhóm và bên gửi.
- Giao thức này đảm bảo chỉ gửi lại một thông điệp bị mất phụ thuộc vào việc lập lịch thông điệp phản hồi tại mỗi trạm nhận, nếu không cùng một thời điểm sẽ có nhiều trạm nhận gửi thông điệp NACK.
- Bắt buộc thành viên trong nhóm đều phải nhận thông điệp NACK ngay cả khi không cần thiết vì việc thiết lập thời gian trên toàn nhóm không hề dễ.
- Cách khắc phục vấn đề này: có thể tạo thêm một nhóm mới phục vụ cho thông điệp NACK, các thành viên trong nhóm hỗ trợ nhau phục hồi những thông điệp bị mất trước khi chuyển thông điệp NACK cho bên gửi.
Phản hồi có phân cấp
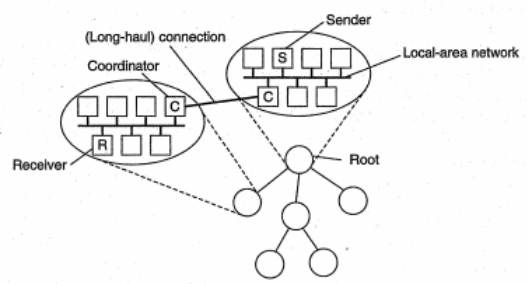
- Được tổ chức với các nhóm nhỏ hơn theo cấu trúc hình cây.
- Trong đó: root là nhóm chứa tiến trình gửi và các nút là các nhóm có chứa tiến trình nhận.
- Mỗi nhóm bầu chọn tiến trình điều phối có nhiệm vụ xử lý các yêu cầu truyền lại.
- Tiến trình điều phối của mỗi nhóm sẽ có bộ đệm riêng, nếu không nhận được thông điệp thì sẽ gửi yêu cầu truyền lại tới tiến trình điều phối của nút cha.
- Đối với các thành viên trong nhóm có thể sử dụng kịch bản truyền nhóm cơ bản hoặc phản hồi không phân cấp.
- Việc xây dựng cấu trúc cây khá phức tạp, nhiều trường hợp yêu cầu cây phải có cấu trúc động => cần một cơ chế tìm đường.
5. Cam kết phân tán
- Cam kết phân tán là việc đảm bảo tính nguyên tử.
- Các lệnh trong giao tác phải được thực thi thành công trên tất cả các thành viên trong nhóm, nếu có bất kỳ thành viên nào thực hiện không thành công thì các thành viên khác cũng phải hủy bỏ giao tác.
5.1. Two-Phase Commit - 2PC (Giao thức cam kết hai pha)
Xét một giao tác phân tán với các thành viên là một tập các tiến trình chạy ở một máy khác và không có lỗi xảy ra. Giao thức bao gồm hai phase:
- Phase 1:
- Tiến trình điều phối gửi một thông điệp cầu biểu quyết VOTE_REQUEST tới tất cả các thành viên trong nhóm.
- Sau khi nhận được thông điệp VOTE_REQUEST:
- Nếu có thể thực hiện được, thành viên đó sẽ gửi lại cho tiến trình điều phối thông báo chấp nhận biểu quyết VOTE_COMMIT
- Nếu không sẽ gửi lại thông báo từ chối VOTE_ABORT.
- Phase 2:
- Tiến trình điều phối tập hợp tất cả các biểu quyết của các thành viên.
- Nếu tất cả đều chấp nhận giao dịch nó sẽ gửi một thông điệp GLOBAL_COMMIT tới tất cả các thành viên. Chỉ cần một thành viên gửi thông báo từ chối thì tiến trình điều phối quyết định hủy giao dịch trên và sẽ gửi một thông điệp GLOBAL_ABORT cho tất cả các thành viên trong nhóm.
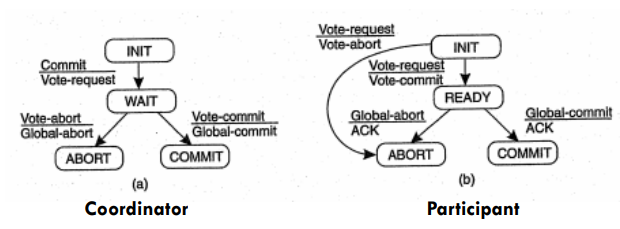
- Các thành viên sau khi đã gửi thông báo chấp nhận cam kết sẽ đợi phản hồi từ tiến trình điều phối.
- Nếu nhận được thông báo GLOBAL_COMMIT thì giao tác sẽ được chấp thuận, còn nếu nhận được GLOBAL_ABORT thì giao tác sẽ bị hủy bỏ.
- Giao thức khẳng định hai pha đảm bảo tính nguyên tử và phục hồi độc lập.
- Nhược điểm: tốn nhiều thời gian chờ đợi, cả tiến trình điều phối lẫn các thành viên còn lại đều phải chờ một thông điệp nào đó được gửi đến, nếu tiến trình điều phối bị lỗi thì hoạt động của cả hệ thống sẽ bị ảnh hưởng => ảnh hưởng đến hiệu năng hệ thống
5.2. Three-Phase Commit (Giao thức cam kết ba pha)
- Giao thức cam kết ba pha ra đời để khắc phục nhược điểm của cam kết hai pha trong trường hợp tiến trình điều phối bị lỗi.
- Các trạng thái trong cam kết ba pha khá giống cam kết hai pha nhưng thêm một trạng thái tiền khẳng định PRECOMMIT.
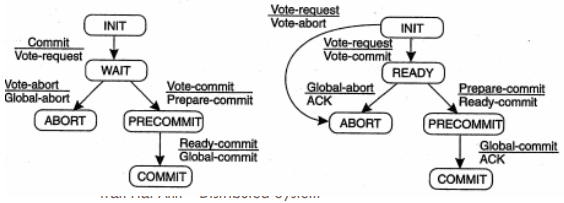
- Giao thức cam kết ba pha gồm nhiều tiến trình trong đó có một tiến trình đóng vai trò điều phối.
- Nguyên tắc của giao thức:
- Không có một trạng thái đơn lẻ nào mà từ đó có thể chuyển trực tiếp sang trạng thái khẳng định hoặc hủy bỏ.
- Không có trạng thái mà trong đó không thể đưa ra quyết định cuối cùng và từ đó có thể chuyển sang trạng thái khẳng định.
Nguyên tắc trên là điều kiện cần thiết và đủ để đảm bảo giao thức cam kết ba pha có thể hoạt động trong chế độ không phong tỏa.
-
Thành phần điều phối bắt đầu bằng việc gửi thông điệp yêu cầu bỏ phiếu (Vote-Request) đến tất cả các thành viên khác và chờ phản hồi.
-
Chỉ cần một tiến trình bỏ phiếu hủy bỏ (ABORT) hoặc một tiến trình thành viên nào đó không phản hồi thì quyết định cuối cùng sẽ là hủy bỏ. Khi đó tiến trình điều phối sẽ gửi thông điệp hủy bỏ toàn cục (Global Abort) đến tất cả các tiến trình thành viên.
-
Nếu tất cả các tiến trình thành viên đều phản hồi phiếu bầu đồng ý khẳng định, chắc chắn tất cả các tiến trình thành viên đã ở trạng thái sẵn sàng (READY). Tiến trình điều phối sẽ gửi thông điệp chuẩn bị khẳng định (Prepare commit) đến tất cả các thành viên.
- Nếu tại thời điểm này tiến trình điều phối bị lỗi thì sẽ không có một thông điệp nào đươc gửi đến các tiến trình thành viên.
- Sau một thời gian nhất định từng tiến trình thành viên sẽ không được phép hủy bỏ hay khẳng định giao tác.
- Mỗi thành viên đều áp dụng nguyên tắc đầu tiên nên chúng phải tham khảo trạng thái của các thành viên khác. Tất cả đều ở trạng thái quá hạn chờ thông điệp chuẩn bị khẳng định => giao tác sẽ tự động bị hủy.
-
Nhận được thông điệp chuẩn bị khẳng định từ tiến trình điều phối, các tiến trình thành viên sẽ phản hồi.
-
Sau khi nhận được phản hồi, tiến trình điều phối sẽ gửi thông điệp khẳng định toàn cục (Global commit), nhận được thông điệp này các tiến trình thành viên sẽ thực hiện khẳng định giao tác => giao tác phân tán hoàn thành.
-
Trong trường hợp, nếu tiến trình thành viên ở trạng thái READY và quá thời gian quy định mà vẫn không nhận được thông điệp chuẩn bị khẳng định, nó sẽ liên lạc với tiến trình thành viên khác.
- Nếu trạng thái của tiến trình thành viên được hỏi là ABORT, nó sẽ hủy bỏ giao tác.
- Nếu trạng thái là PRECOMMIT thì sẽ chuyển trạng thái của nó giống như thành viên đã hỏi.
- Nếu trạng thái là COMMIT thì sẽ thực hiện khẳng định giao tác.
-
Trường hợp nếu thành viên ở trạng thái PRECOMMIT và quá thời gian quy định mà vẫn không nhận được thông điệp khẳng định toàn cục, nó sẽ liên lạc với tiến trình thành viên khác.
- Nếu trạng thái của tiến trình thành viên được hỏi là COMMIT thì nó thực hiện khẳng định giao tác.
- Nếu tất cả các tiến trình thành viên đều ở trạng thái PRECOMMIT thì nó cũng thực hiện khẳng định giao tác.
6. Phục hồi
Lỗi có thể xảy ra ở bất kỳ thời điểm nào, một hệ thống đáng tin cậy phải không những có khả năng phát hiện lỗi mà còn phải biết phục hồi sau khi gặp lỗi.
6.1. Các biện pháp phục hồi
Có hai cách phục hồi lỗi: phục hồi lùi (backward) và phục hồi tiến (forward)
- Backward recovery
- Đưa hệ thống từ trạng thái lỗi ở thời điểm hiện tại về trạng thái không lỗi ở thời điểm trước khi xảy ra lỗi.
- Cách thực hiện: liên tục ghi lại trạng thái của hệ thống và khi hệ thống gặp lỗi sẽ chuyển về trạng thái đã sao lưu, thời điểm hệ thống thực hiện sao lưu dữ liệu và trạng thái gọi là điểm kiểm tra (checkpoint).
- Sử dụng rộng rãi như một cơ chế tổng quát về phục hồi lỗi trong các hệ thống phân tán.
- Ưu điểm: Tính độc lập với các tiến trình => có thể tích hợp vào tầng trung gian của hệ thống phân tán như một dịch vụ đa năng.
- Nhược điểm:
- Việc phục hồi hệ thống về trạng thái trước đòi hỏi chi phí tương đối lớn về hiệu năng => giải pháp: khởi động lại các thành phần.
- Cơ chế phục hồi lùi độc lập với các ứng dụng phân tán => không có gì đảm bảo sau khi phục hồi, lỗi tương tự lại không lặp lại => có thể xảy ra vòng lặp phục hồi.
- Thực hiện điểm kiểm tra làm suy giảm đáng kể hiệu năng của hệ thống
- Forward recovery
- Không đưa hệ thống trở lại trạng thái không lỗi trước khi xảy ra lỗi mà chuyển hệ thống sang trạng thái mới không lỗi để có thể tiếp tục hoạt động.
- Khó khăn của giải pháp này là phải biết trước những lỗi nào có thể xảy ra, chỉ khi đó mới có thể sửa lỗi và chuyển sang trạng thái mới.
6.2. Checkpointing ( Điểm kiểm tra)
- Phục hồi lùi đòi hỏi hệ thống phải đều đặn ghi lại trạng thái của nó vào vùng nhớ vĩnh cửu. Đặc biệt phải ghi được trạng thái toàn cục nhất quán gọi là bản sao phân tán (snapshot).
- Trong bản sao phân tán, nếu một tiến trình nào đó ghi nhật ký nhận được bản tin thì chắc chắn tiến trình gửi cũng sẽ phải ghi nhật ký gửi bản tin đó. Nếu có lỗi xảy ra thì các tiến trình này biết được sẽ phải bắt đầu từ đâu để phục hồi hệ thống.
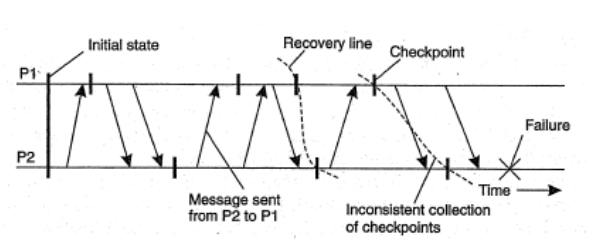
Independent Checkpointing (Điểm kiểm tra độc lập)
- Việc thực hiện điểm kiểm tra mang tính chất cục bộ.
- Mỗi tiến trình đều đặn ghi trạng thái cục bộ của theo cách riêng biệt, gây khó khăn cho việc xác định đường phục hồi.
- Để tìm ra đường phục hồi, mỗi tiến trình sẽ phải quay lui về trạng thái gần nhất đã đươc ghi lại.
- Nếu các trạng thái cục bộ này không tạo nên được đường phục hồi thì tiếp tục phải quay lui về trạng thái trước nữa.
- Quá trình phục hồi phân tầng này có thể dẫn đến hiện tượng dây chuyền.
 Nhìn hình trên, ta thấy:
Nhìn hình trên, ta thấy:
- Khi tiến trình P2 gặp lỗi cần phải phục hồi trạng thái của nó về điểm kiểm tra gần nhất.
- Tiến trình P1 cũng sẽ phải quay lui về trạng thái của điểm kiểm tra gần nhất.
- Tuy nhiên hai trạng thái gần nhất được lưu cục bộ này lại không hình thành trạng thái toàn cục nhất quán.
- Tiến trình P2 ghi nhật ký đã nhận được thông điệp m nhưng nhật ký của tiến trình P1 lại không ghi nhận đã gửi thông điệp m.
- Như vậy tiến trình P2 phải quay lui về trạng thái trước nữa, nhưng ở trạng thái này lại không ghi nhận đã gửi thông điệp m' trong khi nhật ký của tiến trình P1 cho thấy đã nhận được thông điệp m'.
- Tiến trình P1 lại quay lui về trạng thái trước nữa.
- Cứ như vậy cả hai tiến trình phải quay lui về trạng thái ban đầu mới tìm thấy đường phục hồi.
Nhược điểm:
- Đòi hỏi có sự đồng bộ trên tất cả các tiến trình => làm suy giảm hiệu năng hệ thống.
- Gặp vấn đề về xác định đường phục hồi.
6.3. Message Logging (Ghi nhật ký thông điệp)
- Ghi nhật ký thông điệp làm giảm số lần thực hiện điểm kiểm tra nhưng vẫn phải đảm bảo khả năng phục hồi.
- Ý tưởng của kỹ thuật này: nếu thông điệp được gửi lại thì có thể đạt được trạng thái nhất quán toàn cục mà không cần phục hồi về trạng thái lấy từ bộ nhớ ổn định.
- Giải pháp: lấy từ điểm khởi đầu và tất cả các thông điệp từ điểm khởi đầu đó sẽ được gửi lại và xử lý phù hợp.
- Giả thiết: dựa trên mô hình xác định từng phần.
- Việc thực thi của mỗi tiến trình là một chuỗi các khoảng sự kiện.
- Khoảng sự kiện bắt đầu từ thời điểm xảy ra sự kiện không xác định và kết thúc tại thời điểm của sự kiện cuối cùng trước khi xảy ra sự kiện không xác định kế tiếp.
- Nếu thực hiện lại các khoảng sự kiện này sẽ được kết quả tương ứng với kết quả của những sự kiện không xác định.
- Như vậy việc ghi lại tất cả các sự kiện không xác định chuyển thành có thể lặp lại lại toàn bộ những thực thi của tiến trình theo cách xác định.
- Alvisi & Marzullo đã mô tả nhiều lược đồ ghi nhật ký thông điệp:
- Mỗi thông điệp chứa thông tin điều khiển để có thể được gửi lại và xử lý chính xác.
- Thông tin điều khiển xác định bên gửi và bên nhận, số tuần tự để tránh trùng lặp, số thứ tự phân phát để quyết định chính xác khi nào sẽ được xử lý ở bên nhận.
- Một thông điệp được coi là ổn định nếu nó không bị thất lạc trên kênh truyền vì nó sẽ được ghi vào bộ nhớ ổn định. Những thông điệp đó sẽ được sử dụng để gửi lại khi cần thực hiện phục hồi.
- Khi một tiến trình bị sụp đổ, tiến trình đó sẽ phải được phục hồi. Ngay cả khi phục hồi thành công cũng có thể dẫn tới hiện tượng tiến trình mồ côi, đó là những tiến trình sống sót sau sự sụp đổ của tiến trình khác nhưng trạng thái của nó không nhất quán với tiến trình sụp đổ và đã được phục hồi.
- Thông điệp đặc trưng - Các lược đồ ghi nhật ký:
- Mỗi thông điệp m dẫn tới tập DEP(m) các tiến trình phụ thuộc vào sự phân phát thông điệp m.
- Nếu một thông điệp m’ phụ thuộc nhân quả với thông điệp m và thông điệp m’ được phân phát đến bất kỳ tiến trình nào thì tiến trình đó cũng sẽ là thành viên của tập DEP(m).
- Thông điệp m’ phụ thuộc nhân quả vào m nếu nó được gửi bởi một tiến trình trước đó đã phân phát thông điệp m hoặc m’ thuộc tiến trình đã phân phát thông điệp khác nhưng thông điệp đó phụ thuộc nhân quả vào thông điệp m.
- Tập COPY(m) gồm các tiến trình nhận được bản sao thông điệp m nhưng chưa kịp ghi vào vùng nhớ ổn định.
- Khi một tiến trình chuyển tiếp thông điệp m thì nó cũng là thành viên của COPY(m).
- Nếu tất cả các tiến trình này sụp đổ thì việc phát lại thông điệp m sẽ không thể thực hiện được.
- Tiến trình mồ côi xuất hiện khi nó phụ thuộc vào thông điệp nhưng không có cách nào phát lại thông điệp đó.
- Để tránh hiện tượng tiến trình mồ côi cần phải chắc chắn rằng mỗi tiến trình trong tập COPY(m) sụp đổ thì không ở trong tập DEP(m) của tiến trình sống sót, nghĩa là tất cả các tiến trình trong DEP(m) cũng phải bị sụp đổ.
- Điều kiện này có thể được thực hiện nếu đảm bảo rằng mọi tiến trình là thành viên của DEP(m) thì cũng là thành viên của COPY(m).
- Có thể giải quyết vấn đề tiến trình mồ côi bằng cách sử dụng giao thức ghi nhật ký bi quan hoặc lạc quan.
- Giao thức bi quan đảm bảo rằng mỗi thông điệp chưa ổn định thì chỉ có nhiều nhất một tiến trình phụ thuộc vào nó. Như vậy tiến trình sẽ chỉ được phép gửi thông điệp khi tất cả các thông điệp đã được ghi vào bộ nhớ ổn định (tiến trình đã thuộc tập COPY(m)).
- Giao thức lạc quan thì ngược lại, công việc thực tế được thực hiện sau khi xảy ra sụp đổ. Tiến trình mồ côi trong tập DEP(m) sẽ quay lui cho đến khi không thuộc tập này nữa.
- Trong 2 giao thức trên có thể thấy cách tiếp cận bi quan đơn giản hơn cách tiếp cận lạc quan rất nhiều, do đó trong thực tế người ta thường sử dụng cách tiếp cận bi quan.
Đến đây cũng là kết thúc bài của phần Tính chịu lỗi cũng như kết thúc về chuỗi sersie về hệ phân tán cơ bản. Đây cũng chỉ là những kiến thức cơ bản trong hệ phân tán chứ không có nâng cao gì nên rất mong mọi người đọc có thể hiểu được
Thanks for reading
Tài liệu tham khảo: Bài giảng Hệ phân tán - ĐHBKHN

