Theo dòng thời gian, cuộc sống thay đổi, con người thay đổi. Mới bài trước còn khen Tacotron, Tacotron2 nhưng hôm nay lai khen hết lời bộ đôi anh em nhà Fast Speech. Nhưng quả thật anh em nhà Fast Speech được giới thiệu thông qua hai bài báo FastSpeech: Fast, Robust and Controllable Text to Speech và FastSpeech 2: Fast and High-Quality End-to-End Text to Speech đã đem lại những hiệu quả nổi bật so với các kiến trúc trước đó.
Trước khi vào chủ đề chính về kiến trúc Fast Speech, ta cùng điểm lại các mô hình kiến trúc đại diện cho quá trình phát triển của hệ thống Text to Speech đến ngày hôm nay.
I. Một số kiến trúc Text to Speech trước đó
Text to Speech là một trong các bài toán Speech Synthesis . Speech synthesis là bài toán sinh ra các tệp audio từ văn bản, chuyển động môi, ... Tuy nhiên, hầu hết trong các ứng dụng hiện nay, sinh âm thanh từ văn bản hay text to speech vẫn là bài toán thông dụng nhất vì khả năng ứng dụng và tính gẫn gũi của ngôn ngữ với con người.
Do đó đã có rất nhiều công trình nghiên cứu về chủ đề này, chúng ta có thể kể đến những mô hình tôi đề cập dưới đây:
1. Sinh ghép nối ( Concatenation synthesis )
Nghe qua tên gọi, không biết các bạn đã hình dung ra được phương pháp này chưa ? Phương pháp này sinh ra âm thanh dựa trên việc ghép nối các đoạn âm thanh nhỏ được ghi âm trước ở mức âm, mức từ hay mức câu. Các đoạn âm thanh nhỏ này được gọi là pre-recorded speech segments. Chúng thường được lưu trữ ở dạng waveform hoặc spectrogram.
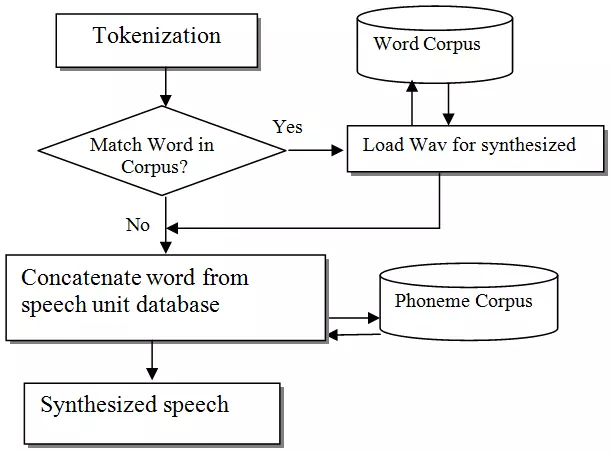 Mô hình sinh ở mức từ. Nguồn: internet
Mô hình sinh ở mức từ. Nguồn: internet
2. Statistical Parametric Synthesis
Phương pháp này cũng sử dụng âm thanh được ghi âm sẵn giống phương pháp bên trên. Điểm khác biệt là Statistical Parametric Synthesis sử dụng hàm và một tập các tham số nữa để điều chỉnh giọng nói.
2.1. Tổng quan
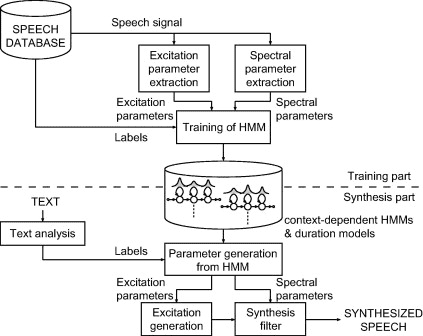 Statistical parametric speech synthesis. Nguồn: https://theaisummer.com/text-to-speech/
Statistical parametric speech synthesis. Nguồn: https://theaisummer.com/text-to-speech/
Phương pháp này gồm có hai quá trình:
- Quá trình huấn luyện
- Quá trình sinh âm thanh
Quá trình huấn luyện: Trích xuất một tập hợp các tham số đặc trưng âm thanh của mẫu audio như: tần số spectrum , tần số cơ bản, duration. Sau đó chúng ta sử dụng một mô hình thống kê như Hidden Markov Model để dự đoán các tham số này sẽ tương ứng với text đầu vào như thế nào
Quá trình sinh âm thanh: HMM dư đoán các tham số đặc trưng của audio dựa trên text đầu vào. Bộ tham số này dùng để sinh waveform.
2.2. Ưu và nhược điểm.
Một số ưu điểm so với phương pháp 1:
- Không cần lưu trữ audio ở database trong quá trình sinh
- Đặc trưng âm thanh đôc lập với đặc trưng về ngôn ngữ
- Có thể linh hoạt, đa dạng trong giọng đọc
Nhược điểm:
- Chất lượng âm thanh sinh ra chưa tốt
3. Deep learning model
Do phương pháp truyền thống chưa thực sự sinh ra được những âm thanh lý tưởng do đó các nhà nghiên cứu ứng dụng các thành tựu của deep learning giải quyết bài toán này. Mình tạm chia các mô hình mình sẽ giới thiệu trong khuôn khổ bài viết thành 2 phân khúc:
- Autogressive model
- Non Autogressive model
3.1. Autogressive model
Autogressive model với đại diện tiêu biểu là kiến trúc Tacotron được giới thiệu bởi Google vào năm 2017 ở bài báo TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS đánh dấu thành công ứng dụng deep learning vào trong bài toán Text to Speech.
3.1.1. Tổng quan
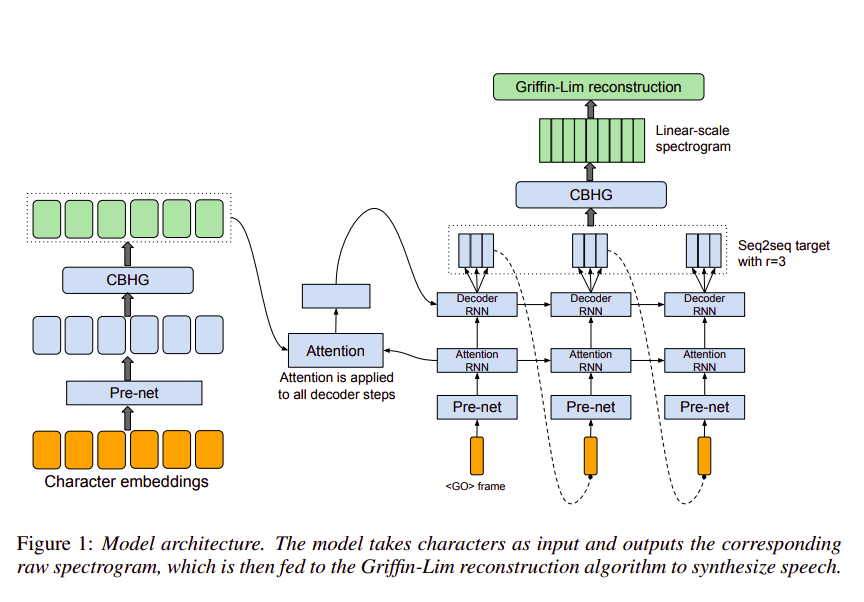
Tacotron là mô hình end-to-end được xây dựng trên kiến trúc seq2seq nhận đầu vào là text và sinh ra spectrogram / mel spectrogram. Sau đó mô hình vocoder sẽ sử dụng chính những spectrogram/mel spectrogram này để sinh ra audio. Với tacotron, chúng ta không cần sử dụng alignment ở mức phone hay phải lưu trữ các đoạn âm thanh ghi âm sẫn do đó có thể dễ dàng sinh với số lượng lớn chỉ cần tăng số lượng văn bản đầu vào.
Tacotron đã đạt điểm số 3.82 mean opinion score (MOS) trên tập US English, kết quả vượt trội so với các phương pháp truyên thống. Các bạn muốn tìm hiểu sâu hơn về mô hình Tacotron thì có thể đọc qua hai bài trước đó của mình.
3.1.2. Ưu và nhược điểm
Ưu điểm:
- Chất lượng âm thanh sinh ra tốt hơn nhiều so với phương pháp truyền thống
- Dễ dàng scale với số lượng lớn.
Nhược điểm:
- Tốc độ sinh mel-spectrogram / spectrogram chậm do kiến trúc tuần tự của mô hình seq2seq
- Âm thanh sinh ra gặp các hiện tượng như một số từ bị bỏ qua hoặc lặp lại do lỗi trong quá trình truyền thông tin hoặc alignment attention bị sai giữa text và speech.
- Âm thanh sinh ra không thể điều khiển được các đặc trưng như duration, ngắt nghỉ
3.2. Non-Autogressive model
Đại diện cho các mô hình Non Autogressive có thể được nhắc đến là bộ đôi anh em nhà Fast Speech. Một điều mình nhận ra được rằng nhược điểm của cái cũ chính là lý do cho cái mới xuất hiện. Và quả thật như vậy các nhược điểm của Tacotron đã được giải quyết trong mô hình Fast Speech.
3.2.1. Tổng quan
Fast speech để giải quyết các vấn đề của Tacotron thông qua ba modules:
- Feed-Forward Transformer
- Lengh Regulator
- Duration Predict
- Sử dụng biểu diễn trung gian ở mức phone
Từng đặc điểm này sẽ được mình giới thiệu chi tiết hơn trong bài viết sắp tới.
3.2.2. Ưu và nhược điểm.
Ưu điểm
- Fast: So với tacotron2, Fast Speech sinh mel spectrogram nhanh gấp 270 lần và sinh giọng nói nhanh hơn 38 lần
- Robust: Tránh được các lỗi lặp hay bị bỏ qua từ do hạn chế được wrong attention alignment giữa text và speech.
- Cotrollable: Có thể điều khiển tốc độ cũng như ngắt nghỉ dựa trên cơ chế length regulator
- High quality: Chất lượng âm thanh tương đương với các mô hình autorgressive như tacotron.
Nhược điểm:
- Việc sử dụng hard alignment ở mức phone thay cho soft alignment như ở mô hình attention based sequence-to-sequence sẽ khiến âm thanh thiếu tính tự nhiên hơn
Tạm kết
Chúng ta đã cùng nhìn lại một số mô hình để thấy những ưu và nhược điểm của Fast Speech. Trong các bài viết tiếp theo, chúng ta sẽ đi phân tích sâu hơn về kiến trúc mô hình để hiểu rõ hơn. Cảm ơn các bạn đã theo dõi bài viết.