Thông qua bài viết này, bạn sẽ có đủ kiến thức để có thể tự xây dựng công cụ phân tích mã tĩnh C# cho riêng bạn. Bạn thấy hứng thú không nào. Bắt đầu nhé!
Công cụ phân tích mã tĩnh là gì? Chúng ta có thực sự cần nó hay không?
Trong quá trình xây dựng phần mềm, tôi dám chắc rằng nhiều lập trình viên sẽ gặp các lỗi cơ bản và để lại nhiều lỗ hổng tiềm ẩn trong mã nguồn mà có thể gây nên nhiều hậu quả nghiêm trọng. Để giải quyết vấn đề đó, chúng ta có các công cụ tự động phát hiện những lỗi, lỗ hổng trong mã nguồn. Công cụ này gọi là công cụ phân tích mã tĩnh (static analyzer).
Tuy nhiên, điều gì sẽ xảy ra nếu như những công cụ này chưa thể phát hiện những lỗi, lỗ hổng mà bạn biết chúng tồn tại trong mã nguồn của mình, và tất nhiên bạn không muốn mắc phải nó một lần nữa. Câu trả lời rất đơn giản, bạn sẽ tự tạo công cụ cho riêng mình. Một thứ rất hữu ích cho việc xây dựng trình phân tích tĩnh đó là Roslyn. Và Roslyn là thứ ta sẽ bàn luận trong bài viết này.
Giới thiệu về Roslyn
Roslyn là một nền tảng mã nguồn mở, được phát triển bởi Microsoft, chứa các trình biên dịch và công cụ để phân tích cú pháp và phân tích mã nguồn được viết bằng C # và Visual Basic.
Roslyn được sử dụng trong môi trường Microsoft Visual Studio 2015 trở đi. Sử dụng các công cụ phân tích do Roslyn cung cấp, ta có thể phân tích cú pháp mã nguồn, phân tích tất cả các cấu trúc ngôn ngữ được hỗ trợ.
Môi trường Visual Studio cho phép tạo các công cụ được nhúng trong chính IDE (Visual Studio extensions), cũng như các ứng dụng độc lập (standalone tools).
Bắt đầu với Roslyn
Vì trình phân tích mã nguồn chúng ta xây dựng dựa trên Roslyn, nên cần cài đặt .NET Compiler Platform SDK for Visual Studio. Một trong những cách để làm như vậy là mở Visual Studio Installer và chọn Visual Studio extension development trong tab Workloads.
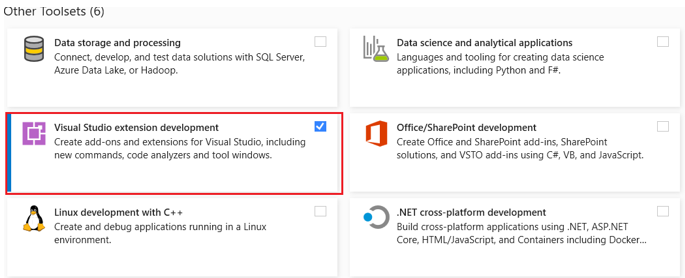
Sau khi cài đặt bộ công cụ cần thiết, ta có thể bắt đầu tạo bộ phân tích.
Tạo bộ phân tích dựa trên Visual Studio templates
Sau khi cài đặt những thứ cần thiết như đã nói ở trên, chúng ta mở Visual Studio, click vào Create a new project, chúng ta để ý sẽ thấy có 2 template thú vị, đó là Analyzer with Code Fix (.NET Standard và Standalone Code Analysis Tool
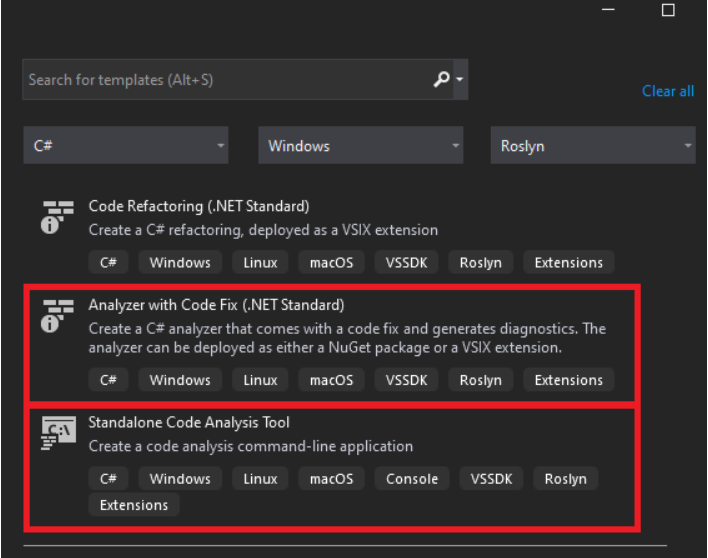
Hãy cùng tìm hiểu thêm về 2 template này.
Analyzer with Code Fix (.NET Standard)
Sau khi tạo project mới với Analyzer with Code Fix (.NET Standard) ta sẽ được cây thư mục như sau:
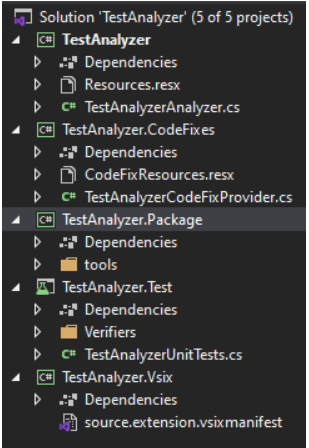
Đầu tiên hãy mở tệp TestAnalyzerAnalyzer.cs. Nó đã chứa một ví dụ đơn giản về rule cho bộ phân tích. Rule này sẽ tìm kiếm tất cả tên lớp trong source code. NẾu tên của một class có các kí tự viết thường, nó sẽ được gạch dưới bàng một đường lượn sóng. Bên cạnh đó, nó cung cấp tính năng tự động sửa tên class và chuyển hết tất cả kí tự thành chữ hoa.
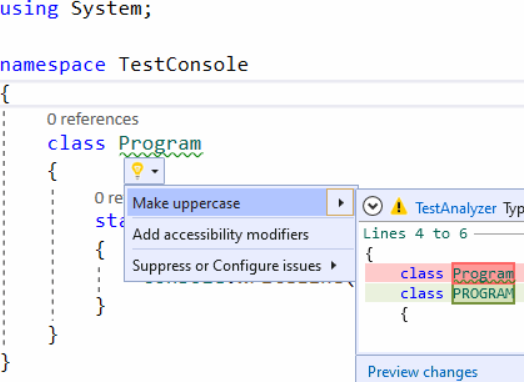
Về cơ bản thì đúng như tên gọi. Template này cung cấp cho bạn khả năng tìm lỗi và sửa lỗi. Template này sẽ phù hợp khi bạn muốn nhìn thấy các gợi ý, sửa lỗi ngay khi bạn đang viết code.
Standalone Code Analysis Tool
Sau khi tạo project mới với Standalone Code Analysis Tool ta sẽ nhận được project như sau:
Về cơ bản, đây sẽ là một console application với tất cả các DLLs cần thiết cho việc phân tích như:
- Microsoft.CodeAnalysis.CSharp.Analyzers.dll;
- Microsoft.CodeAnalysis.Analyzers.dll;
- Microsoft.CodeAnalysis.Workspaces.MSBuild.dll;
- etc....
Nếu bạn muốn sử dụng trình phân tích như một ứng dụng chạy độc lập thì đây sẽ là lựa chọn dành cho bạn.
Tìm hiểu về Roslyn API
Trước khi chúng ta có thể tự xây dựng một công cụ phân tích tĩnh, ta cần hiểu rõ một số điểm và cách dùng của roslyn.
Syntax Trees
Syntax trees theo nghĩa đen là một cấu trúc dữ liệu dạng cây. Mỗi cây cú pháp được tạo thành từ các nodes, tokens và trivia (cụ thể sẽ được trình bày ở các phần sau).
Để có cái nhìn tổng quan và dễ hiểu hơn về syntax trees chúng ta sẽ xem xét cấu trúc của syntax trees được biểu diễn bằng Visual Studio bằng cách truy cập vào View -> Other Windows -> Syntax Visualizer . Và kết quả là hình bên dưới.

Đây là một công cụ rất hữu ích đặc biệt hữu ích cho những người mới bắt đầu với cấu trúc cây và các loại phần tử được đại diện trong đó. Khi di chuyển qua code trong Visual Studio, Syntax Visualizer đi đến phần tử cây tương ứng của đoạn code và đánh dấu nó. Cửa sổ Syntax Visualizer cũng hiển thị một số thuộc tính cho phần tử đang được chọn.
Để dễ hình dung hơn, ta có thể chọn một phần tử trong cửa sổ Syntax Visualizer và gọi menu ngữ cảnh của phần tử này. Kết quả là ta nhận được một cửa sổ hiển thị cây cú pháp được xây dựng cho phần tử đã chọn:
Ví dụ với đoạn code như sau thì syntax tree được xây dựng sẽ có dạng như dưới đây
if (number > 0)
{
}
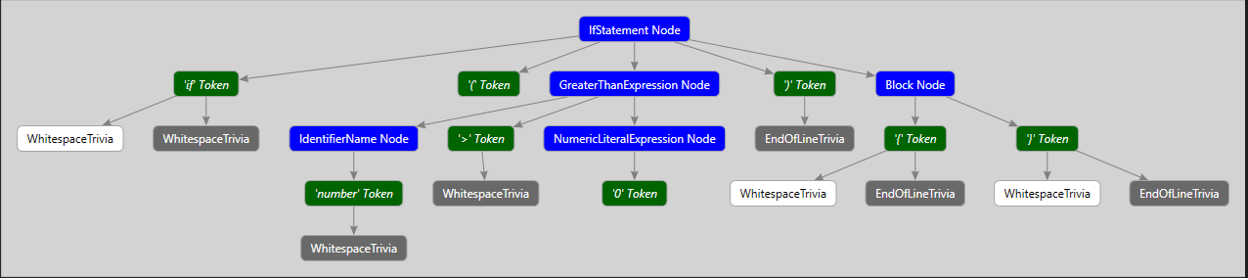
Hình này cho thấy cây bao gồm các phần tử được biểu thị bằng bốn màu. Chúng ta có thể chia tất cả các phần tử cây thành ba nhóm:
- Màu xanh dương - syntax nodes;
- Màu xanh lá cây - syntax tokens;
- Trắng và xám – syntax trivia. Nó chứa thông tin cú pháp bổ sung.
Chúng ta hãy xem xét kỹ hơn từng nhóm.
Syntax Nodes
Syntax nodes đại diện cho các cấu trúc cú pháp như: khai báo, toán tử, biểu thức, v.v. Đối với một công cụ phân tích source code, công việc chính của nó là xử lý các node này. Mỗi nút đại diện cho một cấu trúc ngôn ngữ cụ thể đều có một kiểu, được kế thừa từ lớp trừu tượng SyntaxNode. Nó xác định một số thuộc tính giúp đơn giản hóa việc làm việc với cây. Dưới đây là một số kiểu cùng với cấu trúc ngôn ngữ tương ứng của chúng:
IfStatementSyntax- câu lệnh if;InvocationExpressionSyntax- lệnh gọi phương thức;ReturnStatementSyntax- toán tử trả về;MemberAccessExpressionSyntax- truy cập vào các thành viên class/structure- etc....
Ví dụ, lớp IfStatementSyntax có một chức năng được kế thừa từ lớp SyntaxNode và có các thuộc tính hữu ích khác, chẳng hạn như Condition, Statement và Else. Nút Condition đại diện cho điều kiện của toán tử; nút Statement đại diện cho phần thân của câu lệnh if; và nút Else đại diện cho khối else.
Lớp trừu tượng SyntaxNode cung cấp cho chúng ta các phương thức chung cho tất cả các nút. Một số trong số chúng được liệt kê dưới đây:
ChildNodestrả về một chuỗi các nút là con của nút hiện tại.DescendantNodestrả về một chuỗi tất cả các nút con cháu.Containsxác định xem nút, được truyền dưới dạng đối số, có phải là con của nút hiện tại hay không.IsKindnhận phần tử liệt kêSyntaxKindlàm tham số và trả về giá trị boolean. Có thể gọiIsKindcho một nút cây. Phương thức này kiểm tra xem loại nút đã truyền vào có khớp với loại nút màIsKindđược gọi từ đó không.
Bên cạnh đó, một số thuộc tính được định nghĩa trong lớp. Một trong những cách được sử dụng phổ biến nhất trong số đó là Parent, chứa một tham chiếu đến nút cha của nút hiện tại.
Syntax Token
Syntax token biểu diễn cho các đoạn nhỏ nhất (không thể phân tách thành các phần nhỏ hơn) của code như định danh, từ khóa, ký tự đặc biệt. Khi phân tích source code, chúng ta hầu như không làm việc với token, thay vào đó chúng ta sử dụng token để lấy ra biểu diễn văn bản của chúng hoặc để kiểm tra token type. Syntax token là các nút lá của syntax tree, chúng không có các nút con. Bên cạnh đó, tokens là các thể hiện của cấu trúc SyntaxToken.
Các thuộc tính chính của cấu trúc SyntaxToken là:
RawKind- một biểu diễn số của phần tử liệt kêSyntaxKindcủa token;Value- biểu diễn đối tượng của token. Ví dụ: nếu một token biểu diễn cho một ký tự số có kiểu int, thì Value trả về một đối tượng có kiểu int với một giá trị tương ứng.Text– biểu diễn dạng văn bản của một token.- etc...
Syntax trivia
Syntax trivia (thông tin bổ sung về cú pháp) bao gồm các phần tử của cây như sau: comment, chỉ thị tiền xử lý, các phần tử định dạng khác nhau (dấu cách, ký tự xuống dòng). Các nút cây này không phải là con cháu của lớp SyntaxNode. Syntax trivia không có trong mã IL (không ảnh hưởng đến quá trình biên dịch). Tuy nhiên, chúng vẫn được biểu diễn trong syntax tree. Syntax trivia luôn thuộc về một token. Có 2 loại trivia đó là leading trivia và trailing trivia. Leading trivia là thông tin cú pháp bổ sung đứng trước một token. Trailing trivia là thông tin cú pháp bổ sung theo sau một token. Tất cả các phần tử của thông tin cú pháp bổ sung đều thuộc kiểu SyntaxTrivia. Nếu muốn xác định chính xác phần tử là gì, có thể sử dụng kiểu liệt kê SyntaxKind cùng với các phương thức Kind và IsKind.
CsharpSyntaxWalker
Lớp trừu tượng CSharpSyntaxWalker cho phép chúng ta xây dựng syntax walker của riêng mình có thể truy cập tất cả các node, token và trivia. Chúng ta chỉ cần kế thừa từ lớp CSharpSyntaxWalker và ghi đè phương thức Visit() để truy cập tất cả các nút trong cây. Đây sẽ là lớp rất quan trọng đối với chúng ta khi muốn xây dựng một trình phân tích mã tĩnh.
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DOTNETScanner
{
class CustomWalker : CSharpSyntaxWalker
{
static int Tabs = 0;
public override void Visit(SyntaxNode node)
{
Tabs++;
var indents = new String('\t', Tabs);
Console.WriteLine(indents + node.Kind());
base.Visit(node);
Tabs--;
}
static void Main()
{
var tree = CSharpSyntaxTree.ParseText(@"
public class MyClass
{
public void MyMethod()
{
}
public void MyMethod(int n)
{
}
");
var walker = new CustomWalker();
walker.Visit(tree.GetRoot());
}
}
}
Đoạn code trên chứa một triển khai của lớp CSharpSyntaxWalker được gọi là CustomWalker. CustomWalker ghi đè phương thức Visit() và in loại nút hiện đang được truy cập. Điều quan trọng cần lưu ý là CustomWalker.Visit() có gọi phương thức base.Visit (SyntaxNode). Điều này cho phép CSharpSyntaxWalker duyệt qua tất cả các nút con của nút hiện tại.
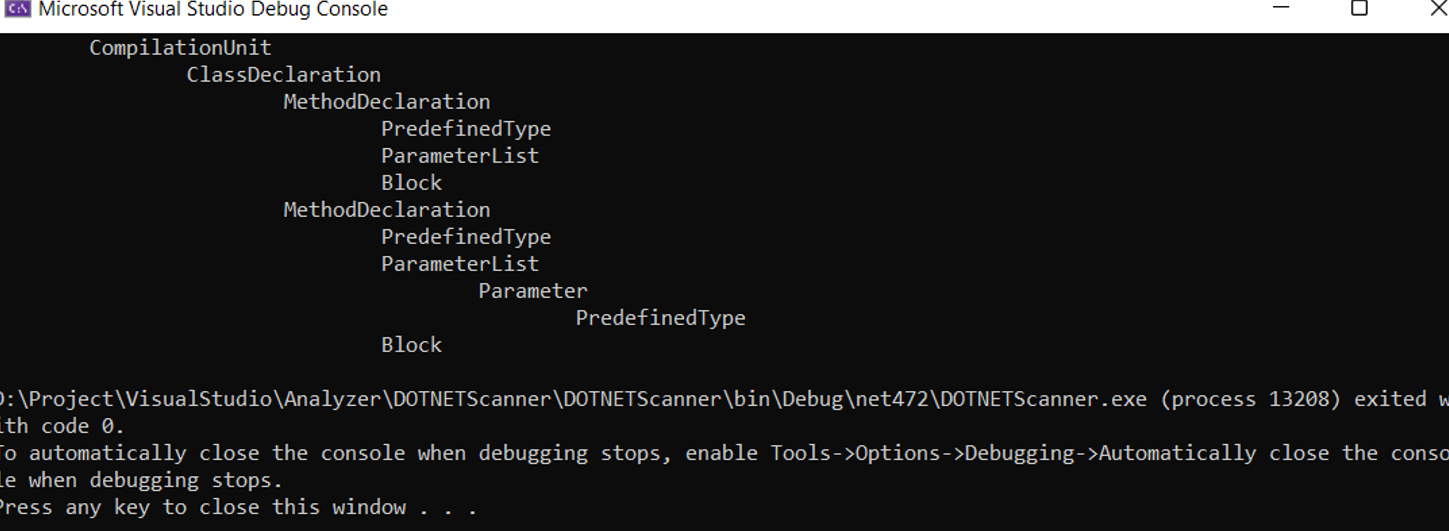
Chúng ta có thể thấy rõ ràng các nút khác nhau của cây cú pháp và mối quan hệ của chúng với nhau. Có hai MethodDeclarations có cùng nút cha là ClassDeclaration.
Ví dụ trên chỉ truy cập các nút của cây cú pháp, nhưng ta có thể sửa đổi CustomWalker để truy cập các token và trivia. Lớp trừu tượng CSharpSyntaxWalker có một constructor cho phép chúng ta chỉ định độ sâu mà chúng ta muốn truy cập.
Chúng ta có thể sửa đổi đoạn code trên để in ra các nút và token tương ứng của chúng ở mỗi độ sâu của cây cú pháp.
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DOTNETScanner
{
public class DeeperWalker : CSharpSyntaxWalker
{
static int Tabs = 0;
//NOTE: Make sure you invoke the base constructor with
//the correct SyntaxWalkerDepth. Otherwise VisitToken()
//will never get run.
public DeeperWalker() : base(SyntaxWalkerDepth.Token)
{
}
public override void Visit(SyntaxNode node)
{
Tabs++;
var indents = new String('\t', Tabs);
Console.WriteLine(indents + node.Kind());
base.Visit(node);
Tabs--;
}
public override void VisitToken(SyntaxToken token)
{
var indents = new String('\t', Tabs);
Console.WriteLine(indents + token);
base.VisitToken(token);
}
static void Main(string[] args)
{
var tree = CSharpSyntaxTree.ParseText(@"
public class MyClass
{
public void MyMethod()
{
}
public void MyMethod(int n)
{
}
");
var walker = new DeeperWalker();
walker.Visit(tree.GetRoot());
}
}
}
Kết quả đầu ra khi ta sử dụng CSharpSyntaxWalker này:
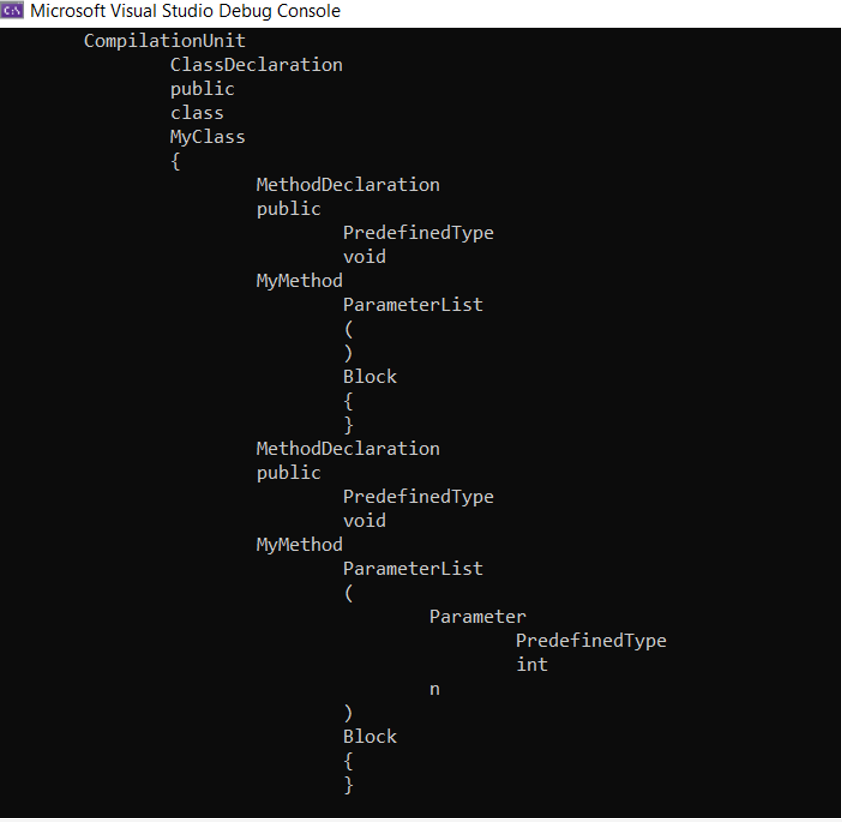
Hai đoạn code trên có cùng một cây cú pháp. Đầu ra chứa các nút cú pháp giống nhau, nhưng ta đã thêm các syntax token tương ứng cho mỗi nút. Trong các ví dụ trên, ta đã truy cập tất cả các nút và tất cả các token trong một cây cú pháp. Tuy nhiên, đôi khi ta chỉ muốn truy cập vào một số nút nhất định, nhưng theo thứ tự được xác định trước mà CSharpSyntaxWalker cung cấp. Roslyn API cho phép chúng ta lọc các nút mà chúng ta muốn truy cập dựa trên cú pháp của chúng.
Thay vì truy cập tất cả các nút như ta đã làm trong các đoạn code trước, đoạn code sau chỉ truy cập vào các nút ClassDeclarationSyntax và MethodDeclarationSyntax.
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DOTNETScanner
{
public class ClassMethodWalker : CSharpSyntaxWalker
{
string className = String.Empty;
public override void VisitClassDeclaration(ClassDeclarationSyntax node)
{
className = node.Identifier.ToString();
base.VisitClassDeclaration(node);
}
public override void VisitMethodDeclaration(MethodDeclarationSyntax node)
{
string methodName = node.Identifier.ToString();
Console.WriteLine(className + '.' + methodName);
base.VisitMethodDeclaration(node);
}
static void Main(string[] args)
{
var tree = CSharpSyntaxTree.ParseText(@"
public class MyClass
{
public void MyMethod()
{
}
}
public class MyOtherClass
{
public void MyMethod(int n)
{
}
}
");
var walker = new ClassMethodWalker();
walker.Visit(tree.GetRoot());
}
}
}
Và kết quả như sau:
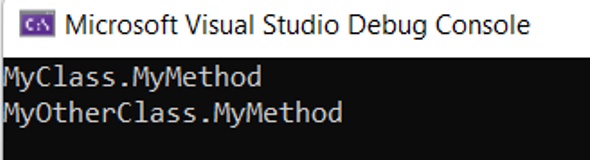
Làm việc với Workspaces
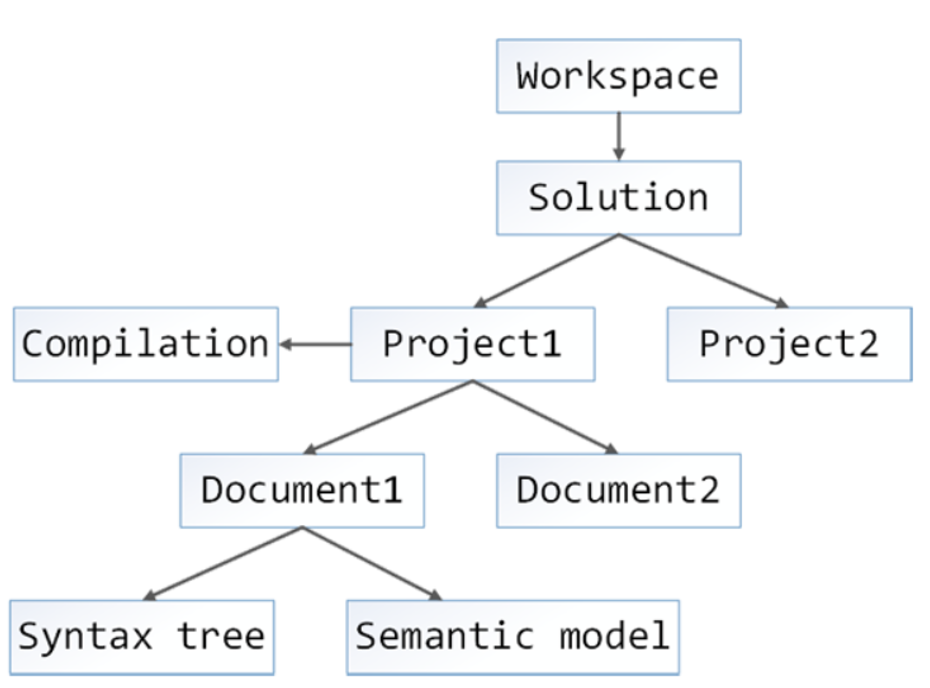
Cho đến thời điểm này, ta chỉ đơn giản là xây dựng cây cú pháp từ các văn bản mã nguồn (các chuỗi chứa mã nguồn). Phương pháp này hoạt động tốt khi tạo các ví dụ ngắn, nhưng ta thường muốn làm việc với toàn bộ các solution. Đây là lúc chúng ta cần đến workspaces. Workspaces là nút gốc của hệ thống phân cấp C # bao gồm một solution, các dự án con (child project) và các tài liệu con (child document). Có bốn biến thể của workspace cần xem xét:
Workspace
Lớp trừu tượng cơ sở cho tất cả các workspace khác.Lớp này đóng vai trò như một loại API mà xung quanh đó có thể tạo các triển khai workspace thực tế.
MSBuildWorkspace
Một workspace đã được xây dựng để xử lý các tệp MSBuild solution(.sln) và dự án (.csproj, .vbproj). Ví dụ sau cho thấy có thể đọc tất cả các document trong một solution:
public static void Main(string[] args)
{
string solutionPath = @"C:\Users\…\PathToSolution\MySolution.sln";
var msWorkspace = MSBuildWorkspace.Create();
var solution = msWorkspace.OpenSolutionAsync(solutionPath).Result;
foreach (var project in solution.Projects)
{
foreach (var document in project.Documents)
{
Console.WriteLine(project.Name + "\t\t\t" + document.Name);
}
}
}
AdhocWorkspace
Workspace này cho phép ta thêm solution và tệp project theo cách thủ công. Cần lưu ý rằng API để thêm và xóa các mục solution trong AdhocWorkspace là khác nhau khi so sánh với các workspace khác. AdhocWorkspace được sử dụng bởi những người cần tạo workspace một cách nhanh chóng, dễ dàng và thêm các dự án và tài liệu vào đó.
var workspace = new AdhocWorkspace();
string projName = "NewProject";
var projectId = ProjectId.CreateNewId();
var versionStamp = VersionStamp.Create();
var projectInfo = ProjectInfo.Create(projectId, versionStamp, projName, projName, LanguageNames.CSharp);
var newProject = workspace.AddProject(projectInfo);
var sourceText = SourceText.From("class A {}");
var newDocument = workspace.AddDocument(newProject.Id, "NewFile.cs", sourceText);
foreach (var project in workspace.CurrentSolution.Projects)
{
foreach (var document in project.Documents)
{
Console.WriteLine(project.Name + "\t\t\t" + document.Name);
}
}
VisualStudioWorkspace
Workspace hoạt động được sử dụng trong các gói Visual Studio. Vì workstích hợp chặt chẽ với Visual Studio, nên rất khó để cung cấp một ví dụ nhỏ về cách sử dụng workspace này.
Khi viết VSPackages, một trong những phần chức năng hữu ích nhất mà workspace cung cấp là sự kiện WorkspaceChanged. Sự kiện này cho phép VSPackage phản hồi bất kỳ thay đổi nào do người dùng hoặc bất kỳ VSPackage nào khác thực hiện.
Giới thiệu về mô hình ngữ nghĩa (semantic model)
Cho đến thời điểm này, chúng ta đã làm việc với mã C # ở cấp độ cú pháp thuần túy. Chúng ta có thể tìm thấy các khai báo thuộc tính, nhưng chúng ta không thể theo dõi các tham chiếu đến thuộc tính này trong mã nguồn. Và điều này thực sự khó khăn nếu chúng ta muốn xây dựng một trình phân tích mã nguồn tốt.
Mô hình ngữ nghĩa của Roslyn có thể giải quyết các vấn đề mà chúng ta có thể gặp phải. Mô hình ngữ nghĩa cung cấp thông tin về các thực thể khác nhau: phương thức, biến cục bộ, trường, thuộc tính, v.v. Chúng ta cần biên dịch dự án của mình không có lỗi để có được mô hình ngữ nghĩa chính xác.
Có 3 cách khác nhau để yêu cầu mô hình ngữ nghĩa:
Document.GetSemanticModel()Compilation.GetSemanticModel(SyntaxTree)- Phân tích chẩn đoán khác nhau bao gồm
CodeBlockStartAnalysisContext.SemanticModelvàSemanticModelAnalysisContext.SemanticModel
Ta có thể yêu cầu mô hình ngữ nghĩa như sau:
var tree = CSharpSyntaxTree.ParseText(@"
public class MyClass
{
int MyMethod() { return 0; }
}");
var Mscorlib = MetadataReference.CreateFromFile(typeof(object).Assembly.Location);
var compilation = CSharpCompilation.Create("MyCompilation",
syntaxTrees: new[] { tree }, references: new[] { Mscorlib });
//Note that we must specify the tree for which we want the model.
//Each tree has its own semantic model
var model = compilation.GetSemanticModel(tree);
Symbols
Các chương trình C # bao gồm các phần tử duy nhất, chẳng hạn như kiểu, phương thức, thuộc tính, v.v. Symbols đại diện cho hầu hết mọi thứ mà trình biên dịch biết về mỗi phần tử duy nhất này. Ở cấp độ cao, mọi symbols đều chứa thông tin về:
- Nơi các phần tử này được khai báo trong mã nguồn hoặc siêu dữ liệu (Nó có thể đến từ một assembly bên ngoài)
- Namespace nào mà loại symbol này tồn tại bên trong
- ………..
Tất cả thông tin này được cung cấp thông qua interface ISymbol.
Các thông tin khác, phụ thuộc vào ngữ cảnh cũng có thể được khám phá. Khi xử lý các phương thức, IMethodSymbol cho phép chúng ta xác định:
- Phương thức có ẩn một phương thức cơ sở hay không.
- Symbol đại diện cho kiểu trả về của phương thức.
Chúng ta có thể chia symbol thành 2 nhóm:
- symbol để nhận thông tin về thực thể;
- symbol để nhận thông tin về kiểu của thực thể;
Hãy sử dụng tình huống sau đây làm ví dụ. Giả sử, để phân tích, ta cần xác định xem một phương thức được gọi có bị ghi đè hay không. Nói cách khác, ta cần xác định xem phương thức được gọi có được đánh dấu bởi công cụ sửa đổi là override trong khi khai báo hay không. Trong trường hợp này, chúng ta cần một symbol:
static void Main(string[] args)
{
string codeStr =
@"
using System;
public class ParentClass
{
virtual public void Mehtod1()
{
Console.WriteLine(""Hello from Parent"");
}
}
public class ChildClass: ParentClass
{
public override void Method1()
{
Console.WriteLine(""Hello from Child"");
}
}
class Program
{
static void Main(string[] args)
{
ChildClass childClass = new ChildClass();
childClass.Mehtod1();
}
}";
static SemanticModel GetSemanticModelFromCodeString(string codeString)
{
SyntaxTree tree = SyntaxFactory.ParseSyntaxTree(codeStr);
var msCorLibLocation = typeof(object).Assembly.Location;
var msCorLib = MetadataReference.CreateFromFile(msCorLibLocation);
var compilation = CSharpCompilation.Create("MyCompilation",
syntaxTrees: new[] { tree }, references: new[] { msCorLib });
return compilation.GetSemanticModel(tree);
}
var model = GetSemanticModelFromCodeString(codeStr);
var methodInvocSyntax = model.SyntaxTree.GetRoot()
.DescendantNodes()
.OfType<InvocationExpressionSyntax>();
foreach (var methodInvocation in methodInvocSyntax)
{
var methodSymbol = model.GetSymbolInfo(methodInvocation).Symbol;
if (methodSymbol.IsOverride)
{
//Apply your additional logic for analyzing method.
}
}
}
}
Phương thức GetSemanticModelFromCodeString phân tích cú pháp codeStr được truyền dưới dạng tham số codeString và nhận một cây cú pháp cho nó. Sau đó, một đối tượng của kiểu CSharpCompilation được tạo. Đối tượng này là kết quả của việc biên dịch một cây cú pháp, được lấy từ codeStr. Ta gọi phương thức CSharpCompilation.Create để chạy quá trình biên dịch. Một mảng cây cú pháp (mã nguồn được biên dịch) và các liên kết đến thư viện được chuyển đến phương thức này. Để biên dịch codeStr, ta chỉ cần tham chiếu đến thư viện lớp cơ sở C # - mscorlib.dll. Sau đó, một đối tượng mô hình ngữ nghĩa được trả về thông qua lời gọi phương thức CSharpCompilation.GetSemanticModel.
Một mô hình ngữ nghĩa được sử dụng để lấy cấu trúc SymbolInfo cho nút tương ứng với lời gọi phương thức. Chúng ta có đối tượng mô hình ngữ nghĩa được trả về bởi CSharpCompilation.GetSemanticModel. Phương thức GetSymbolInfo của đối tượng này được gọi, với nút được truyền cho nó dưới dạng một tham số. Sau khi chúng ta có được SymbolInfo, chúng ta gọi thuộc tính Symbol của nó. Thuộc tính này trả về đối tượng symbol, chứa thông tin ngữ nghĩa về nút được chuyển tới phương thức GetSymbolInfo. Khi chúng ta nhận được symbol, chúng ta có thể tham chiếu đến thuộc tính IsOverride của nó và xác định xem phương thức có bị ghi đè hay không.
Lấy thông tin đối tượng và chỉ định kiểu symbol
Ta có thể nhận được thông tin cụ thể hơn về một đối tượng bằng cách sử dụng các interface bao gồm IFieldSymbol, IPropertySymbol, IMethodSymbol và các interface khác. Nếu chúng ta ép kiểu đối tượng ISymbol sang một interface cụ thể hơn, chúng ta sẽ có quyền truy cập vào các thuộc tính dành riêng cho interface này.
Ví dụ: nếu chúng ta sử dụng ép kiểu cho IFieldSymbol, chúng ta có thể tham chiếu đến trường IsConst và tìm hiểu xem liệu nút có phải là trường hằng số hay không. Và nếu chúng ta sử dụng giao diện IMethodSymbol, chúng ta có thể tìm hiểu xem phương thức có trả về bất kỳ giá trị nào hay không.
Đối với các symbol, mô hình ngữ nghĩa xác định thuộc tính Kind, thuộc tính này trả về các phần tử của kiểu liệt kê SymbolKind. Với thuộc tính này, chúng ta có thể tìm hiểu những gì chúng ta hiện đang làm việc: một đối tượng cục bộ, một trường, một assembly, v.v. Ngoài ra, trong hầu hết các trường hợp, giá trị của thuộc tính Kind tương ứng với một loại symbol cụ thể. Tính năng chính xác này được sử dụng trong đoạn mã sau:
static void Main(string[] args)
{
string codeStr =
@"
public class MyClass
{
public string MyProperty { get; }
}
class Program
{
static void Main(string[] args)
{
MyClass myClass = new MyClass();
myClass.MyProperty;
}
}";
....
var model = GetSemanticModelFromCodeString(codeStr);
var propertyAccessSyntax = model.SyntaxTree.GetRoot().DescendantNodes()
.OfType<MemberAccessExpressionSyntax>()
.First();
var symbol = model.GetSymbolInfo(propertyAccessSyntax).Symbol;
if (symbol.Kind == SymbolKind.Property)
{
var pSymbol = (IPropertySymbol)symbol;
var isReadOnly = pSymbol.IsReadOnly; //true
var type = pSymbol.Type; // System.String
}
}
Sau khi chúng ta ép kiểu một symbol thành IPropertySymbol, chúng ta có thể truy cập các thuộc tính giúp lấy thêm thông tin. Một ví dụ đơn giản: MyProperty được truy cập trong cùng một tệp nguồn nơi khai báo của nó. Điều này có nghĩa là ta có thể lấy được thông tin rằng thuộc tính này không có setter, mà không cần sử dụng mô hình ngữ nghĩa. Nếu thuộc tính được khai báo trong một tệp hoặc thư viện khác, thì việc sử dụng mô hình ngữ nghĩa là không thể tránh khỏi.
Lấy thông tin về kiểu của đối tượng
Khi ta cần lấy thông tin về kiểu đối tượng cho một đối tượng được đại diện bởi một nút, ta có thể sử dụng giao diện ITypeSymbol. Để lấy nó, gọi ta cần phương thức GetTypeInfo cho một đối tượng thuộc kiểu SemanticModel. Phương thức này trả về cấu trúc TypeInfo, có chứa 2 thuộc tính quan trọng:
ConversionTypetrả về thông tin về kiểu của biểu thức sau khi trình biên dịch thực hiện một phép ép kiểu ngầm. Nếu không có ép kiểu nào, giá trị được trả về giống với giá trị được trả về bởi thuộc tínhType.Typetrả về kiểu của biểu thức được biểu diễn trong nút. Nếu không thể lấy kiểu của biểu thức, giá trị null được trả về. Nếu không thể xác định kiểu do một số lỗi, giao diệnIErrorTypeSymbolsẽ được trả về.
Dưới đây là một ví dụ về cách ta lấy kiểu của thuộc tính được gán giá trị:
static void Main(string[] args)
{
string codeStr =
@"
public class MyClass
{
public string MyProperty { get; set; }
public MyClass(string value)
{
MyProperty = value;
}
}";
....var model = GetSemanticModelFromCodeString(codeStr);
var assignmentExpr = model.SyntaxTree.GetRoot().DescendantNodes()
.OfType<AssignmentExpressionSyntax>()
.First();
ExpressionSyntax left = assignmentExpr.Left;
ITypeSymbol typeOfMyProperty = model.GetTypeInfo(left).Type;
}
Nếu ta sử dụng giao diện ITypeSymbol, được trả về bởi các thuộc tính này, ta có thể nhận được tất cả thông tin về kiểu cần thiết. Thông tin này được trích xuất bằng cách truy cập các thuộc tính, một số trong số đó được liệt kê dưới đây:
AllInterfaceslà danh sách tất cả các giao diện mà một kiểu implements. Các giao diện được implemented bởi các kiểu cơ sở cũng được tính đến;BaseTypelà kiểu cơ sở;Interfaceslà danh sách các giao diện được implemented trực tiếp bởi kiểu này;IsAnonymousTypelà thông tin về việc một kiểu có ẩn danh hay không.
Xây dựng trình phân tích mã nguồn đơn giản
Sau khi đi qua một phần rất dài về lý thuyết bên trên tôi dám chắc rằng các bạn cũng đã thấy nhàm chán rồi. Vậy hãy bắt đầu với việc viết một trình phân tích đơn giản để xem ta ứng dụng được gì từ những lý thuyết trên nhé.
Đặt bài toán
Hãy viết trình phân tích mà nó có thể tìm xem các câu lệnh điều kiện, trong đó các nhánh đúng và sai giống hệt nhau. Giả sử nếu mã chứa một đoạn như thế này thì trình phân tích sẽ cảnh báo lỗi:
public static void MyFunc1(int count)
{
if (count > 100)
{
Console.WriteLine("Hello world!");
}
else
{
Console.WriteLine("Hello world!");
}
}
Yêu cầu của trình phân tích là phải ghi số dòng và đường dẫn đầy đủ đến tệp nguồn vào log.
Chuẩn bị cho phân tích mã nguồn
Trước khi thực hiện phân tích, chúng ta phải lấy danh sách các tệp, mã nguồn sẽ được kiểm tra. Chúng ta có thể nghĩ đến một số bước cần được thực hiện để có được dữ liệu cần thiết cho việc phân tích:
- Tạo workspace;
- Nhận/đọc solution
- Nhận/đọc project;
- Phân tích cú pháp project: nhận biên dịch và danh sách các tệp;
- Phân tích cú pháp tệp: lấy cây cú pháp và mô hình ngữ nghĩa.
Thuật toán viết quy tắc chẩn đoán
- Bước đầu tiên là hình thành điểm chính của quy tắc. Trước khi phát triển, chúng ta nên nghĩ, "khi nào thì bộ phân tích sẽ đưa ra cảnh báo";
- Khi có một loại biểu mẫu cho quy tắc chẩn đoán và đã khá rõ ràng về các tình huống mà cảnh báo sẽ được đưa ra, chúng ta phải bắt đầu viết các unit test, đặc biệt - phát triển các bộ kiểm tra positive và negative. Positive tests sẽ kích hoạt chẩn đoán. Trong giai đoạn đầu của quá trình phát triển, điều quan trọng là phải làm cho cơ sở của các positive unit test càng lớn càng tốt, vì điều này sẽ giúp bắt được nhiều trường hợp đáng ngờ hơn. Negative unit test cũng đáng được quan tâm. Khi ta phát triển và kiểm tra chẩn đoán, cơ sở của negative unit test sẽ liên tục được bổ sung. Do thực tế này, lượng cảnh báo sai sẽ giảm, dẫn đến tỷ lệ cảnh báo tốt và xấu theo hướng mong muốn;
- Khi bộ unit test cơ bản đã sẵn sàng, chúng ta có thể bắt đầu triển khai chẩn đoán.
- Sau khi chẩn đoán sẵn sàng và tất cả unit test đều vượt qua thành công, chúng ta tiến hành kiểm tra trên các dự án thực tế. Điều này phát hiện dương tính giả (và thậm chí có thể bị lỗi) trong chẩn đoán của ta và mở rộng cơ sở của unit test. Càng nhiều dự án mã nguồn mở được sử dụng để thử nghiệm, thì càng có nhiều tùy chọn khả thi của mã được phân tích mà ta đang xem xét, chẩn đoán của ta càng tốt và mạnh mẽ hơn;
- Sau khi thử nghiệm các dự án thực tế, rất có thể ta sẽ phải tinh chỉnh chẩn đoán của mình, vì rất khó đạt được thành công trong lần đầu tiên. Thực hiện các thay đổi cần thiết và kiểm tra lại quy tắc;
- Lặp lại điểm trước đó cho đến khi kết quả chẩn đoán cho thấy kết quả mong muốn.
Xây dựng trình phân tích mã nguồn đơn giản
Quay lại với bài toán đã đặt ra ở phần đầu, ta xây dựng trình phân tích như sau:
using Microsoft.Build.Locator;
using Microsoft.CodeAnalysis;
using Microsoft.CodeAnalysis.CSharp;
using Microsoft.CodeAnalysis.CSharp.Syntax;
using Microsoft.CodeAnalysis.MSBuild;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
public class IfWalker : CSharpSyntaxWalker
{
public StringBuilder Warnings { get; } = new StringBuilder();
const string warningMessageFormat =
"'if' with equal 'then' and 'else' blocks is found in file {0} at line {1}";
static bool ApplyRule(IfStatementSyntax ifStatement)
{
if (ifStatement.Else == null)
return false;
StatementSyntax thenBody = ifStatement.Statement;
StatementSyntax elseBody = ifStatement.Else.Statement;
return SyntaxFactory.AreEquivalent(thenBody, elseBody);
}
public override void VisitIfStatement(IfStatementSyntax node)
{
if (ApplyRule(node))
{
int lineNumber = node.GetLocation()
.GetLineSpan()
.StartLinePosition.Line + 1;
Warnings.AppendLine(String.Format(warningMessageFormat,
node.SyntaxTree.FilePath,
lineNumber));
Console.WriteLine(Warnings);
}
base.VisitIfStatement(node);
}
public static void StartWalker(IfWalker ifWalker, SyntaxNode syntaxNode)
{
ifWalker.Warnings.Clear();
ifWalker.Visit(syntaxNode);
}
static IEnumerable<Project> GetProjectFromSolution(String solutionPath,
MSBuildWorkspace workspace)
{
//MSBuildLocator.RegisterDefaults();
Solution currSolution = workspace.OpenSolutionAsync(solutionPath)
.Result;
return currSolution.Projects;
}
static void Main(string[] args)
{
string solutionPath = @"D:\Project\VisualStudio\security-code-scan_test\SecurityCodeScan.sln";
string logPath = @"D:\Project\Test\warnings.txt";
MSBuildLocator.RegisterDefaults();
using(var workspace = MSBuildWorkspace.Create())
{
IEnumerable <Project> projects = GetProjectFromSolution(solutionPath, workspace);
foreach (var project in projects)
{
foreach (var document in project.Documents)
{
var tree = document.GetSyntaxTreeAsync().Result;
var ifWalker = new IfWalker();
StartWalker(ifWalker, tree.GetRoot());
var warnings = ifWalker.Warnings;
Console.WriteLine(warnings);
if (warnings.Length != 0)
File.AppendAllText(logPath, warnings.ToString());
}
}
}
}
}
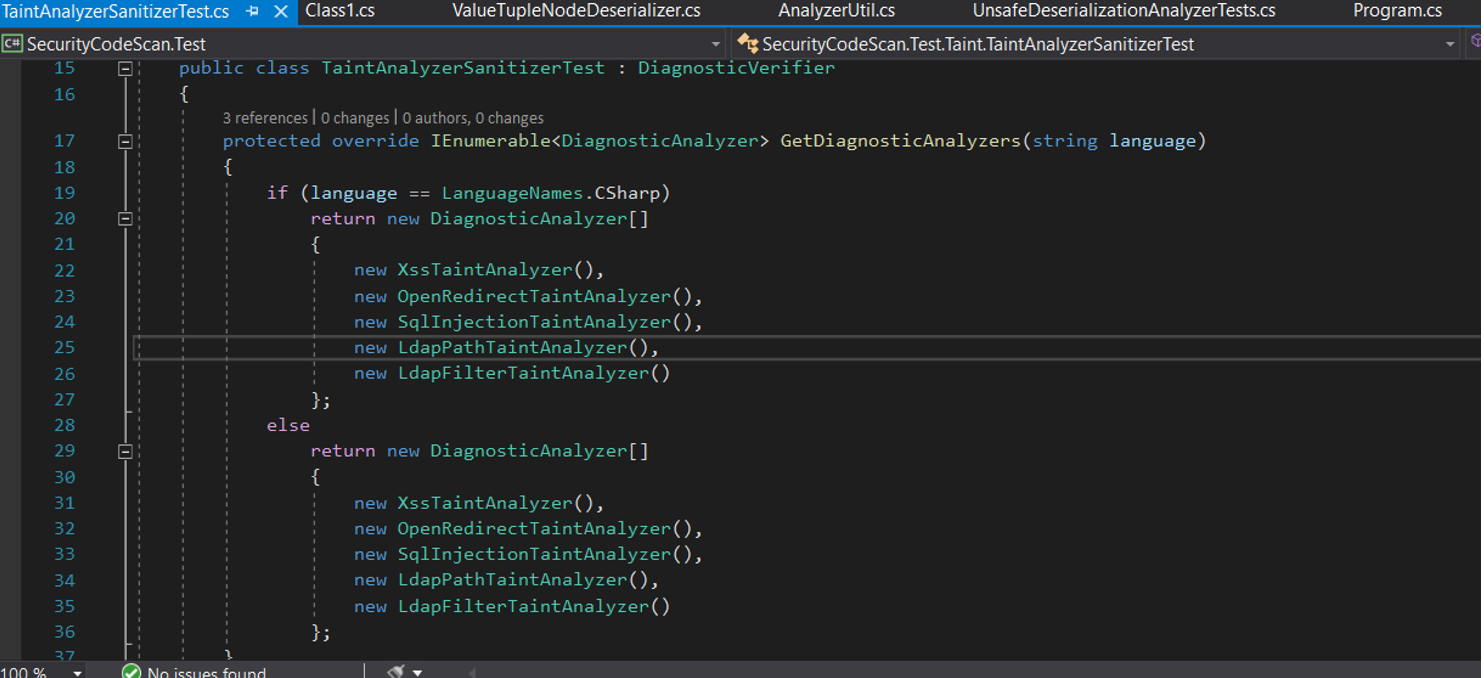
Đoạn code trên sử dụng CSharpSyntaxWalker, ghi đè lại phương thức VisitIfStatement, nếu như Rule được thỏa mãn sẽ thực hiện công việc ghi lại path đến file .cs và vị trí của nơi gặp lỗi. Phương thức GetProjectFromSolution sẽ chịu trách nhiệm load file solution lên và đọc các project hiện có trong file. Phương thức ApplyRule nhận đầu vào là một nút IfStatementSyntax, đầu tiên nó kiểm tra xem nút này có nhánh Else hay không, nếu không có thì trả về false. Ngược lại sẽ kiểm tra 2 khối if và else có giống hệt nhau hay không. Kết quả khi khởi chạy với 1 project mã nguồn mở như sau:
'if' with equal 'then' and 'else' blocks is found in file D:\Project\VisualStudio\security-code-scan_test\SecurityCodeScan.Test\Tests\Taint\TaintAnalyzerSanitizerTest.cs at line 19
Kết
Đến đây tôi nghĩ rằng các bạn đã có đủ kiến thức để xây dựng công cụ phân tích mã tĩnh cho riêng mình. Tuy nhiên mọi thứ vẫn chưa dừng lại ở đó. Ở phần tiếp theo tôi sẽ giới thiệu với các bạn cách để có thể làm cho công cụ của mình trở nên thông mình hơn bằng cách sử dụng taint tracking, data flow analysis và control flow analysis. Hẹn các bạn ở phần 2 của bài viết !!!
Tham khảo
https://joshvarty.com/learn-roslyn-now/
https://medium0.com/pvs-studio/creating-roslyn-api-based-static-analyzer-for-c-c0d7c27489f9




