Pandas là thư viện rất quan trọng đối với các lập trình viên Python hiện nay. Thư viện này được ví như backbone của hầu hết các dự án dữ liệu.
Nếu bạn đang có dự định theo ngành khoa học dữ liệu thì điều bắt buộc mà bạn phải làm là tìm hiểu về Pandas. Hy vọng sau chuỗi bài đăng này, chúng ta sẽ biết được những thông tin cần thiết về cách cài đặt, cách sử dụng và cách nó hoạt động với các gói phân tích dữ liệu Python phổ biến khác.
Note: Trước khi tìm hiểu Pandas, bạn nên có kiến thức nền về Python (lists, tuples, dictionaries, functions, and iterations)
Nếu bạn đã sẵn sàng thì chúng ta cùng bắt đầu thôi nào ^^
1. Install and import
Đầu tiên, bạn phải cài đặt gói của thư viện Pandas vào môi trường của mình. Có 2 cách đơn giản như sau:
conda install pandas hoặc pip install pandas
Sau đó, mỗi khi sử dụng thì bạn chỉ cần import nó vào chương trình của mình bằng cách chạy lệnh import pandas as pd
Pandas có 2 thành phần chính đó là Series và DataFrame. Để bạn dễ hình dung thì ta xem DataFrame như là một bảng dữ liệu 2 chiều, trong đó mỗi cột tương ứng là Series
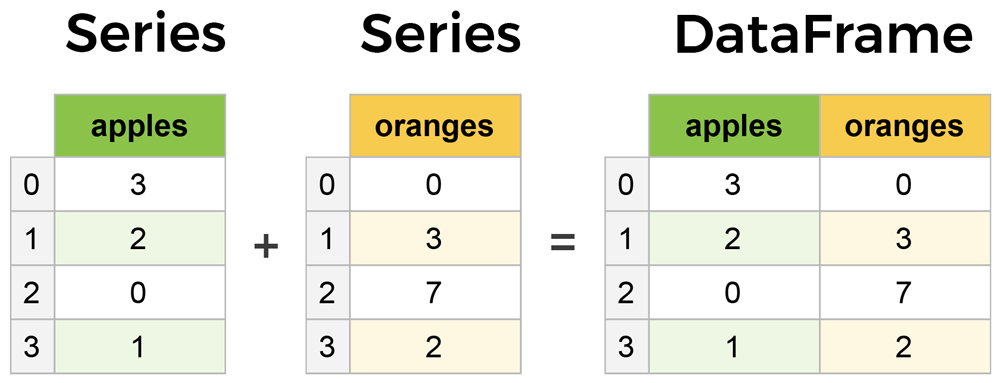
2. How to create DataFrame
Cách đơn giản nhất để tạo một DataFrame là xây dựng từ một Dictionary.
Giả sử ta cần lưu lại lịch sử mua hàng thì DataFrame này sẽ gồm những cột tương ứng với mỗi mặt hàng và mỗi dòng là số lượng mà khách hàng đã chọn. Ví dụ gian hàng này chỉ có 2 loại là cam và táo, có 4 khách hàng đến mua hàng. Chúng ta sẽ tổ chức dữ liệu dưới dạng các cặp key : value như trong đoạn code sau:
import pandas as pd
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
#load data into a DataFrame object:
df = pd.DataFrame(data)
print(df)
Kết quả ta sẽ được output:
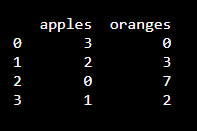
Mặc định Pandas sẽ tạo thêm một cột Index ở phía trước để giúp ta dễ dàng truy vấn về sau.
Để lấy thông tin khách hàng đầu tiên ta làm bằng cách:
print(df.iloc[0])
Ngoài ra ta có thể định dạng lại cột Index bằng cách thêm index vào lúc tạo DataFrame
import pandas as pd
data = {
'apples': [3, 2, 0, 1],
'oranges': [0, 3, 7, 2]
}
#load data into a DataFrame object:
df = pd.DataFrame(data, index = ["An", "Bình", "Minh", "Hoàng"])
print(df)
Kết quả là 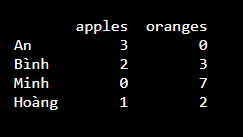
3. Get info about DataFrame
Viewing your data
df.head() #hiển thị mặc định 5 dòng đầu trong dataframe
df.head(20) # hiển thị 20 dòng đầu trong dataframe
hoặc
df.tail() #hiển thị mặc định 5 dòng cuối trong dataframe
df.tail(10) # hiển thị 10 dòng đầu cuối dataframe
Getting info about your data
df.info()
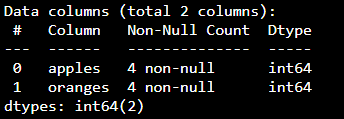
Summary
Việc hiểu tường tận một thư viện trong một thời gian ngắn rất khó, chính vì thế mình sẽ chia nhỏ các phần ra để các bạn có hứng thú học tập hơn. Mình tin chắc rằng thông qua Part 1 thì chúng ta đã hiểu về DataFrame là gì? Tạo và xem thông tin DataFrame bằng cách rất đơn giản.
Ở bài viết sau mình sẽ làm rõ cách thao tác với Pandas để làm sạch và xử lý dữ liệu. Hẹn gặp lại các bạn ở Part 2.
Tài liệu tham khảo
- Applied Data Science with Python - Coursera
- 100 Days of Code: The Complete Python Pro Bootcamp for 2022 - Udemy
- Pandas Tutorial - W3School
- Python Pandas Tutorial: A Complete Introduction for Beginners


