Trong bài viết này, chúng ta sẽ cùng tìm hiểu cách thức để thực hiện thao tác đọc một tệp dữ liệu và gửi trả tới trình duyệt web khi nhận được yêu cầu truy cập tới địa chỉ server mà chúng ta đã khởi tạo trong bài trước. Các tác vụ làm việc với các thư mục và các tệp dữ liệu được NodeJS hỗ trợ bằng cách cung cấp cho người viết code một module chuyên dụng. Hãy cùng tìm hiểu về công cụ này.
Sử dụng một module của NodeJS
Một module trong NodeJS thường được đóng gói trong một object đại diện, và chúng ta có thể truy xuất object này bằng cách sử dụng hàm require('tên-module') giống như ở dòng code đầu tiên trong đoạn code server ví dụ ở bài trước.
/* Creating a server */
const http = require("http");
/* ... */
Bên cạnh đó thì bạn cũng có thể sử dụng cú pháp import/export của JavaScript để yêu cầu một module hay một thành phần của module cần sử dụng. Tuy nhiên thì để sử dụng cú pháp import/export mặc định của JavaScript, chúng ta sẽ cần thực hiện một vài thao tác thiết lập và không hẳn là cần thiết lắm ở thời điểm hiện tại. Do đó mình và bạn sẽ tiếp tục học và sử dụng require và exports của NodeJS thêm một thời gian cho đến khi... một vài bài viết nữa. 
Trong code ví dụ mở đầu thì module mà chúng ta đã sử dụng có tên là http. Đây là module được thiết kế để cung cấp các công cụ làm việc với giao thức HTTP - HyperText Transfer Protocol - được hiểu nôm na là giao thức truyền tải nội dung siêu văn bản; Trong đó thì cụm từ siêu văn bản hay HyperText ở đây là để chỉ các văn bản HTML - HyperText Markup Language.
Nghe rườm rà thật đấy. Nhưng mà chúng ta chỉ cần hiểu tổng quan thôi chứ việc ghi nhớ mấy cái tên đầy đủ của mấy thuật ngữ này cũng không quan trọng lắm đâu.
Các module được môi trường NodeJS cung cấp mặc định đều được lập tài liệu tại trang chủ của NodeJS ở đây - Tài liệu về các module của NodeJS.

Và trong code ví dụ trước đó, hàm require đã được sử dụng để yêu cầu http ở thư viện mặc định của môi trường NodeJS. Chúng ta cũng có thể cài đặt thêm các module được chia sẻ qua lại giữa cộng đồng lập trình viên giống như việc sử dụng các library và framework ở phía client-side. Tuy nhiên đây cũng sẽ là câu chuyện mà chúng ta nên để dành thêm một vài bài viết nữa.
Làm quen với cấu trúc tài liệu của NodeJS
Trong trang tài liệu này thì bạn có thể thấy một thanh điều hướng chính ở phía bên trái là danh sách của tất cả các module được cung cấp bởi NodeJS. Mỗi một module sẽ thực hiện một nhóm tác vụ nhất định xoay quanh tên gọi của module đó. Chúng ta đang cần tìm cách để mở và xem nội dung của một tệp, nên từ khóa phù hợp nhất trong danh sách các module mà chúng ta đang thấy ở đây là File System - Tài liệu về module File System.

Trong trang tài liệu về một module bất kỳ của NodeJS, cấu trúc nội dung chung chung sẽ là một cái danh sách các chỉ mục nội dung Table of contents của trang đó rất rất dài. Và ở bên dưới là các đoạn viết nội dung chi tiết cho các chỉ mục đã được liệt kê cực kỳ cực kỳ dài. Tuy nhiên thì điều quan trọng nhất là chúng ta chỉ cần hiểu được cấu trúc tổng quan của cái Table of contents là sẽ ổn thôi.
Thông thường thì mỗi module sẽ có các sub-module nhỏ hơn và được đóng gói thành một vài object đại diện. Và mỗi sub-module sẽ được dành luôn cho một phần ví dụ đại biểu ở ngay phần đầu tiên của trang tài liệu, chỉ đứng sau cái Table of contents. Do đó khi bạn nhìn vào danh sách các chỉ mục thì sẽ thấy đầu tiên là tên module, rồi rẽ nhánh tới các chỉ mục cấp gần nhất là các ví dụ example đại biểu cho các module con và các chỉ mục tài liệu chi tiết API của các module con; Và cái Table of contents của chúng ta ở đây đang có dạng tổng quan thế này -
+ File system
+ Promise example
+ Callback example
+ Synchronous example
+ Promises API
+ Callback API
+ Synchronous API
Về việc tại sao NodeJS họ không làm các tab có thể thu gọn/mở rộng cho các chỉ mục API thì mình không rõ. Nhưng đúng là nếu cứ để một danh sách các chỉ mục nội dung rất rất dài như vậy luôn được hiển thị đầy đủ, thì mặc dù nội dung đã được phân cấp rất tuyệt vời cũng vẫn sẽ rất khó cho người đọc có thể theo dõi nếu như không dành thời gian ra để tổng quát lại cái Table of contents. 😅
Sau khi đã nhìn qua những cái tên sub-module là promise, callback, và synchronous, chúng ta có thể hiểu lơ mơ là các tác vụ làm việc với các thư mục và các tệp được thực hiện bởi File system có thể được thực thi đồng bộ với sự hỗ trợ của Synchronous API, hoặc được thực thi bất đồng bộ với sự hỗ trợ của Callback API và Promises API. Bởi vì các khái niệm này thì chúng ta đều đã được gặp trong Sub-Series JavaScript rồi.
Tuy nhiên thì mình nghĩ là chúng ta vẫn nên ngó qua mấy cái ví dụ example đại biểu của các sub-module xem nhỡ như có hiểu lầm gì không. Với lại tiện thể thì đọc qua phần mở đầu giới thiệu về module tổng File system xem có lưu ý gì quan trọng trước khi sử dụng không.

Ở đây chúng ta có hướng dẫn cơ bản cách yêu cầu một module để sử dụng trong tệp JavaScript mà chúng ta đang làm việc. Dạng cú pháp import đang được hiển thị là ESM - cú pháp mặc định của JavaScript. Còn nếu bạn click vào cái công tắc chuyển đổi CJS/ESM ở phía bên phải thì sẽ thấy code ví dụ trong khung hiển thị đó thay đổi sang cú pháp CJS và sử dụng hàm require như chúng ta đã dùng trong ví dụ trước đó.
// sử dụng các API promises
const fsPromises = require("fs/promises");
// sử dụng các API callback và synchronous
const fs = require("fs");
Tiếp tục xem các ví dụ đại biểu cho các module con ở phía dưới, chúng ta thử so sánh code ví dụ của synchronous và callback một chút.
const { unlinkSync } = require("fs");
try {
unlinkSync("/tmp/hello");
console.log("Successfully deleted /tmp/hello");
}
catch (error) {
// handle the error
}
const { unlink } = require("fs");
unlink("/tmp/hello", function(error) {
if (error) throw error;
else console.log("successfully deleted /tmp/hello");
});
Đều là code để thực hiện một tác vụ nào đó, đang sử dụng tới các hàm có từ khóa chung là unlink của File System, có dòng code in thông báo là xóa thành công một tệp /tmp/hello nào đó. Đúng như cách thức mà chúng ta sử dụng các hàm xử lý bình thường synchronous, và các hàm bất đồng bộ asynchronous kèm theo callback. Vậy là không có nhầm lẫn gì rồi.
Bây giờ chúng ta cần đặt một chút suy nghĩ cho tác vụ đọc nội dung của một tệp để chọn ra một trong số các module con của File system và xử lý tác vụ. Rõ ràng là để đọc nội dung của một tệp bất kỳ thì chắc chắn tác vụ này sẽ tạo ra một quãng thời gian trễ cho tiến trình vận hành chung của hệ thống. Do đó Synchronous API có lẽ là lựa chọn chỉ dành cho một số ít trường hợp khi chúng ta thực sự không thể làm khác được. Giải pháp đầu tiên mà chúng ta nên ưu tiên sử dụng sẽ luôn là các phương thức xử lý được thực thi bất đồng bộ asynchronous được cung cấp bởi Callback API và Promises API.
Đằng nào thì cũng tiện một công mở trình soạn thảo code lên để học NodeJS, chúng ta sẽ thử cả 2 nhóm API này và xem cách viết nào phù hợp với phong cách tư duy logic của mình nhất, hoặc là kiểu định dạng code nào mà mình nhìn thấy vừa mắt nhất.
Sử dụng Callback API
Thao tác chúng ta đang cần xử lý là đọc nội dung của một tệp, và từ khóa tương ứng sau khi Google Translate qua tiếng Anh thì nó là read. Và trong danh sách chỉ mục con của Callback API thì chúng ta có một số cái read như thế này -
+ fs.read( ... )
+ fs.readdir( ... )
+ fs.readFile( ... )
+ fs.readlink( ... )
+ fs.readv( ... )
Rồi... may quá là có cái fs.readFile đúng luôn với nhu cầu cần xử lý. Chắc tới 99.99% là cái mà chúng ta cần tìm rồi, di chuyển tới phần nội dung đó ngay.

Đầu tiên thì chúng ta thấy có cú pháp tổng quan của fs.readFile với các tham số đầu vào là -
path- đường dẫn thư mục của tệp cần đọc.callback- hàm gọi lại để tiếp nhận và xử lý dữ liệu kết quả hoặc mộtobjectmô tả ngoại lệerrornếu không đọc được tệp vì lý do nào đó.[, options]- các tham số phụ được đặt ở giữapathvàcallback, có thể có hoặc không.
Sau đó thì chúng ta nhìn thấy code ví dụ để đọc một tệp có đường dẫn thư mục là /etc/passwd. Ở đây chúng ta thay cú pháp import bằng require() như đã nói nhé.
const { readFile } = require("fs");
readFile("/etc/passwd", function(error, data) {
if (error) throw error;
else console.log(data);
});
Mọi thứ trông khá gọn gàng và dễ hiểu. Hàm readFile sẽ thực hiện thao tác đọc nội dung của tệp /etc/passwd bằng một logic xử lý nào đó mà chúng ta không cần quan tâm tới. Tuy nhiên sau khi thực hiện xong thao tác đọc nội dung của tệp đó thì readFile sẽ gọi hàm callback được truyền vào, để bàn giao kết quả hoạt động.
Lúc này công việc tiếp theo được định nghĩa trong hàm callback để xử lý kết quả nhận được. Nếu có một object Error được trả về thì sẽ throw luôn object mô tả ngoại lệ đó. Trong trường hợp không có object Error được trả về thì có nghĩa là thao tác đọc nội dung của readFile đã thành công và có dữ liệu được trả vào tham số data để in ra console.
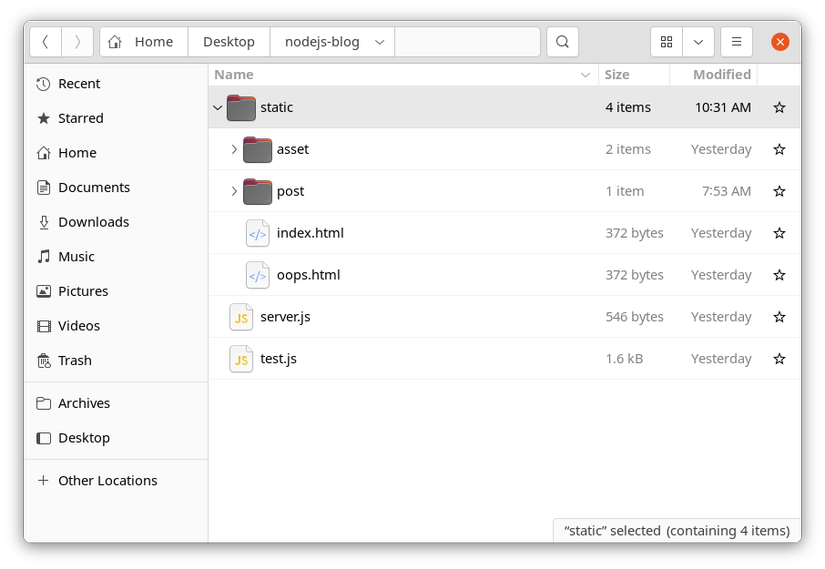
Bây giờ chúng ta hãy copy/paste và chạy thử code này xem sao. Đầu tiên chúng ta sẽ cần chuẩn bị một tệp index.html để làm đối tượng mà hàm readFile sẽ tìm đến đọc nội dung. Về đường dẫn thư mục thì chúng ta sẽ bắt đầu quy ước từ bây giờ để làm điểm khởi đầu cho các bài viết tiếp theo nữa. Chúng ta sẽ có một thư mục tổng là nodejs-blog với cấu trúc các thư mục con và các tệp bên trong khởi đầu như thế này -
[nodejs-blog]
|
+---[static]
| |
| +---[asset]
| | |
| | +---style.css
| | +---main.js
| |
| +---[post]
| | |
| | +---an-article.html
| | +---another-article.html
| |
| +---index.html
| +---oops.html
|
+---server.js
+---test.js
Chúng ta sẽ khởi đầu với tệp index.html có nội dung đơn giản thôi, một cái tiêu đề là được.
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Homepage</title>
<link rel="stylesheet" href="/asset/style.css">
</head>
<body>
<h1>Hello NodeJS !</h1>
<script src="/asset/main.js"></script>
</body>
</html>
Bây giờ trong tệp test.js chúng ta sẽ copy/paste code của server.js trong ví dụ ở bài trước, đồng thời copy/paste cả code ví dụ của fs.readFile trong tài liệu của NodeJS và chỉnh sửa lại một chút để đọc và gửi nội dung của tệp index.html ở dạng phản hồi khi server nhận được yêu cầu. Lúc này, các thao tác phản hồi lại yêu cầu response.doSomething() sẽ được di chuyển vào bên trong định nghĩa hàm callback của readFile để có thể sử dụng được biến data.
/* Creating a server */
const http = require("http");
const fs = require("fs");
const handleRequest = function(request, response) {
// var path = "static\\index.html"; // windows
var path = "static/index.html"; // linux
var callback = function(error, data) {
if (error) {
throw error;
}
else {
response.setHeader("content-type", "text/plain");
response.statusCode = 200;
response.end(data);
}
}; // callback
fs.readFile(path, callback);
}; // handleRequest
const server = http.createServer(handleRequest);
/* Start running server */
const port = 3000;
const hostname = "127.0.0.1";
const callback = function() {
console.log("Server is running at...");
console.log(`http://${hostname}:${port}/`);
};
server.listen(port, hostname, callback);
Bây giờ thì chúng ta mở cửa sổ dòng lệnh và khởi động server thôi.
cd Desktop/nodejs-blog/
Nhưng lần này là chúng ta sẽ chạy tệp test.js nhé.
node test.js
:: Server is running at...
:: http://127.0.0.1:3000/
node test.js
# Server is running at...
# http://127.0.0.1:3000/

Ồ... vậy là thao tác đọc dữ liệu của hàm readFile đã hoạt động tốt, toàn bộ nội dung của tệp index.html đã được gửi cho trình duyệt web khi server nhận được yêu cầu. Nhưng chúng ta không muốn hiển thị code cho người dùng xem như vậy, họ chỉ cần đọc thông tin thôi mà.
Sau một hồi lay hoay thì mình cũng tìm ra nguyên nhân và phương án xử lý. Đó là ở câu lệnh response thứ 2 có nói về kiểu nội dung gửi trả content-type và đang được thiết lập để thông báo cho trình duyệt web là text/plain - có nghĩa là đây là nội dung văn bản/dạng thô, không có gì đặc biệt đâu.
Chắc đây là lý do trình duyệt web nhận được bao nhiêu chữ nghĩa là cứ cho hiện đầy đủ hết lên để người dùng xem luôn; Không cả cần ngó qua xem nội dung đó là cái gì. Chứ nếu trình duyệt web mà biết là code HTML thì chắc chắn là sẽ xử lý khác. Bây giờ chúng ta hãy thử thay đổi chỗ text/plain thành text/html xem sao.
Bạn lưu ý là phần mềm server của chúng ta sẽ được lưu vào bộ nhớ đệm của máy tính để vận hành, và những thay đổi trong code mà chúng ta tạo ra sẽ không có hiệu lực cho đến khi phần mềm server được khởi động lại. Bây giờ chúng ta cần thao tác nhấn tổ hợp phím Ctrl + C để cửa sổ dòng lệnh dừng server lại, và chạy lại lệnh node test.js để phần mềm khởi động lại với code mới.

Tuyệt... như vậy là trình duyệt web đã nhận được thông báo rằng đây là nội dung văn bản/code HTML và chỉ hiển thị nội dung của thẻ tiêu đề h1. Như vậy là vấn đề nằm ở hàm xử lý yêu cầu và phản hồi, và chúng ta chưa thể tìm hiểu thêm về những thứ liên quan vào lúc này. Ít nhất thì chúng ta đã biết là hàm readFile đã hoạt động hoàn toàn ổn với callback mà chúng ta truyền vào. Bây giờ chúng ta sẽ thử thao tác đọc tệp index.html với sự hỗ trợ của Promises API.
Sử dụng Promises API

Tương ứng với phương thức fs.readFile của Callback API thì ở đây chúng ta có fsPromises.readFile. Thay vì truyền vào một callback để tiếp nhận kết quả của thao tác đọc tệp như phần trước thì chúng ta sẽ chỉ truyền vào đường dẫn thư mục của tệp cần đọc và nhận được một object Promise hứa hẹn là sẽ trả lời kết quả của thao tác đọc sớm nhất có thể. Nếu đọc được nội dung của tệp thì sẽ resolve(data) nội dung cho chúng ta .then một thao tác xử lý tiếp theo; Còn nếu có lỗi phát sinh thì sẽ reject(error) cho chúng ta .catch một thao tác xử lý ngoại lệ.
/* Creating a server */
const http = require("http");
const fsPromises = require("fs/promises");
const handleRequest = function(request, response) {
// var path = "static\\index.html"; // windows
var path = "static/index.html"; // linux
fsPromises.readFile(path)
.then(function(data) {
response.setHeader("content-type", "text/html");
response.statusCode = 200;
response.end(data);
})
.catch(function(error) {
throw(error);
});
}; // handleRequest
/* ... */
Sau khi chỉnh sửa lại hàm handleRequest của server để yêu cầu hàm readFile của Promises API thì chúng ta đã có thể gọi hàm và chuyển các thao tác xử lý data và error vào hai phương thức .then và .catch nối tiếp. Khởi động lại server và kiểm tra kết quả hoạt động thôi.
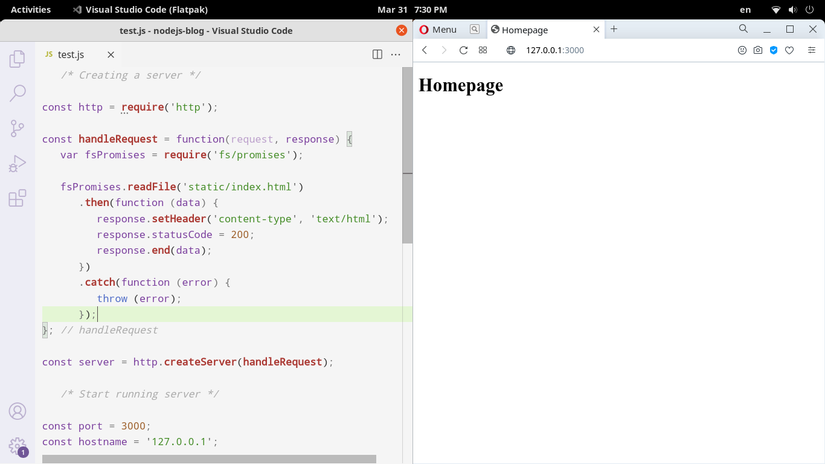
Mình đoán là bạn cũng thấy kết quả hoạt động không có gì khác biệt. Mọi thứ đều rất ổn giống như khi sử dụng Callback API. Như vậy là NodeJS không chỉ cung cấp cho chúng ta một lựa chọn duy nhất cho mỗi tác vụ cần thực hiện, mà thay vào đó thì chúng ta còn có những lựa chọn thay thế. Hãy cùng lưu ý điểm quan trọng này, bởi vì chúng ta sẽ có thể tự tin hơn khi cần phải đưa ra giải pháp mà bản thân cảm thấy phù hợp. Sẽ luôn có nhiều hơn một phương án xử lý tốt cho một tác vụ cần thực hiện.
Vấn đề về đường dẫn thư mục
Trong code ví dụ ở phía trên chúng ta đã phải comment một dòng code tạo đường dẫn thư mục để có thể đọc được tệp trên Windows hoặc Linux/Mac do cách biểu thị đường dẫn thư mục của các hệ điều hành có phần khác nhau một chút. Để khắc phục vấn đề này, NodeJS có cung cấp cho chúng ta một module hỗ trợ có tên là path.
/* Creating a server */
const http = require("http");
const fsPromises = require("fs/promises");
const path = require("path");
const handleRequest = function(request, response) {
var indexHtml = path.join(__dirname, "static", "index.html");
fsPromises.readFile(indexHtml)
.then(function(data) {
response.setHeader("content-type", "text/html");
response.statusCode = 200;
response.end(data);
})
.catch(function(error) {
throw(error);
});
}; // handleRequest
/* ... */
Trong code ví dụ ở phía trên, phương thức path.join() sẽ giúp chúng ta ghép nối tên của tất cả các thư mục được truyền vào theo thứ tự, và tạo ra một đường dẫn phù hợp với hệ điều hành đang chạy server. Trong đó biến __dirname là một biến toàn cục, có thể được sử dụng ở bất kỳ đâu trong project; Biến này lưu trữ địa chỉ đường dẫn tính từ thư mục gốc của ổ cứng đang chứa thư mục nodejs-blog tới thư mục đang chứa tệp .js đang sử dụng biến này.
Kết thúc bài viết
Sau khi chắc chắn là đã có thể tự tin đọc nội dung của một tệp với sự hỗ trợ của File System rồi thì chúng ta bắt đầu đi tới những câu hỏi tiếp theo. Ở đây chúng ta đang truyền vào hàm đọc tệp một đường dẫn tĩnh static/index.html. Nếu bây giờ chúng ta gõ vào thanh địa chỉ của trình duyệt web để yêu cầu tải một tệp khác, ví dụ article.html, để đọc một bài viết thì kết quả trả về hiển nhiên vẫn đang là nội dung của trang chủ index.html.
Như vậy thì điều quan trọng cần làm tiếp theo đó là chúng ta cần phải tìm hiểu cách xem nội dung yêu cầu request và phân loại xử lý để hàm handleRequest có thể tìm và trả về tệp tương ứng với yêu cầu nhận được. Và đó sẽ là chủ đề của chúng ta trong bài sau. Bây giờ thì chúng ta nên nghỉ giải lao một chút đã. Hẹn gặp lại bạn trong bài viết tiếp theo.
P/s:
Nhân tiện thì bài viết này của chúng ta nhằm mục đích giới thiệu module FileSystem và làm quen với cấu trúc tài liệu hướng dẫn của NodeJS. Do đó bạn có thể tự tra cứu và luyện tập các phương thức để tạo tệp mới và ghi nội dung vào đó, hay xóa một tệp nào đó. Như vậy chắc chắn là bạn sẽ sớm cảm thấy quen thuộc với cách lập tài liệu của NodeJS và chúng ta sẽ có thể tự tin hơn để lướt qua các module khi cần sử dụng tới một tính năng nào đó do trong thư viện mặc định.
Thêm vào đó là mình quên chưa nói về tệp server.js và test.js. Về cơ bản thì chúng ta sẽ viết và sửa code trong tệp test.js để chạy thử. Còn tệp server.js là để bạn chọn ra code mà bạn muốn sử dụng để cập nhật dần đần khi cảm thấy đã chắc chắn logic vận hành của một đoạn code mới nào đó. Bởi vì chúng ta vừa học kiến thức mới và vừa cập nhật nên mình muốn tránh tình huống viết đè ngay code mới thay cho code cũ và ảnh hưởng đến cột mốc logic vận hành cũ, thời điểm mà bạn đang hiểu được chắc chắn tính năng và giới hạn của code đó.