I. Giới thiệu
Nghiên cứu và ứng dụng mô hình Transformer trong bài toán xử lý ngôn ngữ (natural language processing) đã trở nên vô cùng phổ biến. Tuy nhiên trong thị giác máy tính thì ứng dụng và nghiên cứu mô hình Transformer còn hạn chế. Khi gặp những bài toán thị giác máy tính như object detection, object segmentation, ... kiến trúc tích chập vẫn là kiến trúc quen thuộc mà chúng ta thường sử dụng.
Tiếp cận một hướng đi mới trong các bài toán về thị giác máy tính, lấy cảm hứng từ việc ứng dụng kiến trúc Transformer vào xử lý ngôn ngữ tự nhiên, các nhà nghiên cứu từ Google Research đã giới thiệu kiến trúc Vision Transformer - một phiên bản kiến trúc Transformer cho ảnh trong bài báo AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE. Kiến trúc này đã đạt được nhiều kết quả nổi trội trong nhiều bài toán khác nhau. Hôm nay chúng ta cùng đi phân tích xem kiến trúc này có gì đặc biệt nhé.
II. Vision Transformer hoạt động như thế nào ?
 Source – https://github.com/lucidrains/vit-pytorch/blob/main/vit.gif
Source – https://github.com/lucidrains/vit-pytorch/blob/main/vit.gif
1. Chia ảnh thành các phần nhỏ và duỗi thẳng
Trong bài viết lần này mình sẽ không nhắc lại mô hình Transformer truyền thống nhưng nếu các bạn chưa từng nghiên cứu qua mô hình này thì các bạn có thể tham khảo những bài viết sau:
Kiến trúc Transformer truyền thống nhận đầu vào là một chuỗi token embedding 1D. Do đó để xử lý đầu vào là ảnh có kích thước 2D, mô hình Vision Transformer chia nhỏ ảnh đầu vào thành các gói (patches) có kích thước cố định giống như các chuỗi word embedding được sử dụng trong mô hình Transformer truyền thống áp dụng cho text.
Ví dụ: Với (H, W) là kích thước của ảnh đầu vào, C là số channels, P là kích thước mỗi gói sau khi chia. Ta biểu diễn lại ảnh đầu vào có kích thước thành . Số gói ta có thể chia từ ảnh đầu vào là .
Có một lưu ý là thực tế ta hiếm khi dùng trực tiếp Vision Transformer (VIT) trên ảnh trực tiếp. Thông thường ta sẽ dùng một mạng CNN để trích xuất đặc trưng từ ảnh đầu vào. Và ta dùng bản đồ đặc trưng (feature map) cuối cùng để làm đầu vào cho VIT tương tự như bên trên.
Do VIT vẫn sử dụng hằng số kích thước embedding size D trong mô hình do đó chúng ta cần một phép biển đổi tuyến tính biến các gói về kích thước D. Phép biến đổi này còn gọi là patch embedding.
2. Nhúng vị trí - Position embedding.
Để giữ thông tin về vị trí của các gói ta có thực hiện cộng patch embedding thu được ở bước bên trên với một vector vị trí có thể huấn luyện. Vector vị trí này có kích thước 1D giúp giảm kích thước lưu trữ so với vector 2D.
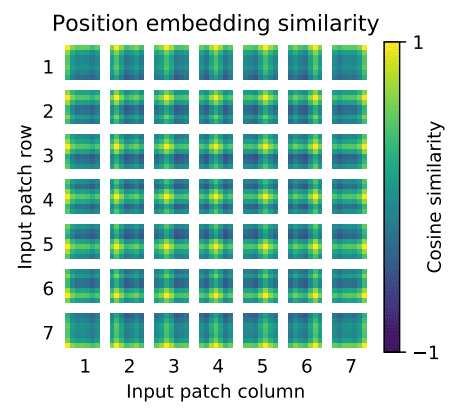 Source:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Source:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Những gói nào ở cùng hàng/cột sẽ có embedding giống nhau hay có biểu diễn giống nhau. Có ý kiến cho rằng việc học thứ tự quan hệ giữa các gói không tạo ra quá nhiều điều khác biệt do quá dễ học thông tin quan hệ giữa các gói với nhau do VIT hoạt động ở mức gói. Tuy nhiên cá nhân tôi nghĩ giữ thông tin vị trí trong patch embedding là cần thiết để mô hình học được thứ tự từng gói trong ảnh qua đó đảm bảo được ngữ nghĩa của từng object trong ảnh.
3. Transformer Encoder
Transformer encoder lấy đầu vào là tổng hợp các thông tin patch embedding và position embeding bao gồm các lớp Multihead Attention, khối MLP và Layer norm.
![]() Source:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Source:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Trong paper, tác giả có đề cập đến hai đặc trưng của Vision Transformer:
Inductive bias: Vision Transformer có ít inductive bias vào một hình ảnh cụ thể hơn kiến trúc CNN. Lý do bởi vì trong kiến trúc mạng CNN, ba đặc điểm địa phương hóa, kiến trúc hàng xóm 2 chiều và dịch chuyển tương đương đều có trong từng lớp. Tuy nhiên trong VIT, chỉ có lớp MLP là có tính chất địa phương hóa và dịch chuyển tương đương.
Kiến trúc kết hợp: Như đã nói ở phần trên, thay vì lấy trực tiếp đầu vào là ảnh. VIT thường kết hợp với kiến trúc CNN để trích xuất đặc trưng từ ảnh đầu vào, sau đó lấy bản đồ đặc trưng cuối cùng làm đầu vào cho mô hình VIT.
III. So sánh kết quả.
Ở trong bài báo lần này, tác giả so sánh 2 mô hình lớn nhất là VIT-H/14 và VIT-L/16 với những mô hình CNN đang đạt kết quả tốt nhất hiện nay.
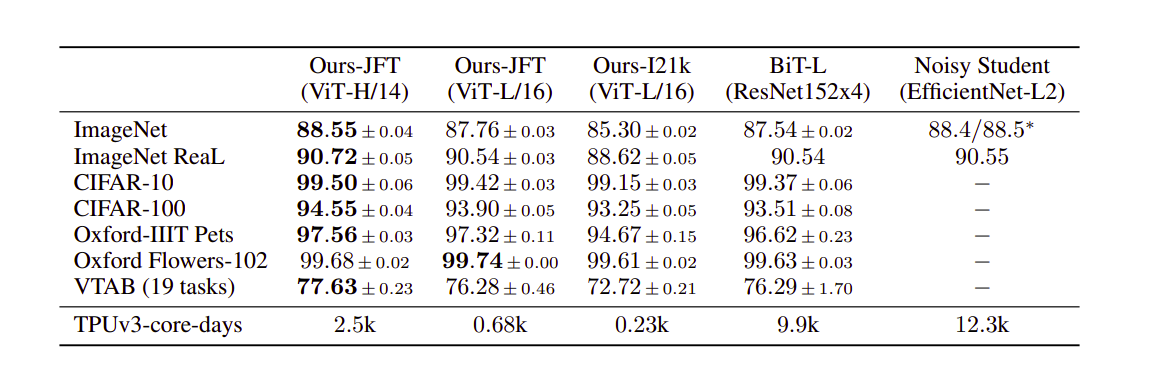
Kết quả thí nghiệm cho thấy, mô hình nhỏ hơn VIT-L/16 có pretrain trên tập JFT-300M đã đạt kết quả vươt trội BIT-L. Trong khi đó mô hình lớn hơn là VIT-H/14 cải thiện độ chính xác đáng kể đặc biệt trong những bộ dữ liệu thử thách như ImageNet, CIFAR-100, ...
IV. Lời kết.
Vision Transformer đã và đang mở ra nhiều hướng đi mới ứng dụng mô hình Transformer giải quyết những bài toán thị giác máy tính từ các bài toán object recognition, object segmentation, classification đều đã đạt những kết quả vượt trội so với kiến trúc CNN truyền thống. Tuy nhiên để ứng dụng thực tế còn phụ thuộc vào nhiều điền kiện bài toán thực tế ví dụ như mô hình VIT còn tương đối nặng do đó xử lý tương đối tốn thời gian. Cảm ơn các bạn đã theo dõi bài viết của mình. Hy vọng bài viết có thể mang lại nhiều kiến thức hữu ích cho mọi người.

