Elastic Stack - ELK là một nhóm các dự án mã nguồn mở (open source) được triển khai nhằm mục đích thu thập, phân tích, thống kê, tìm kiếm và trực quan hóa dòng dữ liệu (Data Stream) theo thời gian thực. Elastic Stack - ELK là viết tắt của 3 chữ cái đầu của 3 sản phẩm đại diện trong nhóm Elastic Stack:
- Elasticsearch
- Logstash
- Kibana
Trong đó:
- Elasticsearch là một công cụ tìm kiếm phân tán được dựa trên Lucene được viết bằng ngôn ngữ Java, là một "No-SQL database" trung gian giữa Logstash và Kibana. Và chúng ta có thể tương tác trực tiếp với database này thông qua HTTP Request.
- Logstash như một công cụ giúp thu thập dữ liệu theo thời gian thực. Logstash có thể hợp nhất dữ liệu từ nhiều nguồn khác nhau và chuẩn hóa chúng theo các đầu ra đã được quy định.
- Kibana được coi như cánh cửa của Elastic Stack với vai trò quản lý, giám sát và thống kê dữ liệu. Mọi thao tác với dữ liệu được xử lý sẽ được quan sát tập trung trên Kibana.
Có thể hình dung mô hình ELK như một nhà máy phân loại hàng hóa. Những gói hàng được đến từ nhiều nguồn khác nhau từ những nơi khác nhau. Logstash như là một băng chuyền để lọc những hàng hóa theo các nguồn (như vị trí địa lý, quốc gia, ...) và chuyển các gói hàng đó đến đúng nhóm quy định, các nhóm ở đây là các index trong Elasticsearch. Dữ liệu đến sẽ được lưu trữ trên các index này.
Lời nói đầu
Trong các hệ thống có sự tương tác của users và hơn thế nữa là các user có thể tương tác với nhau thì đâu là thứ cần được giám sát và quan tâm? Đó là các request vào/ra của hệ thống đối với user. Những hệ thống có thể có những bất thường từ những request như những cuộc tấn công mạng (Cyber-attack) qua giao thức HTTP, WebSocket,... Việc log lại những hành động đó giúp cho việc truy vết cũng như khắc phục những vấn đề xảy ra nhanh và hiệu quả nhất. Bài viết này mình sẽ cùng mọi người tập trung xây dựng mô hình tổng quan về việc quản lý logs (nhật kí) tập trung của hệ thống cũng như nhiều hệ thống lớn hiện nay đã và đang được áp dụng.
Đặt vấn đề
Một công ty G đang nắm giữ khoảng hơn 100 con servers vật lý (On-premise server), 20 con servers đám mây (Cloud-base server) với khoảng 500 hệ thống đang chạy và khoảng 2000 agents. Hãy thử nghĩ đến việc kiểm soát tất cả truy cập của các hệ thống hiện có của công ty G. Chưa kể những truy cập đó tương tác trực tiếp đến dữ liệu nhạy cảm (như thông tin khách hàng, người dùng, nhân viên,...) và những kẻ tấn công đều có thể khai thác dữ liệu từ việc gửi các request có chứa payload độc hại trực tiếp đến hệ thống của công ty G nhằm mục đích không chính đáng. Vậy việc quản lý tập trung requests của những hệ thống này có thực sự cần thiết ? Hệ thống giám sát ở đây đóng vai trò như những người theo dõi những tác động với hệ thống và sẽ đưa ra cảnh báo sớm nhất mỗi khi gặp sự cố hoặc khi bị tấn công mạng.
Tổng quan hệ thống
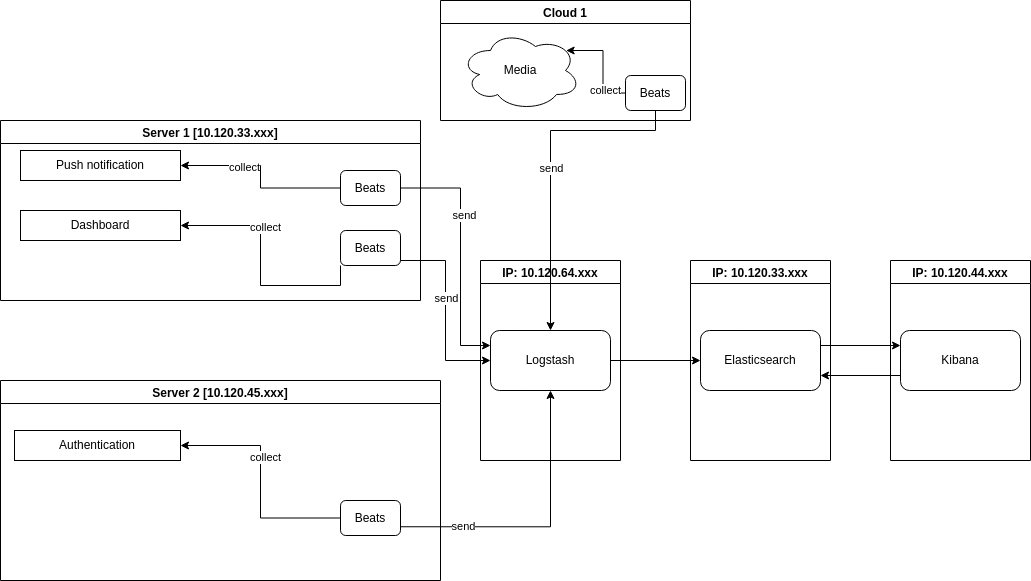
Giả định rằng các thực thể được phân tán trên các máy khác nhau. Mô hình trên giả định hệ thống được thiết kế theo kiến trúc microservice.
Modules:
- Authentication: Xử lý việc xác thực và phân quyền người dùng.
- Push notification: Gửi thông báo đến các user agent.
- Dashboard: Tính toán và thống kê theo dữ liệu hiện có.
Phân tích mô hình
Như đã thấy, mỗi một máy chủ được cài đặt Beats. Mỗi module là 1 beat instance. Beat instance thu thập tất cả request log files trong module đã được khai báo trong file cấu hình (filebeat.yml). Và gửi chúng qua Logstash.
Beats là người phân tích cú pháp gửi dữ liệu đến Elasticsearch (hoặc có thể là Logstash)
Vậy cách để Beat instance lấy được những requests từ các module sẽ được triển khai như nào ?
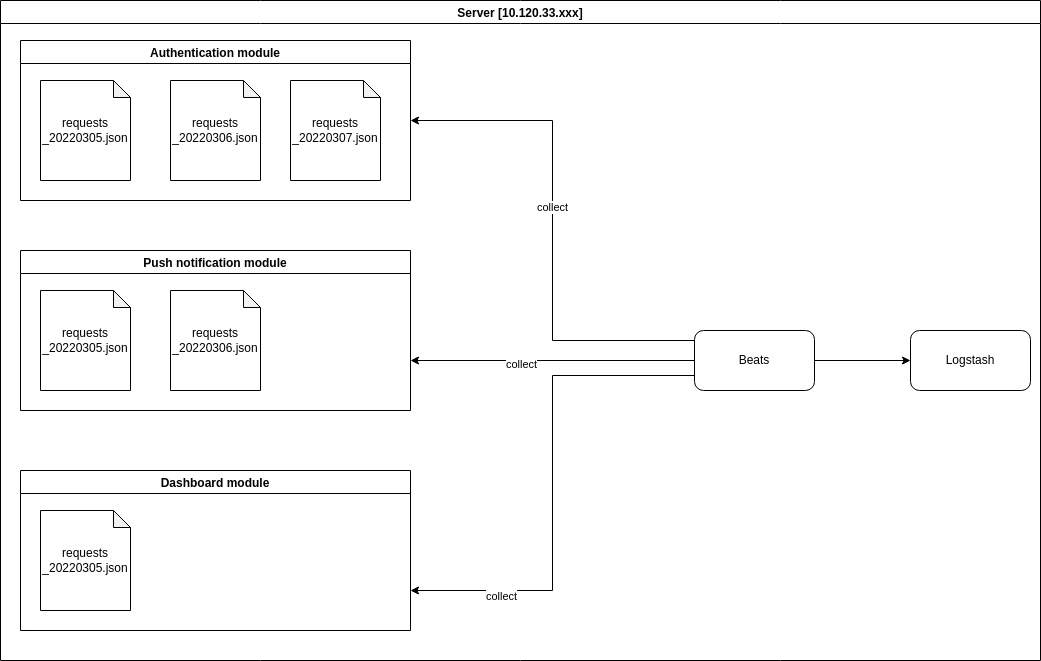
Tính cho đến thời điểm hiện tại thì Beats cung cấp các module cho các mục đích khác nhau. Trong trường hợp này mình sử dụng Filebeat để đọc dữ liệu logs từ file.
HÌnh trên mô tả cách hoạt động của Beats với module, Beats sẽ đọc dữ liệu được ghi lại từ file (có thể là file .log hoặc cũng có thể là .json) của module đó, tiếp đến phân tích cú pháp và gửi nó đến index của Elasticsearch. Mọi việc triển khai đều rất dễ dàng. Việc của chúng ta ở đây là ở trong module sẽ xây dựng một function để export từng request theo từng line ra file (hoặc có thể access và lưu trực tiếp logs trên production của nginx logs hoặc các web server tương tự, nhưng như thế sẽ khó để customize lại).
Vì khi module được chạy, access logs (tương tác của người dùng đến hệ thống) gần như là rất nhiều, nên việc lưu tất cả các log trong 1 file không phải cách tối ưu, vì có thể sau này những request log được lưu trước đó có thể sẽ không cần thiết với mục đích hiện tại. Một cron tab để quét theo folder và xóa đi những file log không còn mục đích sử dụng sẽ là một lựa chọn tốt. Vì vậy việc chọn phương án phân chia các file log theo các mốc thời gian hẳn rất là tuyệt vời, vừa tiện cho việc tra cứu những requests có trong ngày cụ thể, vừa dễ quản lý.
Cấu hình filebeat input:
# ============================== Filebeat modules ==============================
filebeat.inputs:
- type: log
enabled: true
tags: [authenticate]
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
json.expand_keys: true
paths:
- /home/vunv/logs/authenticate/*.json
- type: log
enabled: true
tags: [push-notification]
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
json.expand_keys: true
paths:
- /home/vunv/logs/push-notification/*.json
- type: log
enabled: true
tags: [dashboard]
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
json.expand_keys: true
paths:
- /home/vunv/logs/dashboard/*.json
# ===========================================================================
Tiếp theo hãy "zoom in" vào Logstash và để xem cách Logstash phân phát dữ liệu vào các index của Elasticsearch cluster như thế nào.
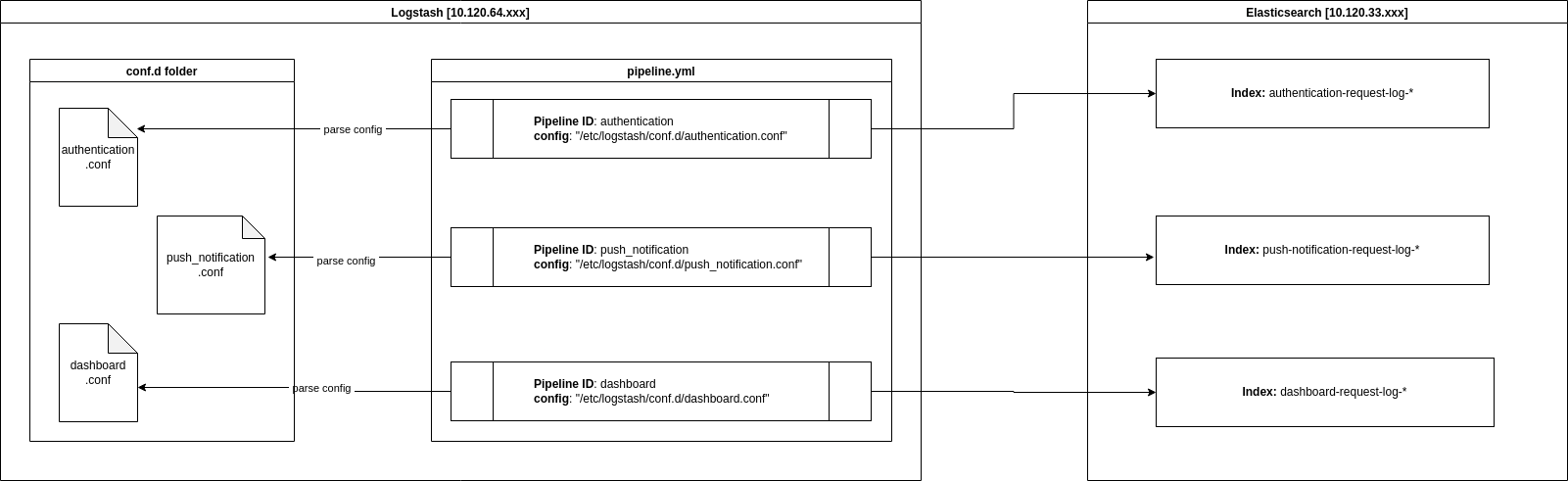
Trong Logstash, các tác vụ (task) được chia thành các pipeline. Mỗi pipeline sẽ đảm nhận những vai trò khác nhau, định nghĩa công việc cho một pipeline được cấu hình bằng file config. File config này định nghĩa input {}, output {} hoặc có thể có thêm filter {}. Trong đó:
- input {}: Khối này định nghĩa giữ liệu đầu vào, có thể là từ TCP. Nhưng trong trường hợp này sử dụng beats làm input instance. Port chỉ định ra việc pipeline này sẽ nhận input từ filebeat instance nào (dùng port để phân biệt các beat instance được cài đặt trong 1 máy). Ở đây có thể định nghĩa thêm plugin thay đổi các biểu diễn dữ liệu của sự kiện (codec)
- filter {}: Cũng giống như cái tên. Khối này thực hiện bộ lọc xử lý trung gian trên một sự kiện. Bộ lọc sẽ áp dụng những điều kiện đề parse những dữ liệu từ khối input {}
- output {}: Khối này quy định đầu ra tiêu chuẩn cho một quá trình xử lý luồng dữ liệu trong Logstash. Trong trường hợp này là Elasticsearch cluster, các dữ liệu được thu thập sẽ được phân phát về các index được khai báo trong config.
input {
beats {
port => 5044
codec => plain
}
}
filter {}
output {
elasticsearch {
hosts => ["https://localhost:9500"]
index => "authentication-%{+YYYY.MM.dd}"
cacert => "/etc/logstash/configs/client-ca.cer"
user => "logstash_internal"
password => "Secre!tKey@1447vunv"
}
}
Tóm lại, Logstash sẽ filter các logs được đẩy về, chuẩn hóa chúng theo codec và output đầu ra theo quy định (trong trường hợp này đầu ra là Elasticsearch cluster).
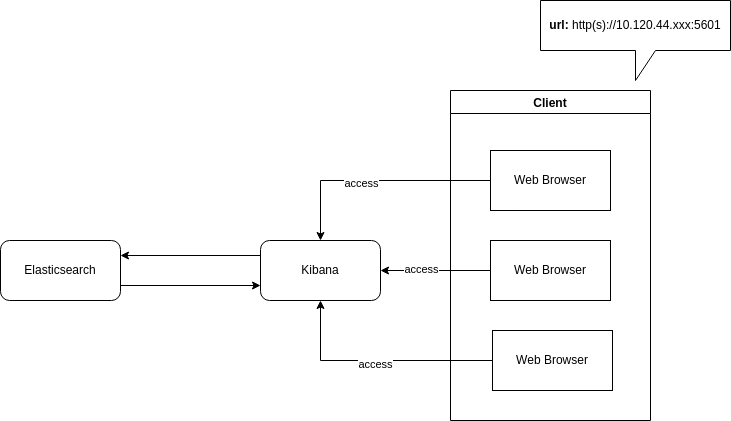
Kibana sẽ hiển thị những tài liệu theo bộ lọc hoặc thống kê và phân tích theo những data có sẵn ở trên Elasticsearch, mọi dữ liệu thống kê và phân tích sẽ được quan sát và nhìn thấy trên Kibana. Các máy có thể truy cập vào giao diện của Kibana thông qua port (mặc định là port 5601)
Ngoài ra ELK còn được tích hợp những công nghệ quản lý giúp quan sát những hoạt động đối với các ứng dụng hay hệ điều hành như APM (Quản lý và giám sát hiệu suất ứng dụng) hay SIEM (Hệ thống giám sát an ninh mạng) thông qua các agent (mình sẽ dành riêng 1 bài viết để nói về 2 công nghệ này).
Lời kết
Chắc hẳn mọi người đã quá quen với lệnh tail, mỗi khi cần check lại những requests đã được gửi đến cũng như kiểm tra bugs trên production. Việc đó sẽ khá dễ dàng nếu tất cả thành phần hệ thống tập trung ở một chỗ. Nhưng chuyện gì sẽ xảy ra nếu như những thành phần đó được phân tán khắp nơi, có thể trên cloud, có thể trên on-premise? Đến lúc đó sẽ cần phải ghi nhớ module đó được chạy trên máy nào. Từ đó sẽ dò theo module và kiểm tra. Việc check logs như thế thật sự không dễ dàng và hiệu quả. Và những hệ thống tập trung giám sát được triển khai. Nó sẽ giải quyết được những vấn đề đó.
Đây là một luồng hoạt động cơ bản của ELK Stack (đây cũng là mô hình đang được triển khai nhiều nhất) mọi thứ được mô tả ở đây đều rất thực tế và rõ ràng. Hi vọng có thể đem đến cho người đọc cái nhìn, tư duy và các giải pháp khi gặp những case tương tự.
Thân ái và quyết thắng.


