Các bạn có thể xem đầy đủ các phần tại đây nhé
Nếu các bạn chưa đọc bài trước có thể đọc tại link này Tăng tốc database index phần 5 -WHERE trên khóa chính
Mặc dù khóa chính được tạo index tự động, và ta biết nếu where theo khóa chính thì chạy rất nhanh rồi, nhưng nếu khóa chính lại bao gồm nhiều trường thì sao trường hợp này được gọi là concatenated index ( multi-column, composite hoặc combined index) thôi mình gọi là Index Kết Hợp cho nó dễ nhé. Nhưng khi tạo theo nhiều trường này có cần quan tâm thứ tự không, hay cần hai trường thì cứ add hai trường, ba trường thì cứ đánh index cho 3 trường không cần thứ tự gì cả? Đáp án là bạn cần rất cẩn thận khi đánh index có nhiều trường, vì thứ tự của nó rất quan trọng. Chi tiết mình sẽ giải thích bên dưới
Giả sử một ngày đẹp trời công ty của bạn sáp nhập thêm một công ty khác, dẫn tới số lượng nhân viên tăng lên gấp 10 lần. Nhưng có một vấn đề là EMPLOYEE_ID không còn là duy nhất nữa có có thể trùng ID của công ty vừa sáp nhập, giải pháp là thêm luôn một trường SUBSIDIARY_ID là ID của công ty con vào nữa để làm khóa chính. Bây giờ khóa chính sẽ gồm hai trường (EMPLOYEE_ID và SUBSIDIARY_ID) để đảm bảo duy nhất. Giả sử index cho khóa chính mới được tạo như sau
CREATE UNIQUE INDEX employees_pk
ON employees (employee_id, subsidiary_id)
Nếu cần tìm một nhân viên cụ thể thì bây giờ cần truy vấn theo cả hai trường ví dụ
SELECT first_name, last_name
FROM employees
WHERE employee_id = 123
AND subsidiary_id = 30
Vì đang sử dụng khóa chính đầy đủ trong điều kiện WHERE nên database sẽ sử dụng INDEX UNIQUE SCAN bất kể có bao nhiêu trường trong khóa chính đi nữa. Chỗ này chạy vẫn ngon, nhưng điều gì xảy ra khi ta chỉ truy vấn theo một trường trong khóa chính, ví dụ tìm tất cả nhân viên (employees) trong một công ty con (subsidiary)
SELECT first_name, last_name
FROM employees
WHERE subsidiary_id = 20
Với câu lệnh này xem trong execution plan thay vì sử dụng index database lại sử dụng TABLE ACCESS FULL nghĩa là nó duyệt hết các bản ghi trong bảng và so sánh với điều kiện WHERE. Độ phức tạp trong trường hợp này là tuyến tính, kích cỡ bảng tăng bao nhiêu thì câu query chậm bấy nhiêu. Nếu kích cỡ bảng tăng gấp 10 lần thì câu lệnh chạy chậm đi 10 lần. Sự nguy hiểm của kiểu truy vấn này lại ở chỗ lúc dev thì ôi chạy nhanh, môi trường dev em chạy chả làm sao mà ra môi trường product thì nó cứ chậm, em không thể nào tái lặp lại trên môi trường dev  .
.
Cái TABLE ACCESS FULL hay duyệt cả bảng này không phải lúc nào cũng xấu nhé! Nó có thể hiệu quả trong một số trường hợp ví dụ khi cần lấy phần lớn dữ liệu của bảng, kiểu không muốn lấy 1 bản ghi mà muốn lấy gần hết ấy, trường hợp đấy k cần index làm gì cho mệt lấy cả bảng cho nó nhanh. Trường hợp này chạy qua index còn chậm hơn bởi vì sao? Vì nó tốn thời gian look up trên index. Trên index cần đọc từng block trong bảng một, vì index không biết trước dữ liệu nằm ở trên block nào tiếp theo nếu chưa xử lý xong khối trước đó bạn nào chưa hiểu chỗ này xem lại bài Index chậm. Còn FULL TABLE SCAN phải lấy cả bảng nên database có thể đọc nhiều block cùng một lúc (multi block read) nên dù phải đọc nhiều dữ liệu hơn nhưng nó tốn ít thao tác đọc hơn. Ví dụ thế này dễ hiểu quyển sách của bạn nếu phải đọc cả quyển sách hoặc 99% quyền sách đi, nếu bản đọc từng cụ 10 trang một liền nhau (cái này máy nó đọc nhé) thì nhanh hơn ra mục lục dò vào đọc một trang, rồi lại ra mục lục dò vào đọc một trang sẽ bị chậm hơn vậy. Còn trường hợp đọc 1 trang thôi thì dò mục lục đọc nhanh hơn là phải duyệt qua tất cả trang sách rồi tìm đúng trang cần tìm.
Thôi quay lại cái index của chúng ta, rõ ràng trường hợp của chúng ta cần tìm bên trên không nên duyệt cả bảng làm gì cả, nên trường hợp này cần duyệt theo index thì tốt hơn. Nhưng tại sao index lại không ăn nhỉ? Trong trường hợp index gồm nhiều cột mà chỉ lấy một cột nó có ăn index không? Cấu trúc index dưới đây sẽ giải thích cho các bạn điều đó
Nhìn chung index kết hợp cũng vẫn là B-Tree để giữ các cục index được sắp xếp theo thứ tự như index 1 trường. Nhưng vì có hai trường nên database sắp xếp ưu tiên trường được đánh index đầu tiên trước (EMPLOYEE_ID) rồi sau đó sắp xếp tới các trường sau (SUBSIDIARY_ID). Cái này sắp sếp giống như trong danh bạ điện thoại Tên đứng trước, Họ đứng sau, thứ tự trường thứ hai chỉ có nếu trường thứ nhất có giá trị bằng nhau, nếu không về cơ bản sẽ không có thứ tự. Nghĩa là index không hỗ trợ tìm kiếm theo trường thứ hai, giống như việc tìm danh bạ theo HỌ vậy (cái này mình nói quyển danh bạ ngày xưa chứ giờ tra IPhone thì cái gì nó chả ra, hoặc ví dụ khác là các bạn tìm kiếm từ điển bằng chữ cái thứ hai vậy)
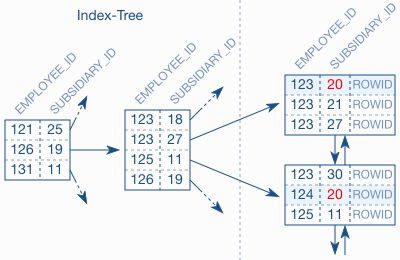
Hình trên mô tả cấu trúc của index kết hợp có thể thấy cục index subsdiary có giá trị 20 không hề nằm cạnh nhau. Cũng có thể thấy rằng không có cành nào tương ứng với cục có giá trị 20 này, dù trên lá thì có. Cây này không có tác dụng với câu truy vấn kiểu này.
Đương nhiên chúng ta có thể thêm index nữa cho riêng trường SUBSIDIARY_ID này để tăng tốc độ truy vấn. Tuy nhiên còn một cách tốt hơn nữa để tăng tốc đột truy vấn đặc biệt trong trường hợp truy vấn theo duy nhất trường (EMPLOYEE_ID) là không có ý nghĩa.
Ta thấy rằng index dùng cột đầu tiên để sếp thứ tự, nên chỉ cần tiptrick một chút đổi thứ tự hai cột được đánh index cho SUBSIDIARY_ID lên đầu
CREATE UNIQUE INDEX EMPLOYEES_PK
ON EMPLOYEES (SUBSIDIARY_ID, EMPLOYEE_ID)
Hai cột lúc này vẫn là Khóa chính, và nếu query theo cả hai trường vẫn có kết quả INDEX UNIQUE SCAN, nhưng thứ tự index bây giờ khác với lúc trước, SUBSIDIARY_ID được đưa lên đầu nó trở thành trường được ưu tiên sắp xếp trước, được đưa vào B-Tree, và các truy vấn với trường SUBSIDIARY_ID có thể dùng B-Tree để tìm kiếm.
Trong thực tế việc chọn index này trường nào nên trước nên được đánh giá cẩn thận để chọn được đúng thứ tự mà hay được sử dụng nhất
Execution plan dưới đây mô tả việc sử dụng index, vì SUBSIDIARY_ID không phải là duy nhất nên database phải tìm qua các leaf node để tìm kiếm tất cả kết quả phù hợp. Vì vậy nó sử dụng INDEX RANGE SCAN
MYSQL:
+----+-----------+------+---------+---------+------+-------+
| id | table | type | key | key_len | rows | Extra |
+----+-----------+------+---------+---------+------+-------+
| 1 | employees | ref | PRIMARY | 5 | 123 | |
+----+-----------+------+---------+---------+------+------
Mysql ref tương ứng với INDEX RANGE SCAN trong Oracle
Oracle:
---------------------------------------------------------------
|Id |Operation | Name | Rows | Cost |
---------------------------------------------------------------
| 0 |SELECT STATEMENT | | 106 | 75 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 106 | 75 |
|*2 | INDEX RANGE SCAN | EMPLOYEES_PK | 106 | 2 |
---------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("SUBSIDIARY_ID"=20)
SQL Server
|--Nested Loops(Inner Join)
|--Index Seek(OBJECT:employees_pk,
| SEEK:subsidiary_id=20
| ORDERED FORWARD)
|--RID Lookup(OBJECT:employees,
SEEK:Bmk1000=Bmk1000
LOOKUP ORDERED FORWARD)
Thông thường trong index kết hợp có thể dùng index để tìm kiếm theo Cột đầu tiên, hai cột đầu tiên ,n Cột đầu tiên, Tất cả các cột trong index. Mặc dù sử dụng hai index riêng cho hai cột cũng có hiệu năng tốt, nhưng sử dụng một index thì thích hợp hơn, nó không những tiết kiệm dung lượng lưu trữ mà còn tiết kiệm phí bảo trì cho index thứ hai. Một bảng càng ít index các thao tác Insert, Delete, Update chạy càng nhanh
Để có thể tối ưu được index không những bạn phải hiểu cách hoạt động của index, mà còn phải hiểu cách truy vấn dữ liệu của ứng dụng nữa để biết được cần where theo trường gì từ đấy đánh index cho phù hợp, kẻo chỗ cần đánh không đánh, chỗ không cần đánh lại đánh.
Vì vậy nếu một chuyên gia, hay ai đó cần tư vấn cách đánh index mà không hiểu nghiệp vụ chương trình là rất khó, họ thường chỉ đánh giá được một truy vấn mà không đánh giá được toàn bộ chương trình để có thể đánh index hợp lý cho những truy vấn khác nữa. Ông DBA cũng vậy vì ông ấy hiểu về db nhưng nếu không hiểu nghiệp vụ thì cũng không tối ưu được.
Nên vai trò các bạn dev trong trường hợp này rất quan trọng, vừa hiểu nghiệp vụ vừa hiểu các luồng dữ liệu, lại nắm được cấu trúc database nên việc tìm các trường cần đánh index mang lại hiệu quả cao dễ hơn nhiều. Hy vọng sau những bài viết của mình các bạn dev có khả năng nâng cao hiệu năng chương trình tốt hơn, vì vai trò các bạn trong trường hợp này quan trọng hơn các chuyên gia bên ngoài. Happy Coding!
Link bài sau Tăng tốc database index phần 7 -Index chậm 2


