Index là gì?
Index - chỉ mục (còn được gọi là "key" trong MySQL) là cấu trúc dữ liệu mà các công cụ lưu trữ sử dụng để tìm kiếm một cách nhanh chóng. Index rất quan trọng để có hiệu suất tốt, nhất là đối với dữ liệu lớn. Đối với cơ sở dữ liệu nhỏ thì có thể họat động tốt ngay cả khi không có index, nhưng khi dữ liệu ngày càng phát triển lớn hơn thì hiệu suất có thể giảm rất nhanh.
Indexing cơ bản
Cách dễ nhất để hiểu cách một chỉ mục hoạt động trong MySQL là suy nghĩ về mục lục trong một cuốn sách. Để biết vị trí một chủ đề cụ thể được thảo luận trong một cuốn sách, bạn nhìn vào mục lục và nó cho bạn biết (các) số trang nơi thuật ngữ đó xuất hiện.
Công cụ lưu trữ trong MySQL cũng sử dụng chỉ mục theo cách tương tự. Nó tìm kiếm cấu trúc dữ liệu của chỉ mục để tìm một giá trị. Khi tìm thấy kết quả phù hợp, nó có thể tìm thấy hàng có chứa kết quả phù hợp. Giả sử bạn chạy câu truy vấn sau đây:
mysql> SELECT first_name FROM users WHERE user_id = 5;
Có một chỉ mục trên cột user_id, vì vậy MySQL sẽ sử dụng chỉ mục để tìm các hàng có user_id là 5. Nói cách khác, nó thực hiện tra cứu các giá trị trong chỉ mục và trả về bất kỳ hàng nào có chứa giá trị được chỉ định.
Chỉ mục có thể chứa các giá trị từ một hoặc nhiều cột trong bảng, vì vậy nếu bạn lập chỉ mục nhiều hơn một cột, thứ tự cột rất quan trọng, vì MySQL chỉ có thể tìm kiếm hiệu quả trên tiền tố ngoài cùng bên trái của chỉ mục.
Các loại index
Có nhiều loại chỉ mục được thiết kế cho các mục đích khác nhau. Các chỉ mục được thực hiện trong lớp lưu trữ, không phải lớp server. Do đó, chúng không được tiêu chuẩn hóa: việc lập chỉ mục hoạt động khác nhau trong mỗi công cụ và không phải tất cả các công cụ đều hỗ trợ tất cả các loại chỉ mục. Ngay cả khi nhiều công cụ hỗ trợ cùng một loại chỉ mục, chúng có thể triển khai nó theo cách khác nhau.
B-Tree index
B-Tree index sử dụng cấu trúc dữ liệu B-Tree để lưu trữ dữ liệu, đây là loại chỉ mục thường được sử dụng trong hầu hết các công cụ lưu trữ dữ liệu của MySQL. Ý tưởng chung của B-Tree là tất cả các giá trị được lưu trữ theo thứ tự và mỗi trang lá có cùng khoảng cách từ gốc.
Một chỉ mục được xây dựng dựa trên cấu trúc B-Tree:
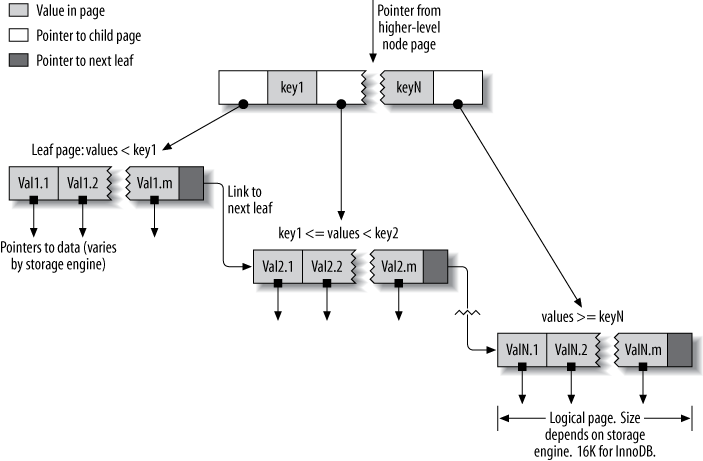
Chỉ mục B-Tree tăng tốc độ truy cập dữ liệu vì công cụ lưu trữ không phải quét toàn bộ bảng để tìm dữ liệu mong muốn. Thay vào đó, nó bắt đầu ở nút gốc (không được hiển thị trong hình trên). Các vị trí trong nút gốc giữ các con trỏ đến các nút con và công cụ lưu trữ tuân theo các con trỏ này. Nó tìm đúng con trỏ bằng cách xem các giá trị trong các trang nút, xác định giới hạn trên và giới hạn dưới của các giá trị trong các nút con. Cuối cùng, công cụ lưu trữ xác định rằng giá trị mong muốn không tồn tại hoặc đến trang lá thành công.
Vì B-Tree lưu trữ các cột được lập chỉ mục theo thứ tự, chúng hữu ích cho việc tìm kiếm các dữ liệu trong một phạm vi. Ví dụ: sắp xếp giảm dần cây dữ liệu của chỉ mục trên một trường văn bản theo thứ tự bảng chữ cái thì ta có thể tìm kiếm một cách hiệu quả “mọi người có tên bắt đầu bằng I đến K”.
Giả sử ta có bảng sau:
CREATE TABLE People (
last_name varchar(50) not null,
first_name varchar(50) not null,
dob date not null,
gender enum('m', 'f')not null,
key(last_name, first_name, dob)
);
Chỉ mục sẽ chứa các giá trị từ các cột last_name, first_name và dob cho mọi hàng trong bảng. Hình sau minh họa cách chỉ mục sắp xếp dữ liệu mà nó lưu trữ.
 Lưu ý rằng chỉ mục sắp xếp các giá trị theo thứ tự của các cột được khai báo trong chỉ mục ở câu lệnh CREATE TABLE. Nhìn vào hai mục cuối cùng: có hai người trùng tên nhưng khác ngày sinh và họ được sắp xếp theo ngày sinh.
Lưu ý rằng chỉ mục sắp xếp các giá trị theo thứ tự của các cột được khai báo trong chỉ mục ở câu lệnh CREATE TABLE. Nhìn vào hai mục cuối cùng: có hai người trùng tên nhưng khác ngày sinh và họ được sắp xếp theo ngày sinh.
Các loại truy vấn có thể sử dụng chỉ mục B-Tree
1. Tìm kiếm khớp với giá trị đầy đủ
Tìm kiếm với giá trị khóa đầy đủ trong các giá trị được chỉ định cho tất cả các cột trong chỉ mục. Ví dụ: với chỉ mục ở trên có thể giúp ta tìm một người tên là Cuba Allen, sinh ngày 1960-01-01.
2. Tìm kiếm khớp với tiền tố ngoài cùng bên trái
Chỉ mục này có thể giúp bạn tìm tất cả những người có họ là Allen. Điều này chỉ sử dụng cột đầu tiên trong chỉ mục.
3. Tìm kiếm khớp với tiền tố cột
Ta có thể tìm kiếm trên phần đầu tiên trong giá trị của cột. Chỉ mục này có thể giúp bạn tìm tất cả những người có họ bắt đầu bằng J. Điều này chỉ sử dụng cột đầu tiên trong chỉ mục.
4. Tìm kiếm khớp với một khoảng giá trị
Chỉ mục này có thể giúp bạn tìm những người có họ nằm giữa Allen và Barrymore. Điều này cũng chỉ sử dụng cột đầu tiên.
5. Tìm kiếm khớp chính xác một phần và khớp với một khoảng giá trị của một phần khác
Chỉ mục này có thể giúp bạn tìm mọi người có họ là Allen và tên bắt đầu bằng chữ K (Kim, Karl, v.v.). Đây là một kết hợp chính xác trên last_name và một truy vấn khoảng giá trị trên first_name.
6. Truy vấn chỉ lập chỉ mục
Các chỉ mục B-Tree thường có thể hỗ trợ các truy vấn chỉ lập chỉ mục, là các truy vấn chỉ truy cập vào chỉ mục, không phải lưu trữ hàng.
Vì các nút của cây được sắp xếp nên chúng có thể được sử dụng cho cả truy vấn tra cứu (tìm giá trị) và ORDER BY (tìm kiếm giá trị theo thứ tự đã sắp xếp)
Một số hạn chế của chỉ mục B-Tree:
- Chúng không hữu ích nếu tra cứu không bắt đầu từ phía ngoài cùng bên trái của các cột được lập chỉ mục.
- Bạn không thể bỏ qua các cột trong chỉ mục.
- Công cụ lưu trữ không thể tối ưu hóa quyền truy cập với bất kỳ cột nào ở bên phải của điều kiện phạm vi (range condition) đầu tiên. Ví dụ: nếu truy vấn của bạn là
WHERE last_name="Smith" AND first_name LIKE 'J%' AND dob='1976-12-23'quyền truy cập chỉ mục sẽ chỉ sử dụng hai cột đầu tiên trong chỉ mục, vì LIKE là một điều kiện phạm vi.
Bây giờ chúng ta có thể thấy tại sao thứ tự cột là cực kỳ quan trọng: những hạn chế này đều liên quan đến thứ tự cột. Để có hiệu suất tối ưu, bạn có thể cần tạo các chỉ mục với các cột giống nhau theo các thứ tự khác nhau để đáp ứng các truy vấn của mình.
Hash indexes
Chỉ mục băm được xây dựng trên bảng băm và chỉ hữu ích cho các tra cứu chính xác sử dụng mọi cột trong chỉ mục. Đối với mỗi hàng, công cụ lưu trữ tính toán mã băm của các cột được lập chỉ mục, đây là một giá trị nhỏ có thể sẽ khác nhau với các hàng có giá trị khóa khác nhau. Nó lưu trữ các mã băm trong chỉ mục và lưu một con trỏ đến từng hàng trong bảng băm.
Trong MySQL, chỉ công cụ lưu trữ Memory hỗ trợ các chỉ mục băm rõ ràng. Chúng là loại chỉ mục mặc định cho bảng Memory, mặc dù bảng Memory cũng có thể có chỉ mục B-Tree.
Ví dụ về chỉ mục băm, ta có bảng sau:
CREATE TABLE testhash (
fname VARCHAR(50) NOT NULL,
lname VARCHAR(50) NOT NULL,
KEY USING HASH(fname)
) ENGINE=MEMORY;
Chứa dữ liệu như sau:
| fname | lname |
|---|---|
| Arjen | Lentz |
| Baron | Schwartz |
| Peter | Zaitsev |
| Vadim | Tkachenko |
Bây giờ, giả sử chỉ mục sử dụng một hàm băm ảo được gọi là f(), trả về các giá trị sau (đây chỉ là các ví dụ, không phải giá trị thực):
f('Arjen')= 2323
f('Baron')= 7437
f('Peter')= 8784
f('Vadim')= 2458
Cấu trúc dữ liệu của chỉ mục sẽ giống như sau, chú ý là giá trị slot được sắp xếp nhưng giá trị pointer thì không:
| Slot | Value |
|---|---|
| 2323 | Pointer to row 1 |
| 2458 | Pointer to row 4 |
| 7437 | Pointer to row 2 |
| 8784 | Pointer to row 3 |
Tìm kiếm với câu lệnh mysql> SELECT lname FROM testhash WHERE fname='Peter';
MySQL sẽ tính toán mã băm của 'Peter' và sử dụng nó để tra cứu con trỏ trong chỉ mục. Vì f('Peter') = 8784, MySQL sẽ tìm chỉ mục cho 8784 và tìm con trỏ đến hàng 3. Bước cuối cùng là so sánh giá trị ở hàng 3 với 'Peter', để đảm bảo nó đúng.
Những hạn chế của chỉ mục băm:
- Vì chỉ mục chỉ chứa mã băm và con trỏ hàng thay vì lưu các giá trị, nên MySQL không thể sử dụng các giá trị trong chỉ mục để tránh việc đọc các hàng.
- MySQL không thể sử dụng chỉ mục băm để sắp xếp vì chúng không lưu trữ các hàng theo thứ tự được sắp xếp.
- Chỉ mục băm không hỗ trợ tìm kiếm với khóa từng phần, vì chúng tính toán băm từ toàn bộ giá trị được lập chỉ mục.
- Chỉ mục băm chỉ hỗ trợ so sánh bằng sử dụng các toán tử =, IN () và <=> (lưu ý rằng <> và <=> không phải là cùng một toán tử).
- Việc truy cập dữ liệu trong một chỉ mục băm rất nhanh chóng, trừ khi có nhiều giá trị có cùng một hàm băm.
- Một số hoạt động bảo trì chỉ mục có thể chậm nếu có nhiều xung đột (có nhiều giá trị có cùng một hàm băm).
Những hạn chế này làm cho chỉ mục băm chỉ hữu ích trong những trường hợp đặc biệt. Tuy nhiên, khi phù hợp với nhu cầu của ứng dụng, chúng có thể cải thiện đáng kể hiệu suất.
Chỉ mục không gian (R-Tree)
Không giống như chỉ mục B-Tree, chỉ mục không gian không yêu cầu mệnh đề WHERE hoạt động trên tiền tố ngoài cùng bên trái của chỉ mục. Chúng lập chỉ mục dữ liệu theo tất cả các thứ nguyên cùng một lúc. Do đó, các tra cứu có thể sử dụng bất kỳ tổ hợp thứ nguyên nào một cách hiệu quả. Tuy nhiên, bạn phải sử dụng các hàm GIS của MySQL, chẳng hạn như MBRCONTAINS() để làm điều này và hỗ trợ GIS của MySQL không hỗ trợ tốt nên hầu hết mọi người không sử dụng nó. Giải pháp tối ưu là sử dụng GIS trong RDBMS mã nguồn mở là PostGIS trong PostgreSQL.
Full-text indexes
FULLTEXT là một loại chỉ mục đặc biệt giúp tìm các từ khóa trong văn bản thay vì so sánh các giá trị trực tiếp với các giá trị trong chỉ mục. Full-text search hoàn toàn khác với các loại tìm kiếm khác, nó linh hoạt hơn ví dụ như có thể tìm kiếm với từ khóa mơ hồ, từ gốc, từ số nhiều, hay tìm kiếm giá trị Boolean. Nó giống với một công cụ tìm kiếm hơn là chỉ đơn giản là tìm kiếm giá trị matching với mệnh đề WHERE. Việc có một chỉ mục full-text trên một cột không loại bỏ giá trị của một chỉ mục B-Tree trên cùng một cột.
Lợi ích của chỉ mục
Chỉ mục không chỉ cho phép máy chủ điều hướng nhanh chóng đến vị trí mong muốn trong bảng mà còn có những lợi ích khác dựa trên các thuộc tính của cấu trúc dữ liệu được sử dụng để tạo chúng.
Chỉ mục B-Tree, là loại phổ biến nhất mà bạn sẽ sử dụng, hoạt động bằng cách lưu trữ dữ liệu theo thứ tự được sắp xếp và MySQL có thể khai thác điều đó cho các truy vấn có mệnh đề như ORDER BY và GROUP BY. Bởi vì dữ liệu được sắp xếp trước, chỉ mục B-Tree cũng lưu trữ các giá trị liên quan gần nhau. Cuối cùng, chỉ mục thực sự lưu trữ một bản sao của các giá trị, vì vậy một số truy vấn có thể được thỏa mãn chỉ từ chỉ mục. Ba lợi ích chính thu được từ những tính chất này là:
- Các chỉ mục làm giảm lượng dữ liệu mà máy chủ phải kiểm tra.
- Các chỉ mục giúp máy chủ tránh sắp xếp và các bảng tạm thời.
- Các chỉ mục biến I / O ngẫu nhiên thành I / O tuần tự.



