Bài toán
Kết thúc tháng 4, kết thúc lời nói dối của em. So deep...! Tôi chợt nhớ ra còn nhiệm vụ đã đặt ra là phải cố gắng viết bài để nhận áo trong sự kiện MayFest của viblo trong tháng 5 này. Vậy là tôi hì hục đi tìm ý tưởng cho bài viết. Trong lúc túng quẫn tôi chợt nhớ về 1 task tôi đã được giao vào tuần qua liên quan đến việc upload file. Spec bài toán như sau:
Upload 1 file có đuôi .zip chứa 1 danh sách ảnh. Sau đó lưu danh sách ảnh này lên S3. Kích thước tối đa của ảnh là 10MB. Số lượng ảnh tối đa 700 ảnh trên mỗi file đuôi .zip
Nghe cứ sai sai kiểu gì đấy. Cùng đi vào phân tích nhé 
Phân tích
Đầu tiên chúng ta sẽ đọc lại spec 1 lần nhé: Upload 1 file có đuôi .zip chứa 1 danh sách ảnh. Ơ khoan, hình như chúng ta chưa có kích thước tối đa của file zip (hoanghot), note lại đã.
Kích thước ảnh tối đã là 10MB và 700 ảnh / file.
700 * 10 = 7000MB ~ 6,52 GB. Ôi mai gót !
Như này thì server nào chịu tải cho nổi. Đến đây tôi lại quay về vấn đề vừa note ở trên kích thước tối đa của file zip. Cần confirm ngay lại thông tin này với KH để đưa ra hướng giải quyết.
Sau 1 thời gian contact giải thích về tính khả thi thì KH có chốt lại như sau:
Mày yên tâm. Tao để cho zui hoy chứ ko nặng đến thế đâu. Chắc cũng chỉ tầm 300MB thôi. Tôi thì thấy cũng vui thật, miệng cười nhưng lệ đổ trong tym :3. Quay lại với bài toán,
300MB khi unzip thì sẽ có dụng lượng tương đương với khoảng 400MB. Tức là rơi vào khoảng 40 ảnh, thế mà doạ nhau vãi (yaoming).
Đến đây lại xảy ra vấn đề như sau :
- Có hiện tượng nhiều user upload file tại cùng 1 thời điểm ko ?
- Quản lý log
Chúng tôi đang confirm thêm về 2 thông tin trên nhưng tôi vẫn thử đưa ra cách xử lý cho 2 vấn đề trên.
Tìm giải pháp
Sử dụng AWS
Đầu tiên nếu có nhiều user xử lý cũng một lúc, nghe khá ối zồi ôi. Nhưng thôi bạn thích thì để tôi nghĩ cách. Tôi bắt đầu tham khảo các cao nhân thì được cho hay: "Dùng aws đi em ơi. Tốn tiền tý nhưng khá là sịn  ".
Vâng tôi bắt đầu công cuộc gg sợt và thấy 1 mô hình khá hay như sau:
".
Vâng tôi bắt đầu công cuộc gg sợt và thấy 1 mô hình khá hay như sau:
Xem chi tiết tại đây.
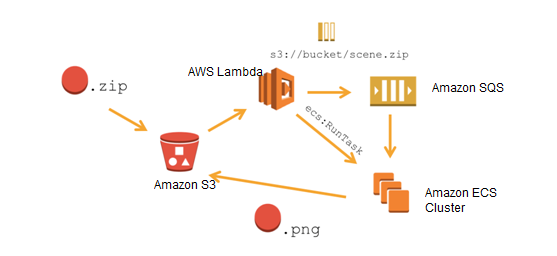
Đầu tiên chúng ta cùng phân tích những thành phần trong mô hình nhé. Tôi xin phép giải thích theo ý hiểu của tôi nhé.
- S3: Hiểu đơn giản thì nó là 1 nơi lưu trữ dạng như driver hay icloud vại.
- ECS Cluster: Hiểu đơn giản là 1 con server riêng biệt.
- SQS: Là 1 hệ thống hàng chờ, được aws giới thiệu là khá nhanh.
- Lambda: Nơi mà mình có thể viết các function để connect và xử lý các sự kiện liên quan đến hệ sinh thái của aws.
Góc nhẹ tay: Xin rõ chút tôi là 1 thằng cốt PHP đọc tài liệu nôm na rồi chém gió về cách triển khai hệ thống. Nên có gì sai sót thì mong ae giơ cao đánh khẽ nhé  .
.
Bây giờ tôi sẽ giải thích 1 chút về luồng hoạt động cuả mô hình trên nhé.
- Đầu tiên user sẽ upload file .zip trực tiếp lên S3.
- S3 sẽ kích hoạt Lambda.
- Lambda kích hoạt hàng chờ SQS.
- ECS sẽ hứng thông báo từ hàng chờ SQS, sau đó thực hiện tác vụ unzip, validation, lưu DB.
- Cuối cùng sẽ là upload file lên S3.
Tôi đang hiểu trong tài liệu thì đang dồn khá nhiều công việc nặng cho ECS. Nhưng chúng ta hoàn toàn có thể thay đổi 1 chút. Sau khi hoàn thành bước 4. Chúng ta có thể trigger tới lambda. Tạo ra 1 hàng chờ SQS khác để phục vụ việc lưu file .png vào S3.
Vậy là bài toán của mình đã được giải quyết bằng tiền =)). Về cơ bản thì mô hình này nhằm giải quyết 3 vấn đề lớn:
- Giảm tải cho server
- Các service của AWS như SQS,.. được quảng cáo là nhanh, rất nhanh hơn ro với phương pháp thủ công là thông qua tầng server.
- Dễ dàng scale hệ thống.
Xử lý trên server
Trong trường hợp chẳng có nhiều user, hay nói đúng hơn là tại 1 thời điểm chỉ có 1 user upload và tác vụ này cũng không xảy ra thường xuyên. Thì ta lại quay về với phương án để server xử lý. Đầu tiền ta upzip trên server, sau đó tạo job có tác vụ upload lên s3 là lưu lại đường dẫn vào trạng thái vào DB. Tuỳ và độ trâu bò của server mà ta có thể setting số lượng process nhé.
Quản lý log
Ưu điểm của queue luôn là phản hồi nhanh, tăng trải nghiệm người dùng. Nhưng làm bạn biết đấy làm gì có thứ gì hoàn hảo. Queue job luôn là tồn tại những vấn đề về quản lý lỗi,...cả tỷ tỷ thứ. Trong khả năng và thời lượng của chương trình thì tôi sẽ giới thiệu cho các bạn một cách quản lý bằng cách lưu vaò DB.
Đầu tiên ta sẽ tạo 2 bảng trong DB lần lượt là Queues, Jobs.
- Bảng Queues sẽ lưu thông tin như queue_name, status, number_job,start_time,...
- Bảng Jobs sẽ lưu thông tin như status, error,...
Mỗi lần ta start 1 tác vụ thì ta sẽ tạo mới một bản ghi tương ứng trong bảng Queues. Tương tự mỗi lần xong 1 jobs thì mình lại tạo mới 1 bản ghi trong bảng Jobs. Đến đây có 1 sai lầm thường gặp là các bạn sẽ đếm jobs rồi update trạng thái của bảng Queues. Nhưng cách tốt nhất là các bạn nên tạo 1 command để query đếm số lượng job trong DB, đếm số lượng jobs rồi update trạng thái vào DB. Tại sai ư? Bởi vì các queues thường đc setting chạy nhiều process tuỳ thuộc vào độ trâu của server. Về cơ bản thì nó sẽ làm có job của bạn được chay song song trên nhiều thread khác nhau. Nhưng nó lại dẫn đến lượng truy cập vào DB tăng đột ngột và deadlock là 1 vấn đề có thể xảy ra.
Chốt tộ
Quay về với thực tại thì khách hàng đã báo rằng không có cái trường hợp nhiều users đó đâu. Và file .zip đã giảm xuống còn 250MB tức là 400MB khi giải nén. Thật là ối dzồi ôi =)). Tôi hi vọng thông qua ví dụ này sẽ giúp các bạn đỡ bỡ ngỡ khi làm việc với bài toán upload nói chung và upload dữ liệu lớn nói riêng. Cảm ơn các bạn đã đọc (bow)



