Đây có lẽ sẽ là bài viết nhiều lí thuyết nhất trong series và cũng là bài viết với mình là khó và đau đầu để hiểu nhất 😑. Mong các bạn có thể hiểu với cách diễn đạt của mình.
Trong chương trước, chúng ta đã lấy mã nguồn thô dưới dạng một chuỗi và chuyển nó thành một loại biểu diễn cấp cao hơn một chút: một chuỗi các token. Trình phân tích cú pháp (Parser) mà chúng ta sẽ viết trong chương tiếp theo lấy các token đó và biến đổi chúng một lần nữa, thành một biểu diễn thậm chí còn phong phú hơn, phức tạp hơn.
Trước khi thực hiện biểu diễn token, chúng ta cần biết nó là gì. Đó là mục tiêu của bài viết này. Biểu diễn mã, nó phải đơn giản để trình phân tích cú pháp tạo ra và dễ dàng cho trình thông dịch sử dụng tốt. Nếu bạn chưa thực hiện viết trình thông dịch hay trình phân tích cú pháp nào, yêu cầu này sẽ hơi trừu tượng với bạn. Hãy thử đặt mình vào tình huống sau với trình thông dịch chính là bộ não của chúng ta và xử lí phép toán này như thế nào:
1 + 2 * 3 - 4
Bởi vì bạn biết các quy tắc ưu tiên của phép nhân chia cộng trừ. Một cách biểu thị sự ưu tiên thực hiện phép toán đó là sử dụng mô hình cây. Với nút là các số, ở giữa hai nút là toán hạng.
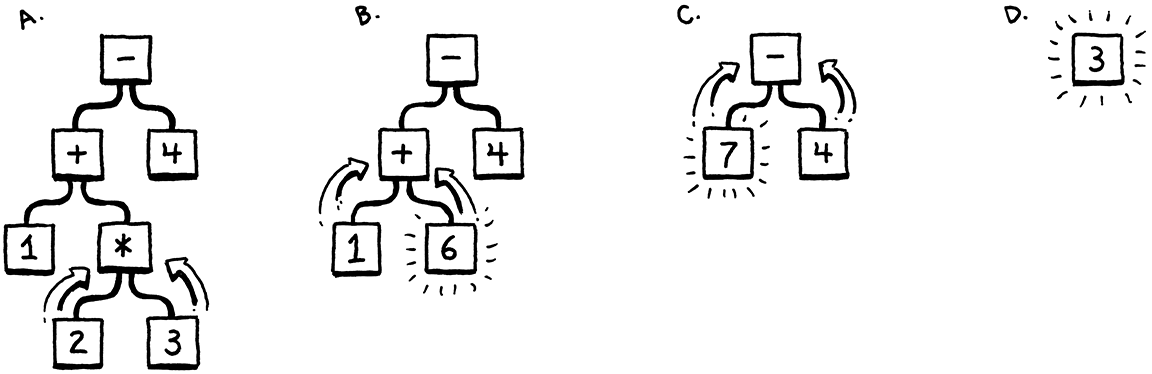
Source: craftinginterpreters.com
Để đánh giá một nút số học, bạn cần biết các giá trị số của các cây con của nó, vì vậy bạn phải đánh giá những giá trị đó trước tiên. Điều đó có nghĩa là làm việc theo cách của bạn từ lá đến gốc — một trình tự duyệt sau:
- Bắt đầu với toàn bộ cây lớn, đánh giá phép toán ở dưới cùng: 2 * 3.
- Sau đó thực hiện phép cộng +.
- Tiếp theo thực hiện tiếp phép -.
- Nhận được đáp án.
Ok, bây giờ nếu mình có đưa ra bất kì phép toán nào chắc hẳn các bạn cũng dễ dàng biểu thị nó dưới dạng cây. Như vậy, có lẽ đây là một cách biểu diễn mã phù hợp, một cấu trúc ngữ pháp với các toán tử lồng nhau của ngôn ngữ.
Context-free Grammar
Context-free grammars (CFG) là tập hợp các quy tắc nhằm mô tả tất cả các chuỗi câu có thể hình thành trong một ngôn ngữ nhất định. Nói một cách khác, CFG mô tả quan điểm cho rằng các câu văn trong một ngôn ngữ bất kỳ đều được tạo ra bởi một tập hợp các quy tắc và các câu văn sai ngữ pháp không thể được tạo ra bởi tập hợp quy tắc này. Từ ‘Context Free’ có nghĩa là các từ trong câu được tạo ra không phụ thuộc vào ngữ cảnh và không có mối liên hệ với môi trường xung quanh.
Như vậy một CFG chứa một danh sách các "chữ cái" và qua một bảng quy tắc xác định ta sẽ phân tích được thành một danh sách các "chuỗi" có nghĩa.
Như bài trước, với đầu vào xác định dựa vào một bộ quy tắc nhất định ta đã có thể tạo ra một danh sách các token. Trình phân tích cú pháp cũng như vậy, dựa trên bộ quy tắc mà ta chuẩn bị đưa ra nó sẽ chuyển Token sang dạng một chuỗi biểu thức, để dễ hình dung chúng ta có bảng sau:
| Thuật ngữ | Ngữ pháp từ vựng | Ngữ pháp cú pháp |
|---|---|---|
| "Chữ cái" trong CFG là ... | Kí tự | Token |
| "chuỗi" trong CFG là ... | Token | Biểu thức |
| Được thực hiện bởi ... | Scanner | Parser |
Xác định quy tắc cho ngữ pháp
Làm cách nào để chúng ta viết ra một ngữ pháp có chứa vô số chuỗi hợp lệ? Rõ ràng là chúng ta không thể liệt kê hết chúng. Thay vào đó, chúng ta tạo ra một bộ quy tắc hữu hạn. Tưởng tượng như bạn đang chơi trò chơi ghép hình lego vậy.
Có hai loại "chữ cái" trong CFG, đó là:
- "chữ cái" cuối cùng là chữ cái đó không phân rã được thêm nữa. Và chúng ta sẽ gọi tắt là T (Terminal)
- "chữ cái" danh nghĩa là chữ cái đại diện cho một hoặc một loạt các "chữ cái" cuối cùng. Có thể coi như là một "biệt danh" của chuỗi các T liên quan đến nhau, hay gọi tắt là NT (Nonterminal)
Để minh họa, mình sẽ lấy một ví dụ trong câu tiếng việt có cú pháp như này:
"tôi "muốn" "ăn" đồ_ăn thương_hiệu độ_chín
Mỗi từ ở trong ngoặc chính là một T. còn ba từ đồ_ăn , thương_hiệu và độ_chín chính là NT, với độ_chín ta sẽ suy ra một T ví dụ như "sống", "tái", "chín vừa" và "chín".
Ta có một bộ quy tắc như sau cho mẫu câu này:
mẫu_câu => "tôi "muốn" "ăn" đồ_ăn thương_hiệu độ_chín
đồ_ăn => "thịt bò" | "thịt lợn" | "thịt gà" | "tôm"
thương_hiệu => "siêu thị" | "nhà hàng 5 sao" | "chợ Mơ"
độ_chín => "sống" | "tái" | "chín vừa" | "chín"
Một câu được ghép từ bộ quy tắc này như sau:
tôi muốn ăn thịt bò chợ Mơ tái
Như chúng ta thấy, một NT có thể suy ra nhiều T khác nhau tùy từng trường hợp, kí hiệu | trong bảng quy tắc ý nghĩa là hoặc. Mẫu câu này nhìn chung thì đã có nghĩa nhưng đôi lúc chúng ta chỉ cần nói món đồ_ăn muốn ăn mà không cần nói ra thương_hiệu và độ_chín của món ăn. Chúng ta cập nhật bảng quy tắc như sau:
mẫu_câu => "tôi "muốn" "ăn" đồ_ăn (thương_hiệu)? (độ_chín)?
đồ_ăn => "thịt bò" | "thịt lợn" | "thịt gà" | "tôm"
thương_hiệu => "siêu thị" | "nhà hàng 5 sao" | "chợ Mơ"
độ_chín => "sống" | "tái" | "chín vừa" | "chín"
Cách mà mình kí hiệu quy tắc dựa trên RegExp, bạn có thể tìm hiểu thêm tại đây Regexp. Kí hiệu ? biểu thị NT đó có thể xuất hiện 0 hoặc 1 lần trong câu đó. Và giờ với bộ ngữ pháp mới, câu Tôi muốn ăn tôm hay Tôi muốn ăn tôm chín đã hợp lệ.
Quy tắc ngữ pháp của ViL
Ở chương trước việc triển khai bộ quy tắc của Scanner đơn giản chỉ trong một bài viết, nhưng vì Parser của chúng ta có rất rất nhiều quy tắc mà việc triển khai tất cả trong một bài viết sẽ rất khó để nghiền ngẫm toàn bộ trước khi chúng ta thực sự bắt đầu và chạy trình thông dịch của mình.
Thay vào đó, chúng ta sẽ xem xét một tập hợp con của ngôn ngữ trong một vài bài viết tiếp theo. Một khi chúng ta có ngôn ngữ nhỏ đó được đại diện, phân tích cú pháp và thông dịch, thì các bài viết sau sẽ dần dần thêm các tính năng mới vào nó, bao gồm cả cú pháp mới. Hiện tại, chúng ta chỉ quan tâm về một số các biểu thức chính (expression):
- Literals. số, chuỗi, kiểu logic, và rỗng.
- Unary expressions. Kí hiệu
!đổi trạng thái kiểu logic và kí hiệu để-đổi dấu kiểu số. - Binary expressions. Một vài toán tử số học (+, -, *, /) và toán tử logic (==, !=, <, <=, >, >=) chúng ta đã biết.
- Parentheses. Cặp ngoặc
(và)nhóm biểu thức với nhau.
Điều này giúp cung cấp cho chúng ta đủ cú pháp cho các biểu thức như:
1 - (2 * 3) < 4 == false
Bộ quy tắc đầy đủ sẽ như sau:
expression => literal
| unary
| binary
| grouping ;
literal => số | chuỗi | "đúng" | "sai" | "rỗng" ;
grouping => "(" expression ")" ;
unary => ( "-" | "!" ) expression ;
binary => expression operator expression ;
operator => "==" | "!=" | "<" | "<=" | ">" | ">="
| "+" | "-" | "*" | "/" ;
Triển khai cây cú pháp của ViL
Ok, cuối cùng thì chúng ta cũng bắt đầu vào code. Bài trước chúng ta chỉ cần một lớp Token để gom hết các loại, và để phân biệt ví dụ như chuỗi "123" và số 123 khác nhau thì sử dụng thêm TokenType nữa. Mục tiêu của chúng ta là chuỗi Token => chuỗi Expression. Nhưng vì mỗi loại expression khác nhau như literal, grouping, unary và binary có các quy tắc khác nhau và khá phức tạp nên thay vì sử dụng một lớp chung như Token ta sẽ có một lớp trừu tượng Expression và kế thừa nó. Đây là ví dụ về Binary:
import 'package:vil/token.dart';
abstract class Expression {}
class Binary extends Expression {
final Expression left;
final Token operator;
final Expression right;
Binary(this.left, this.operator, this.right);
}
Trình gen-code tự động cho expression
Thay vì viết code từng loại expression một chúng ta sẽ viết một trình gen-code, điều này hơi mất thời gian lúc đầu như ở những chương sau với việc thêm các quy tắc mới và cùng đó cũng tạo ra thêm nhiều expression khác, gen-code là sự lựa chọn tốt hơn. Để tạo một trình gen code trong dart có hai phần chính.
- Annotations. Bản hướng dẫn sẽ tạo ra dữ liệu như thế nào.
- Generators. Trình tạo mã.
Ok, hãy tạo hai folder cho từng phần, và các file chúng ta sẽ chuẩn bị triển khai, như hình sau:
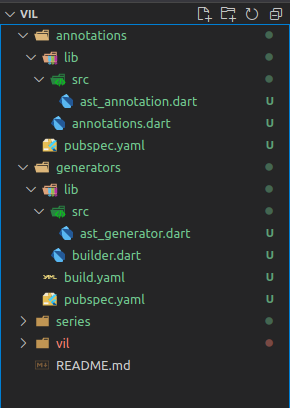
Annotations
Trong file annotations/pubspec.yaml, khai báo tên project và version của Dart SDK:
name: annotations
environment:
sdk: ">=2.14.0 <3.0.0"
Đừng quên nhấn Ctrl + S nếu bạn sử dụng VSCode hoặc vào terminal nhập lệnh để update lại dependencies của project nhé. (Lưu ý: Cần mở terminal ở trong thư mục annotations để có thể update lại project đó)
dart pub get
Ở đây file ast_annotation.dart sẽ như sau:
class Ast {
final List<String> rawASTList;
const Ast(this.rawASTList);
}
Export file annotation vừa rồi ra file annotations.dart:
library annotations;
export 'src/ast_annotation.dart';
Vậy là đã xong phần annotations. Bây giờ quay lại project chính vil và import package annotations vào dependencies tại file vil/pubspec.yaml và save lại để update dependencies:
name: vil
environment:
sdk: ">=2.14.0 <3.0.0"
dependencies:
annotations:
path: "../annotations"
Lên bản vẽ cho Expression bằng ast_annotations
Source vil/lib/grammar/expression.dart
import 'package:annotations/annotations.dart';
part 'expression.g.dart';
@Ast([
"Binary : Expression left, Token operator, Expression right",
"Grouping : Expression expression",
"Literal : Object value",
"Unary : Token operator, Expression right"
])
class _Expression {}
Ở đây bạn có thể dùng một Map với key là tên của Expression và value chính là các biến thành phần nhưng để đỡ rối thì mình sẽ dùng chuỗi thô để trực quan quan sát hơn và phần xử lí bóc tách dữ liệu phần code gen sẽ đảm nhiệm.
Đừng để ý lỗi ở dòng part "expression.g.dart"; chút nữa chúng ta sẽ gen nó sau.
Generators
Chúng ta cần thêm các thư viện để gen code tại cuối file generators/pubspec.yaml và update lại dependencies:
...
dependencies:
build:
source_gen:
annotations:
path: "../annotations"
dev_dependencies:
build_test:
build_runner:
analyzer:
Vào file ast_generator.dart, tạo một Generator cho annotation Ast bên trên hay được ví như bác "công nhân" thực hiện bản thiết kế Ast:
import 'package:build/src/builder/build_step.dart';
import 'package:analyzer/dart/element/element.dart';
import 'package:source_gen/source_gen.dart';
import 'package:annotations/annotations.dart';
class AstGenerator extends GeneratorForAnnotation<Ast> {
generateForAnnotatedElement(
Element element, ConstantReader annotation, BuildStep buildStep) {}
}
Việc thứ nhất đó chính là tách dữ liệu từ AST của chúng ta, triển khai như sau:
...
generateForAnnotatedElement(
Element element, ConstantReader annotation, BuildStep buildStep) {
/// Tiền xử lí, lấy ra các tên của class
/// và lấy ra dữ liệu thô mà chúng ta nhập vào qua AST
/// Tên class cần gen
final baseClassName = element.displayName.substring(1);
/// Annotation nhập vào trong trường hợp này chắc chắn AST là annotation đầu tiên và duy nhất
/// nên ta lấy annotation đầu tiên
final ast = element.metadata.first;
/// Bóc ra dữ liệu thô của `rawASTList` list này trả về dạng List<DartObject>
final rawRawAstList =
ast.computeConstantValue()!.getField('rawASTList')!.toListValue()!;
/// Chuyển từ kiểu List<DartObject> => List<String> ban đầu
final rawAstList = rawRawAstList.map((e) => e.toStringValue()!).toList();
/// Tách thành hai mảng tên và biến riêng
List<String> astName = rawAstList.map((e) => e.split(":")[0].trim()).toList();
List<String> astArgument = rawAstList.map((e) => e.split(":")[1].trim()).toList();
}
...
Phương thức generateForAnnotatedElement trả về một chuỗi để ghi vào file. Ta có thể sử dụng kiểu String nhưng vì chuỗi của chúng ta là chuỗi dài nên mình chọn dùng StringBuffer:
Source: ast_generator.dart
generateForAnnotatedElement(
Element element, ConstantReader annotation, BuildStep buildStep) {
...
StringBuffer writer = StringBuffer();
}
Từ các dự liệu bên trên bóc tách ra và ghi lại trong StringBuffer writer:
Source: ast_generator.dart
generateForAnnotatedElement(
Element element, ConstantReader annotation, BuildStep buildStep) {
...
StringBuffer writer = StringBuffer();
writer.writeln('abstract class $baseClassName {}');
for (int i = 0; i < astName.length; i++) {
writer.writeln('class ${astName[i]} extends $baseClassName {');
List<String> argument =
astArgument[i].split(",").map((e) => e.trim()).toList();
for (int j = 0; j < argument.length; j++) {
writer.writeln('final ${argument[j]};');
}
final argumentName = argument.map((e) => e.split(" ")[1].trim()).toList();
writer.writeln('${astName[i]}(');
for (int j = 0; j < argumentName.length; j++) {
writer.writeln('this.${argumentName[j]},');
}
writer.writeln(');');
writer.writeln('}');
}
return writer.toString();
}
Trong file builder.dart tạo function để build_runner gọi khi gen code:
Source: builder.dart
import 'package:build/build.dart';
import 'package:source_gen/source_gen.dart';
import 'package:generators/src/ast_generator.dart';
Builder generateAst(BuilderOptions options) =>
// SharedPartBuilder là một builder được sử dụng để tạo ra một file cùng cấp với file chứa annotation
SharedPartBuilder([AstGenerator()], 'ast');
Ở file generators/build.yaml để cấu hình mục tiêu build code của chúng ta:
targets:
$default:
builders:
generators|annotations:
enabled: true
builders:
generators:
target: ":generators"
import: "package:generators/builder.dart"
builder_factories: ["generateAst"]
build_extensions: {".dart": [".g.dart"]}
auto_apply: dependents
build_to: cache
applies_builders: ["source_gen|combining_builder"]
Gen expression
Trong file vil/pubspec.yaml bổ sung generators và build_runner vào dev_dependencies, nhớ update lại dependencies nhé:
...
dev_dependencies:
build_runner:
generators:
path: "../generators"
Mở terminal trong folder vil chạy lệnh:
dart run build_runner build --delete-conflicting-outputs
Sau khoảng 5-10s file expression.g.dart sẽ được tạo ra. Nếu thực hiện đúng các bước bạn sẽ được file như này:
// GENERATED CODE - DO NOT MODIFY BY HAND
part of 'expression.dart';
// **************************************************************************
// AstGenerator
// **************************************************************************
abstract class Expression {}
class Binary extends Expression {
final Expression left;
final Token operator;
final Expression right;
Binary(
this.left,
this.operator,
this.right,
);
}
class Grouping extends Expression {
final Expression expression;
Grouping(
this.expression,
);
}
class Literal extends Expression {
final dynamic value;
Literal(
this.value,
);
}
class Unary extends Expression {
final Token operator;
final Expression right;
Unary(
this.operator,
this.right,
);
}
Tổng kết
Qua bài này, chúng ta đã biết và nắm được khái niệm Context-free Grammar và định nghĩa được cú pháp cơ bản của ngôn ngữ ViL. Ở P2, chúng ta sẽ làm việc với đống quy tắc vừa tạo. Chào các bạn, mình viết muốn rụng cái tay luôn rồi @@
Mã nguồn
Bạn có thể theo dõi mã nguồn từng bài viết tại đây. Đừng ngại để lại cho mình một sao nhé 😍


