Một số công việc cơ bản sẽ làm:
PRINT:
- [X] NUMBERS
- [X] STRINGS
- [X] EXPRESSION
VARIABLES:
- [X] ASIGNING VARIABLES
- [X] ASIGNING VARIABLES TO OTHER VARIABLES
- [X] COMMENT:
~~~ ~~~,#
Giới thiệu
Phân tích cú pháp (tiếng Anh: parsing, syntax analysis, hoặc syntactic analysis) là một quá trình phân tích một chuỗi các biểu tượng, sử dụng trong ngôn ngữ tự nhiên, ngôn ngữ máy tính và các cấu trúc dữ liệu, tuân theo các quy tắc của ngữ pháp hình thức (formal grammar). Xây dựng cây phân tích cú pháp là 1 trong những giai đoạn đầu của việc thiết kế trình biên dịch.
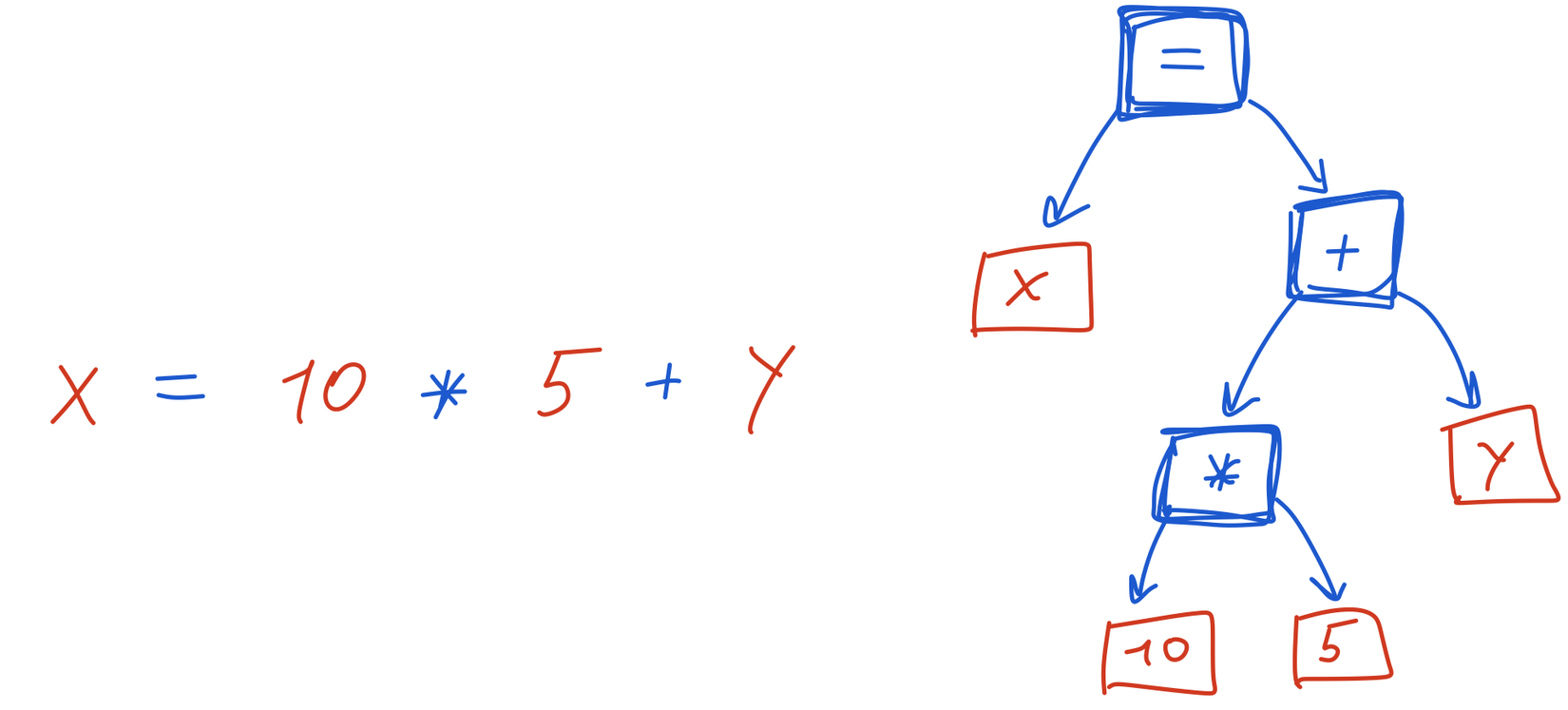
Cú pháp cơ bản
Tên biến
Tên biến bắt đầu bằng kí tự $ và theo sau đó có thể là các kí tự số và chữ cái từ a đến z
VD:
$variable = "VIETNAM IS THE MOST BEAUTIFUL IN MY HEART"
$var6 = 10000 * 10000
$var66 = $var6
Chú thích
Sử dụng kí tự # hoặc ~~~ ~~~ để chú thích chỉ thị trình biên dịch bỏ qua không phân tích cú pháp
Lệnh gán
$var1 = "Hau Trung Nguyen"
$var2 = "Hung Trung Nguyen"
$var3 = "Quoc Trung Nguyen"
$var4 = "Viet Trung Nguyen"
$var5 = 612
$var6 = 10000 * 10000
Lệnh PRINT
Lệnh này được dùng để in giá trị của biến, của biểu thức (số và chuỗi ký tự) ra tập tin, màn hình, máy in...
PRINT 123456 + 233333 - 12366999999999999999999999
PRINT "I LOVE YOU"
Lệnh IF
IF điều_kiện THEN
câu_lệnh
ELSE
câu_lệnh
END IF
LỆNH FOR
FOR biến = giá_trị_đầu TO giá_trị_cuối [STEP bước_nhảy]
câu_lệnh
NEXT biến
LỆNH WHILE
while (expression)
{
statements;
}
Vòng lặp while được định nghĩa bởi từ khóa while. Một khi vòng lặp while được thực thi, biểu thức điều kiện trong while sẽ được đánh giá. Nếu biểu thức điều kiện cho giá trị đúng, các câu lệnh trong khối lệnh của vòng lặp while sẽ được thực thi.
LỆNH BREAK VÀ CONTINUE
Trong vòng lặp, lệnh break và continue khi xuất hiện thì sẽ được bao bọc bởi một khối lệnh if, bởi vì nếu không có lệnh if bao bọc thì vòng lặp sẽ trở nên vô dụng.
Một vòng lặp đang thực hiện nếu gặp lệnh break sẽ thoát vòng lặp ngay lập tức. Xem sơ đồ mô tả luồng hoạt động của vòng lặp khi có lệnh break dưới đây:

Còn nếu một vòng lặp đang chạy mà gặp lệnh continue, tất cả các lệnh trong thân vòng lặp nằm phía dưới lệnh continue sẽ bị bỏ qua ở lần lặp hiện tại. Vòng lặp sẽ chuyển sang kiểm tra điều kiện và tiếp tục lặp (nếu điều kiện lặp còn thỏa mãn).

Viết code

Trước khi phân tích ngữ nghĩa của code, thì trình biên dịch phải nhận dạng kí tự trong file
def open_file(filename):
data = open(filename, "r").read()
data += "<EOF>"
return data
Kí tự <EOF> (end of file) biểu thị cho điều kiện trong hệ điều hành máy tính mà không có thêm dữ liệu nào có thể được đọc từ một nguồn dữ liệu.
Khi xây dựng mọi parser của mọi ngôn ngữ lập trình đều phải chuyển về dạng mảng để xử lý chuỗi.
filecontents = list(filecontents)
Trong python hàm list(data) có tác dụng chuyển đổi data của một biến sang dạng list. VD:
string = "Nguyễn Trung Hậu"
print(list(string))
tup = ('Nguyễn', 'Trung', 'Hậu')
print(list(tup))
Kết quả:
['N', 'g', 'u', 'y', 'ễ', 'n', ' ', 'T', 'r', 'u', 'n', 'g', ' ', 'H', 'ậ', 'u']
['Nguyễn', 'Trung', 'Hậu']
Sau khi đã chuyển tất cả các kí tự trong file về dạng mảng thì tiếp theo ta xây dựng trình phân tích từ vựng.
Các nhiệm vụ của quá trình phân tích từ vựng gồm:
- Đọc các ký tự đầu vào
- Phát sinh các chuỗi dấu hiệu đầu ra
- Bỏ khoảng trắng, cách dòng, tab
- Ghi lại vị trí các dấu hiệu được dùng cho bước xử lý tiếp theo.
def lex(filecontents):
index = 0
tokens = []
tok = ""
state = 0
isexpr = 0
varStarted = 0
var = ""
string = ""
expr = ""
filecontents = list(filecontents)
filestring = ''.join(filecontents)
for char in filecontents:
tok += char
if tok == "###":
tokens.append("###")
tok = ""
elif tok == "```":
tokens.append("```")
tok = ""
elif tok == "``\n":
tokens.append("``")
tok = ""
elif tok == " ":
if state == 0:
tok = ""
else:
tok = " "
elif tok == "\n" or tok == "<EOF>":
if expr != "" and isexpr == 1:
tokens.append("EXPR: " + expr)
expr = ""
elif expr != "" and isexpr == 0:
tokens.append("NUMBER: " + expr)
expr = ""
elif var != "":
tokens.append("VAR: " + var)
var = ""
varStarted = 0
tok = ""
elif tok == "=" and state == 0:
if var != "":
tokens.append("VAR: " + var)
var = ""
varStarted = 0
tokens.append("EQUALS")
tok = ""
elif tok == "$" and state == 0:
varStarted = 1
var += tok
tok = ""
elif varStarted == 1:
if tok == "<" or tok == ">":
if var != "":
tokens.append("VAR: " + var)
var = ""
varStarted = 0 #
var += tok
tok = ""
elif tok == "PRINT" or tok == "print":
tokens.append("PRINT")
tok = ""
elif tok == "0" or tok == "1" or tok == "2" or tok == "3" or tok == "4" or tok == "5" or tok == "6" or tok == "7" or tok == "8" or tok == "9":
expr += tok
tok = ""
elif tok == "+" or tok == "-" or tok == "*" or tok == "/" or tok == "%" or tok == "." or tok == "(" or tok == ")":
isexpr = 1
expr += tok
tok = ""
elif tok == '\"':
if state == 0:
state = 1
elif state == 1:
tokens.append("STRING: " + string + "\"")
string = ""
state = 0
tok = ""
elif state == 1:
string += tok
tok = ""
return tokens
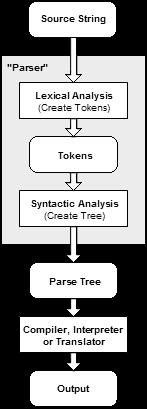
Sau khi đã xử lý dãy dữ liệu mảng chuỗi được đọc trong file code thành 1 mảng các kí hiệu được biên dịch trong trình biên dịch Python thành dữ liệu có thể đọc được bởi con người để hiển thị ra màn hình thì ta thêm đoạn code xây dựng trình phân tích cú pháp. Nó là một trình biên dịch hoặc thông dịch các thành phần code sang ngôn ngữ khác. Trình phân tích cú pháp xây dựng cấu trúc dữ liệu dựa trên các mã token của lexer. Cấu trúc dữ liệu này sau đó có thể được sử dụng bởi trình biên dịch, trình thông dịch hoặc trình dịch để tạo một chương trình hoặc thư viện thực thi.
def parse(toks):
i = 0
index_comment = 0
comment = all_indices("``", toks)
while (i < len(toks)):
if toks[i] == "``":
i += 1
elif toks[i] + " " + toks[i + 1][0:6] == "PRINT STRING" or toks[i] + " " + toks[i + 1][0:6] == "PRINT NUMBER" or toks[i] + " " + toks[i + 1][0:4] == "PRINT EXPR" or toks[i] + " " + toks[i + 1][0:3] == "PRINT VAR":
if toks [i + 1][0:6] == "STRING":
doPrint(toks[i + 1])
elif toks[i + 1][0:6] == "NUMBER":
doPrint(toks[i + 1])
elif toks[i + 1][0:4] == "EXPR":
doPrint(toks[i + 1])
elif toks[i + 1][0:3] == "VAR":
doPrint(getVariable(toks[i + 1]))
i += 2
elif toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:6] == "VAR EQUALS STRING" or toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:6] == "VAR EQUALS NUMBER" or toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:4] == "VAR EQUALS EXPR" or toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:3] == "VAR EQUALS VAR":
if toks[i + 2][0:6] == "STRING":
doAssignVariable(toks[i], toks[i + 2])
elif toks[i + 2][0:6] == "NUMBER":
doAssignVariable(toks[i], toks[i + 2])
elif toks[i + 2][0:4] == "EXPR":
doAssignVariable(toks[i], "NUMBER: " + str(evalExpression(toks[i + 2][5:])))
elif toks[i + 2][0:3] == "VAR":
doAssignVariable(toks[i], getVariable(toks[i + 2]))
i += 3
elif toks[i] == "```":
i = comment[index_comment]
index_comment += 1
Để in các chuỗi, số, và kết quả của biểu thức thì có thể dùng hàm doPrint(tokens)
def doPrint(_print):
if (_print[0:6] == "STRING"):
_print = _print[8:]
_print = _print[:-1]
elif (_print[0:6] == "NUMBER"):
_print = _print[7:]
elif (_print[0:4] == "EXPR"):
_print = evalExpression(_print[5:])
print(_print)
Để in kết quả của một biến dữ liệu $variable thì có thể dùng hàm getVariable(tokens) để lấy dữ liệu của biến và in dữ liệu với hàm doPrint(getVariable(tokens))
def getVariable(varName):
varName = varName[4:]
if varName in symbols:
return symbols[varName]
else:
return "Error 1080: Undefined Variable from " + varName
exit(0)
Để gán giá trị của một biến dữ liệu hoặc biểu thức này cho một biến dữ liệu khác thì có thể dùng hàm doAssignVariable(tokens1, tokens2)
def doAssignVariable(varName, varValue):
symbols[varName[4:]] = varValue
Để hiểu hơn thì ta có thể đọc full source code đơn giản của lexer và parser:
from sys import *
import re
symbols = {}
def open_file(filename):
data = open(filename, "r").read()
data += "<EOF>"
return data
def find_between(_from, _to, _string):
try:
start = _string.index(_from) + len(_from)
end = _string.index(_to, start)
return _string[start:end]
except ValueError:
return ""
def lex(filecontents):
index = 0
tokens = []
tok = ""
state = 0
isexpr = 0
varStarted = 0
var = ""
string = ""
expr = ""
filecontents = list(filecontents)
filestring = ''.join(filecontents)
for char in filecontents:
tok += char
if tok == "###":
tokens.append("###")
tok = ""
elif tok == "```":
tokens.append("```")
tok = ""
elif tok == "``\n": # When go to ``\n
tokens.append("``")
tok = ""
elif tok == " ":
if state == 0:
tok = ""
else:
tok = " "
elif tok == "\n" or tok == "<EOF>":
if expr != "" and isexpr == 1:
tokens.append("EXPR: " + expr)
expr = ""
elif expr != "" and isexpr == 0:
tokens.append("NUMBER: " + expr)
expr = ""
elif var != "":
tokens.append("VAR: " + var)
var = ""
varStarted = 0
tok = ""
elif tok == "=" and state == 0:
if var != "":
tokens.append("VAR: " + var)
var = ""
varStarted = 0
tokens.append("EQUALS")
tok = ""
elif tok == "$" and state == 0:
varStarted = 1
var += tok
tok = ""
elif varStarted == 1:
if tok == "<" or tok == ">":
if var != "":
tokens.append("VAR: " + var)
var = ""
varStarted = 0 #
var += tok
tok = ""
elif tok == "PRINT" or tok == "print":
tokens.append("PRINT")
tok = ""
elif tok == "0" or tok == "1" or tok == "2" or tok == "3" or tok == "4" or tok == "5" or tok == "6" or tok == "7" or tok == "8" or tok == "9":
expr += tok
tok = ""
elif tok == "+" or tok == "-" or tok == "*" or tok == "/" or tok == "%" or tok == "." or tok == "(" or tok == ")":
isexpr = 1
expr += tok
tok = ""
elif tok == '\"':
if state == 0:
state = 1
elif state == 1:
tokens.append("STRING: " + string + "\"")
string = ""
state = 0
tok = ""
elif state == 1:
string += tok
tok = ""
return tokens
def evalExpression(expr):
return eval(expr)
def doPrint(_print):
if (_print[0:6] == "STRING"):
_print = _print[8:]
_print = _print[:-1]
elif (_print[0:6] == "NUMBER"):
_print = _print[7:]
elif (_print[0:4] == "EXPR"):
_print = evalExpression(_print[5:])
print(_print)
def doAssignVariable(varName, varValue):
symbols[varName[4:]] = varValue
def getVariable(varName):
varName = varName[4:]
if varName in symbols:
return symbols[varName]
else:
return "Error 1080: Undefined Variable from " + varName
exit(0)
def parse(toks):
i = 0
index_comment = 0
comment = all_indices("``", toks)
while (i < len(toks)):
if toks[i] == "``":
i += 1
elif toks[i] + " " + toks[i + 1][0:6] == "PRINT STRING" or toks[i] + " " + toks[i + 1][0:6] == "PRINT NUMBER" or toks[i] + " " + toks[i + 1][0:4] == "PRINT EXPR" or toks[i] + " " + toks[i + 1][0:3] == "PRINT VAR":
if toks [i + 1][0:6] == "STRING":
doPrint(toks[i + 1])
elif toks[i + 1][0:6] == "NUMBER":
doPrint(toks[i + 1])
elif toks[i + 1][0:4] == "EXPR":
doPrint(toks[i + 1])
elif toks[i + 1][0:3] == "VAR":
doPrint(getVariable(toks[i + 1]))
i += 2
elif toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:6] == "VAR EQUALS STRING" or toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:6] == "VAR EQUALS NUMBER" or toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:4] == "VAR EQUALS EXPR" or toks[i][0:3] + " " + toks[i + 1] + " " + toks[i + 2][0:3] == "VAR EQUALS VAR":
if toks[i + 2][0:6] == "STRING":
doAssignVariable(toks[i], toks[i + 2])
elif toks[i + 2][0:6] == "NUMBER":
doAssignVariable(toks[i], toks[i + 2])
elif toks[i + 2][0:4] == "EXPR":
doAssignVariable(toks[i], "NUMBER: " + str(evalExpression(toks[i + 2][5:])))
elif toks[i + 2][0:3] == "VAR":
doAssignVariable(toks[i], getVariable(toks[i + 2]))
i += 3
elif toks[i] == "```":
i = comment[index_comment]
index_comment += 1
def run():
data = open_file(argv[1])
toks = lex(data)
parse(toks)
run()